 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenArena: How Can We Achieve Human-Aligned Evaluation for Visual Generation Tasks?
Feb 05, 2026The rapid advancement of visual generation models has outpaced traditional evaluation approaches, necessitating the adoption of Vision-Language Models as surrogate judges. In this work, we systematically investigate the reliability of the prevailing absolute pointwise scoring standard, across a wide spectrum of visual generation tasks. Our analysis reveals that this paradigm is limited due to stochastic inconsistency and poor alignment with human perception. To resolve these limitations, we introduce GenArena, a unified evaluation framework that leverages a pairwise comparison paradigm to ensure stable and human-aligned evaluation. Crucially, our experiments uncover a transformative finding that simply adopting this pairwise protocol enables off-the-shelf open-source models to outperform top-tier proprietary models. Notably, our method boosts evaluation accuracy by over 20% and achieves a Spearman correlation of 0.86 with the authoritative LMArena leaderboard, drastically surpassing the 0.36 correlation of pointwise methods. Based on GenArena, we benchmark state-of-the-art visual generation models across diverse tasks, providing the community with a rigorous and automated evaluation standard for visual generation.
X-Omni: Reinforcement Learning Makes Discrete Autoregressive Image Generative Models Great Again
Jul 29, 2025Numerous efforts have been made to extend the ``next token prediction'' paradigm to visual contents, aiming to create a unified approach for both image generation and understanding. Nevertheless, attempts to generate images through autoregressive modeling with discrete tokens have been plagued by issues such as low visual fidelity, distorted outputs, and failure to adhere to complex instructions when rendering intricate details. These shortcomings are likely attributed to cumulative errors during autoregressive inference or information loss incurred during the discretization process. Probably due to this challenge, recent research has increasingly shifted toward jointly training image generation with diffusion objectives and language generation with autoregressive objectives, moving away from unified modeling approaches. In this work, we demonstrate that reinforcement learning can effectively mitigate artifacts and largely enhance the generation quality of a discrete autoregressive modeling method, thereby enabling seamless integration of image and language generation. Our framework comprises a semantic image tokenizer, a unified autoregressive model for both language and images, and an offline diffusion decoder for image generation, termed X-Omni. X-Omni achieves state-of-the-art performance in image generation tasks using a 7B language model, producing images with high aesthetic quality while exhibiting strong capabilities in following instructions and rendering long texts.
ReDDiT: Rehashing Noise for Discrete Visual Generation
May 26, 2025Discrete diffusion models are gaining traction in the visual generative area for their efficiency and compatibility. However, the pioneered attempts still fall behind the continuous counterparts, which we attribute to the noise (absorbing state) design and sampling heuristics. In this study, we propose the rehashing noise framework for discrete diffusion transformer, termed ReDDiT, to extend absorbing states and improve expressive capacity of discrete diffusion models. ReDDiT enriches the potential paths that latent variables can traverse during training with randomized multi-index corruption. The derived rehash sampler, which reverses the randomized absorbing paths, guarantees the diversity and low discrepancy of the generation process. These reformulations lead to more consistent and competitive generation quality, mitigating the need for heavily tuned randomness. Experiments show that ReDDiT significantly outperforms the baseline (reducing gFID from 6.18 to 1.61) and is on par with the continuous counterparts with higher efficiency.
Emu3: Next-Token Prediction is All You Need
Sep 27, 2024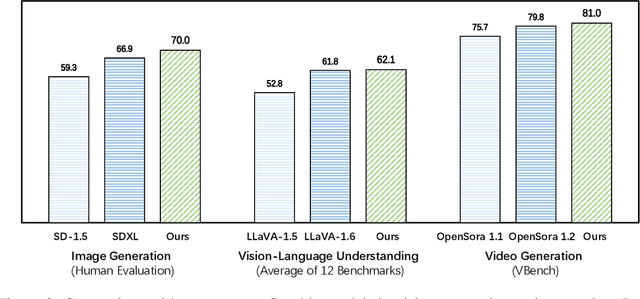


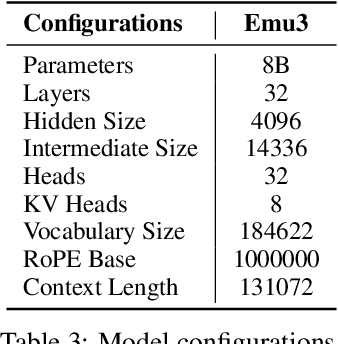
While next-token prediction is considered a promising path towards artificial general intelligence, it has struggled to excel in multimodal tasks, which are still dominated by diffusion models (e.g., Stable Diffusion) and compositional approaches (e.g., CLIP combined with LLMs). In this paper, we introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction. By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences. Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures. Emu3 is also capable of generating high-fidelity video via predicting the next token in a video sequence. We simplify complex multimodal model designs by converging on a singular focus: tokens, unlocking great potential for scaling both during training and inference. Our results demonstrate that next-token prediction is a promising path towards building general multimodal intelligence beyond language. We open-source key techniques and models to support further research in this direction.
Correspondence-Guided SfM-Free 3D Gaussian Splatting for NVS
Aug 16, 2024Novel View Synthesis (NVS) without Structure-from-Motion (SfM) pre-processed camera poses--referred to as SfM-free methods--is crucial for promoting rapid response capabilities and enhancing robustness against variable operating conditions. Recent SfM-free methods have integrated pose optimization, designing end-to-end frameworks for joint camera pose estimation and NVS. However, most existing works rely on per-pixel image loss functions, such as L2 loss. In SfM-free methods, inaccurate initial poses lead to misalignment issue, which, under the constraints of per-pixel image loss functions, results in excessive gradients, causing unstable optimization and poor convergence for NVS. In this study, we propose a correspondence-guided SfM-free 3D Gaussian splatting for NVS. We use correspondences between the target and the rendered result to achieve better pixel alignment, facilitating the optimization of relative poses between frames. We then apply the learned poses to optimize the entire scene. Each 2D screen-space pixel is associated with its corresponding 3D Gaussians through approximated surface rendering to facilitate gradient back propagation. Experimental results underline the superior performance and time efficiency of the proposed approach compared to the state-of-the-art baselines.
Do As I Do: Pose Guided Human Motion Copy
Jun 24, 2024



Human motion copy is an intriguing yet challenging task in artificial intelligence and computer vision, which strives to generate a fake video of a target person performing the motion of a source person. The problem is inherently challenging due to the subtle human-body texture details to be generated and the temporal consistency to be considered. Existing approaches typically adopt a conventional GAN with an L1 or L2 loss to produce the target fake video, which intrinsically necessitates a large number of training samples that are challenging to acquire. Meanwhile, current methods still have difficulties in attaining realistic image details and temporal consistency, which unfortunately can be easily perceived by human observers. Motivated by this, we try to tackle the issues from three aspects: (1) We constrain pose-to-appearance generation with a perceptual loss and a theoretically motivated Gromov-Wasserstein loss to bridge the gap between pose and appearance. (2) We present an episodic memory module in the pose-to-appearance generation to propel continuous learning that helps the model learn from its past poor generations. We also utilize geometrical cues of the face to optimize facial details and refine each key body part with a dedicated local GAN. (3) We advocate generating the foreground in a sequence-to-sequence manner rather than a single-frame manner, explicitly enforcing temporal inconsistency. Empirical results on five datasets, iPER, ComplexMotion, SoloDance, Fish, and Mouse datasets, demonstrate that our method is capable of generating realistic target videos while precisely copying motion from a source video. Our method significantly outperforms state-of-the-art approaches and gains 7.2% and 12.4% improvements in PSNR and FID respectively.
EVA-CLIP-18B: Scaling CLIP to 18 Billion Parameters
Feb 06, 2024



Scaling up contrastive language-image pretraining (CLIP) is critical for empowering both vision and multimodal models. We present EVA-CLIP-18B, the largest and most powerful open-source CLIP model to date, with 18-billion parameters. With only 6-billion training samples seen, EVA-CLIP-18B achieves an exceptional 80.7% zero-shot top-1 accuracy averaged across 27 widely recognized image classification benchmarks, outperforming its forerunner EVA-CLIP (5-billion parameters) and other open-source CLIP models by a large margin. Remarkably, we observe a consistent performance improvement with the model size scaling of EVA-CLIP, despite maintaining a constant training dataset of 2-billion image-text pairs from LAION-2B and COYO-700M. This dataset is openly available and much smaller than the in-house datasets (e.g., DFN-5B, WebLI-10B) employed in other state-of-the-art CLIP models. EVA-CLIP-18B demonstrates the potential of EVA-style weak-to-strong visual model scaling. With our model weights made publicly available, we hope to facilitate future research in vision and multimodal foundation models.
Generative Multimodal Models are In-Context Learners
Dec 20, 2023The human ability to easily solve multimodal tasks in context (i.e., with only a few demonstrations or simple instructions), is what current multimodal systems have largely struggled to imitate. In this work, we demonstrate that the task-agnostic in-context learning capabilities of large multimodal models can be significantly enhanced by effective scaling-up. We introduce Emu2, a generative multimodal model with 37 billion parameters, trained on large-scale multimodal sequences with a unified autoregressive objective. Emu2 exhibits strong multimodal in-context learning abilities, even emerging to solve tasks that require on-the-fly reasoning, such as visual prompting and object-grounded generation. The model sets a new record on multiple multimodal understanding tasks in few-shot settings. When instruction-tuned to follow specific instructions, Emu2 further achieves new state-of-the-art on challenging tasks such as question answering benchmarks for large multimodal models and open-ended subject-driven generation. These achievements demonstrate that Emu2 can serve as a base model and general-purpose interface for a wide range of multimodal tasks. Code and models are publicly available to facilitate future research.
CapsFusion: Rethinking Image-Text Data at Scale
Nov 02, 2023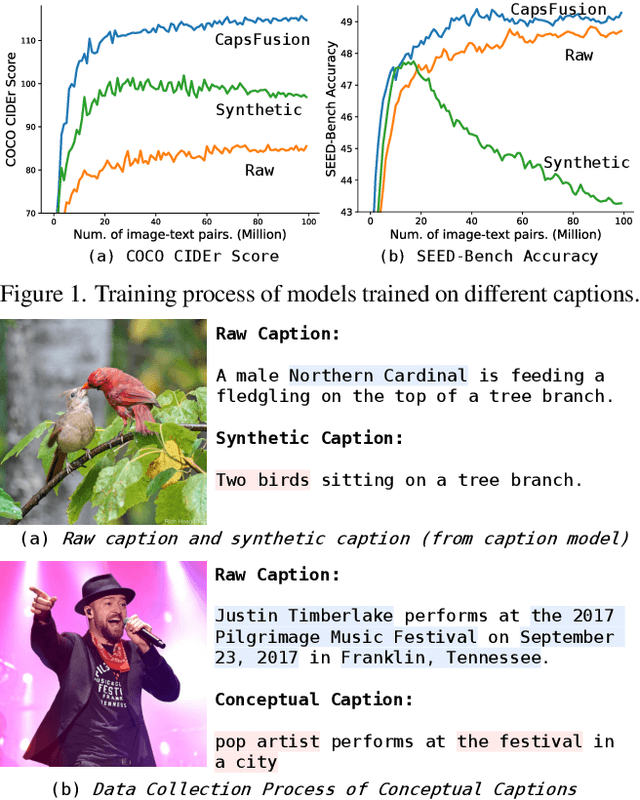
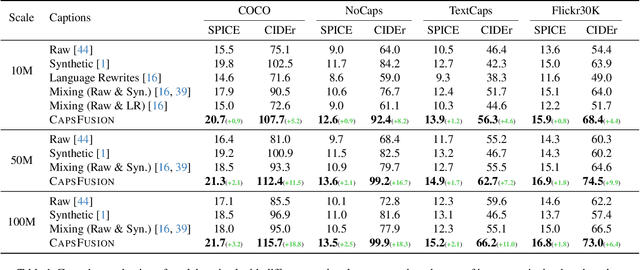


Large multimodal models demonstrate remarkable generalist ability to perform diverse multimodal tasks in a zero-shot manner. Large-scale web-based image-text pairs contribute fundamentally to this success, but suffer from excessive noise. Recent studies use alternative captions synthesized by captioning models and have achieved notable benchmark performance. However, our experiments reveal significant Scalability Deficiency and World Knowledge Loss issues in models trained with synthetic captions, which have been largely obscured by their initial benchmark success. Upon closer examination, we identify the root cause as the overly-simplified language structure and lack of knowledge details in existing synthetic captions. To provide higher-quality and more scalable multimodal pretraining data, we propose CapsFusion, an advanced framework that leverages large language models to consolidate and refine information from both web-based image-text pairs and synthetic captions. Extensive experiments show that CapsFusion captions exhibit remarkable all-round superiority over existing captions in terms of model performance (e.g., 18.8 and 18.3 improvements in CIDEr score on COCO and NoCaps), sample efficiency (requiring 11-16 times less computation than baselines), world knowledge depth, and scalability. These effectiveness, efficiency and scalability advantages position CapsFusion as a promising candidate for future scaling of LMM training.
Generative Pretraining in Multimodality
Jul 11, 2023We present Emu, a Transformer-based multimodal foundation model, which can seamlessly generate images and texts in multimodal context. This omnivore model can take in any single-modality or multimodal data input indiscriminately (e.g., interleaved image, text and video) through a one-model-for-all autoregressive training process. First, visual signals are encoded into embeddings, and together with text tokens form an interleaved input sequence. Emu is then end-to-end trained with a unified objective of classifying the next text token or regressing the next visual embedding in the multimodal sequence. This versatile multimodality empowers the exploration of diverse pretraining data sources at scale, such as videos with interleaved frames and text, webpages with interleaved images and text, as well as web-scale image-text pairs and video-text pairs. Emu can serve as a generalist multimodal interface for both image-to-text and text-to-image tasks, and supports in-context image and text generation. Across a broad range of zero-shot/few-shot tasks including image captioning, visual question answering, video question answering and text-to-image generation, Emu demonstrates superb performance compared to state-of-the-art large multimodal models. Extended capabilities such as multimodal assistants via instruction tuning are also demonstrated with impressive performance.