 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models
Jan 28, 2026We introduce WorldVQA, a benchmark designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike current evaluations, which often conflate visual knowledge retrieval with reasoning, WorldVQA decouples these capabilities to strictly measure "what the model memorizes." The benchmark assesses the atomic capability of grounding and naming visual entities across a stratified taxonomy, spanning from common head-class objects to long-tail rarities. We expect WorldVQA to serve as a rigorous test for visual factuality, thereby establishing a standard for assessing the encyclopedic breadth and hallucination rates of current and next-generation frontier models.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
FipTR: A Simple yet Effective Transformer Framework for Future Instance Prediction in Autonomous Driving
Apr 19, 2024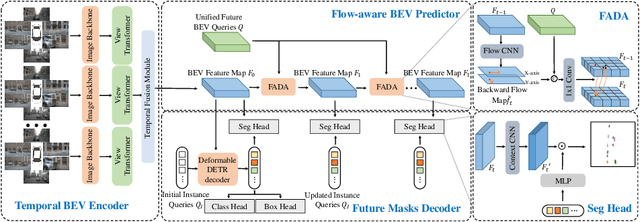
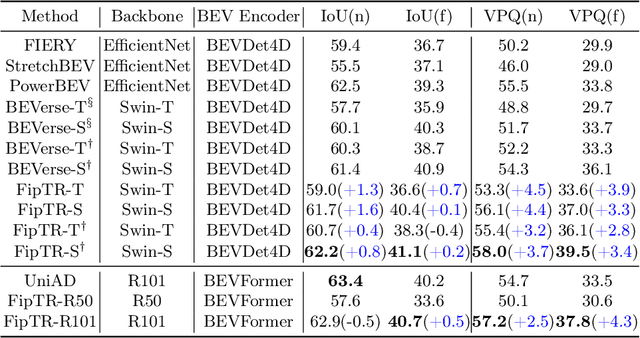
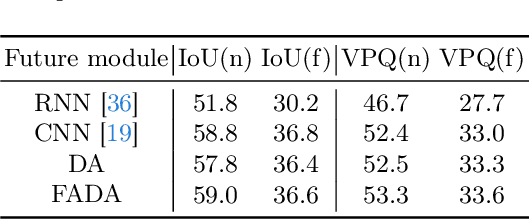

The future instance prediction from a Bird's Eye View(BEV) perspective is a vital component in autonomous driving, which involves future instance segmentation and instance motion prediction. Existing methods usually rely on a redundant and complex pipeline which requires multiple auxiliary outputs and post-processing procedures. Moreover, estimated errors on each of the auxiliary predictions will lead to degradation of the prediction performance. In this paper, we propose a simple yet effective fully end-to-end framework named Future Instance Prediction Transformer(FipTR), which views the task as BEV instance segmentation and prediction for future frames. We propose to adopt instance queries representing specific traffic participants to directly estimate the corresponding future occupied masks, and thus get rid of complex post-processing procedures. Besides, we devise a flow-aware BEV predictor for future BEV feature prediction composed of a flow-aware deformable attention that takes backward flow guiding the offset sampling. A novel future instance matching strategy is also proposed to further improve the temporal coherence. Extensive experiments demonstrate the superiority of FipTR and its effectiveness under different temporal BEV encoders.
SparseAD: Sparse Query-Centric Paradigm for Efficient End-to-End Autonomous Driving
Apr 10, 2024



End-to-End paradigms use a unified framework to implement multi-tasks in an autonomous driving system. Despite simplicity and clarity, the performance of end-to-end autonomous driving methods on sub-tasks is still far behind the single-task methods. Meanwhile, the widely used dense BEV features in previous end-to-end methods make it costly to extend to more modalities or tasks. In this paper, we propose a Sparse query-centric paradigm for end-to-end Autonomous Driving (SparseAD), where the sparse queries completely represent the whole driving scenario across space, time and tasks without any dense BEV representation. Concretely, we design a unified sparse architecture for perception tasks including detection, tracking, and online mapping. Moreover, we revisit motion prediction and planning, and devise a more justifiable motion planner framework. On the challenging nuScenes dataset, SparseAD achieves SOTA full-task performance among end-to-end methods and significantly narrows the performance gap between end-to-end paradigms and single-task methods. Codes will be released soon.
BEAM: Beta Distribution Ray Denoising for Multi-view 3D Object Detection
Feb 06, 2024



Multi-view 3D object detectors struggle with duplicate predictions due to the lack of depth information, resulting in false positive detections. In this study, we introduce BEAM, a novel Beta Distribution Ray Denoising approach that can be applied to any DETR-style multi-view 3D detector to explicitly incorporate structure prior knowledge of the scene. By generating rays from cameras to objects and sampling spatial denoising queries from the Beta distribution family along these rays, BEAM enhances the model's ability to distinguish spatial hard negative samples arising from ambiguous depths. BEAM is a plug-and-play technique that adds only marginal computational costs during training, while impressively preserving the inference speed. Extensive experiments and ablation studies on the NuScenes dataset demonstrate significant improvements over strong baselines, outperforming the state-of-the-art method StreamPETR by 1.9% mAP. The code will be available at https://github.com/LiewFeng/BEAM.
Multi-Centroid Representation Network for Domain Adaptive Person Re-ID
Dec 22, 2021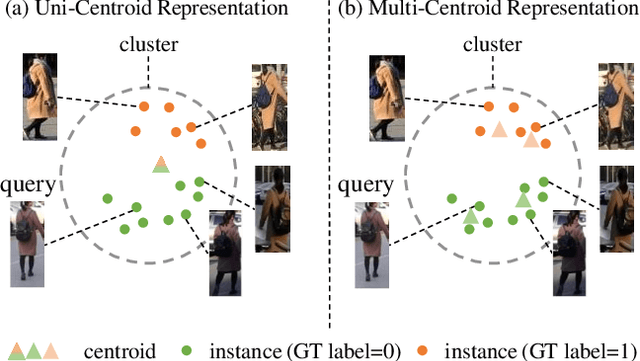
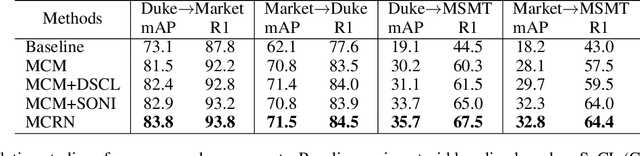
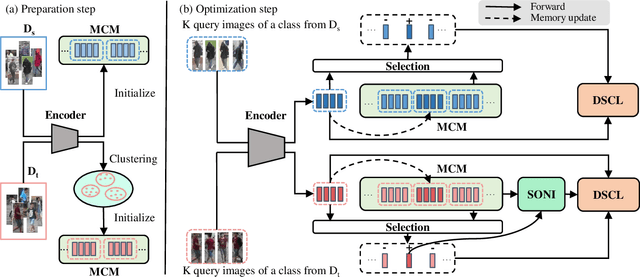
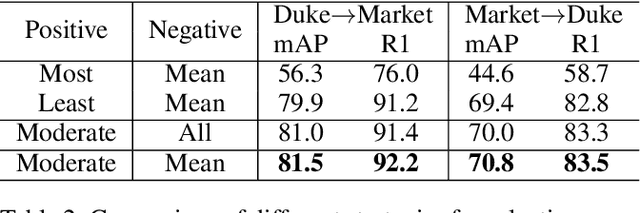
Recently, many approaches tackle the Unsupervised Domain Adaptive person re-identification (UDA re-ID) problem through pseudo-label-based contrastive learning. During training, a uni-centroid representation is obtained by simply averaging all the instance features from a cluster with the same pseudo label. However, a cluster may contain images with different identities (label noises) due to the imperfect clustering results, which makes the uni-centroid representation inappropriate. In this paper, we present a novel Multi-Centroid Memory (MCM) to adaptively capture different identity information within the cluster. MCM can effectively alleviate the issue of label noises by selecting proper positive/negative centroids for the query image. Moreover, we further propose two strategies to improve the contrastive learning process. First, we present a Domain-Specific Contrastive Learning (DSCL) mechanism to fully explore intradomain information by comparing samples only from the same domain. Second, we propose Second-Order Nearest Interpolation (SONI) to obtain abundant and informative negative samples. We integrate MCM, DSCL, and SONI into a unified framework named Multi-Centroid Representation Network (MCRN). Extensive experiments demonstrate the superiority of MCRN over state-of-the-art approaches on multiple UDA re-ID tasks and fully unsupervised re-ID tasks.
Spatial Ensemble: a Novel Model Smoothing Mechanism for Student-Teacher Framework
Oct 04, 2021


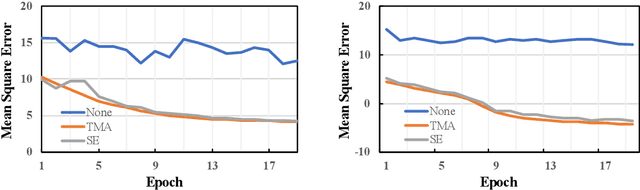
Model smoothing is of central importance for obtaining a reliable teacher model in the student-teacher framework, where the teacher generates surrogate supervision signals to train the student. A popular model smoothing method is the Temporal Moving Average (TMA), which continuously averages the teacher parameters with the up-to-date student parameters. In this paper, we propose "Spatial Ensemble", a novel model smoothing mechanism in parallel with TMA. Spatial Ensemble randomly picks up a small fragment of the student model to directly replace the corresponding fragment of the teacher model. Consequentially, it stitches different fragments of historical student models into a unity, yielding the "Spatial Ensemble" effect. Spatial Ensemble obtains comparable student-teacher learning performance by itself and demonstrates valuable complementarity with temporal moving average. Their integration, named Spatial-Temporal Smoothing, brings general (sometimes significant) improvement to the student-teacher learning framework on a variety of state-of-the-art methods. For example, based on the self-supervised method BYOL, it yields +0.9% top-1 accuracy improvement on ImageNet, while based on the semi-supervised approach FixMatch, it increases the top-1 accuracy by around +6% on CIFAR-10 when only few training labels are available. Codes and models are available at: https://github.com/tengteng95/Spatial_Ensemble.
Weight-dependent Gates for Network Pruning
Jul 04, 2020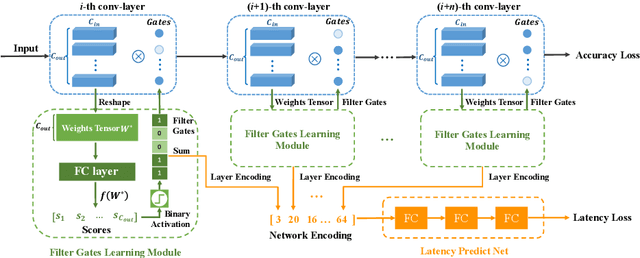
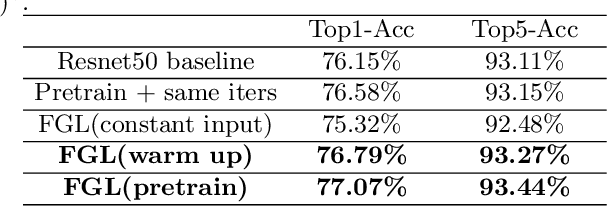
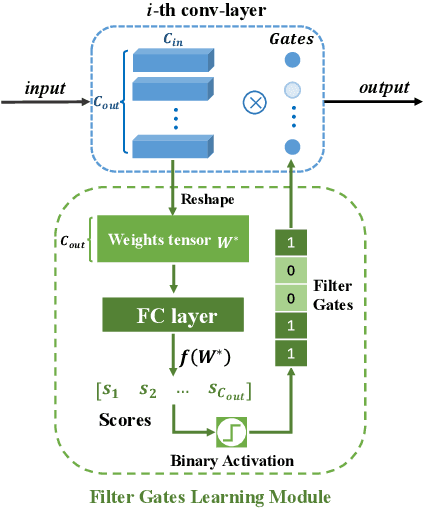
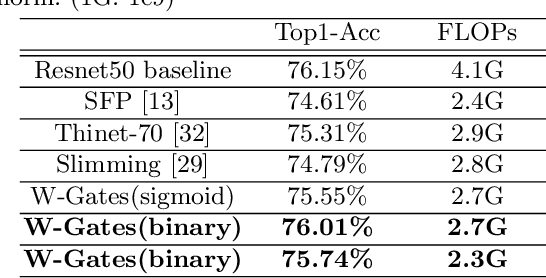
In this paper, we propose a simple and effective network pruning framework, which introduces novel weight-dependent gates (W-Gates) to prune filter adaptively. We argue that the pruning decision should depend on the convolutional weights, in other words, it should be a learnable function of filter weights. We thus construct the Filter Gates Learning Module (FGL) to learn the information from convolutional weights and obtain binary W-Gates to prune or keep the filters automatically. To prune the network under hardware constraint, we train a Latency Predict Net (LPNet) to estimate the hardware latency of candidate pruned networks. Based on the proposed LPNet, we can optimize W-Gates and the pruning ratio of each layer under latency constraint. The whole framework is differentiable and can be optimized by gradient-based method to achieve a compact network with better trade-off between accuracy and efficiency. We have demonstrated the effectiveness of our method on Resnet34, Resnet50 and MobileNet V2, achieving up to 1.33/1.28/1.1 higher Top-1 accuracy with lower hardware latency on ImageNet. Compared with state-of-the-art pruning methods, our method achieves superior performance.