 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolmes-VAD: Towards Unbiased and Explainable Video Anomaly Detection via Multi-modal LLM
Jun 18, 2024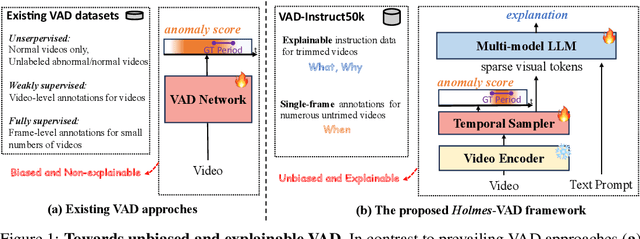

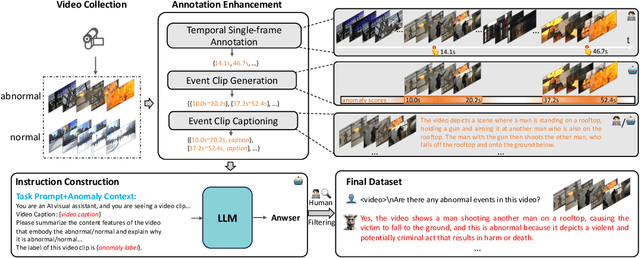

Towards open-ended Video Anomaly Detection (VAD), existing methods often exhibit biased detection when faced with challenging or unseen events and lack interpretability. To address these drawbacks, we propose Holmes-VAD, a novel framework that leverages precise temporal supervision and rich multimodal instructions to enable accurate anomaly localization and comprehensive explanations. Firstly, towards unbiased and explainable VAD system, we construct the first large-scale multimodal VAD instruction-tuning benchmark, i.e., VAD-Instruct50k. This dataset is created using a carefully designed semi-automatic labeling paradigm. Efficient single-frame annotations are applied to the collected untrimmed videos, which are then synthesized into high-quality analyses of both abnormal and normal video clips using a robust off-the-shelf video captioner and a large language model (LLM). Building upon the VAD-Instruct50k dataset, we develop a customized solution for interpretable video anomaly detection. We train a lightweight temporal sampler to select frames with high anomaly response and fine-tune a multimodal large language model (LLM) to generate explanatory content. Extensive experimental results validate the generality and interpretability of the proposed Holmes-VAD, establishing it as a novel interpretable technique for real-world video anomaly analysis. To support the community, our benchmark and model will be publicly available at https://github.com/pipixin321/HolmesVAD.
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
Jun 05, 2024



In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent advanced techniques, such as training-effective techniques, e.g., improved loss and pretraining, and interleaved window and global attentions for reducing the ViT encoder complexity. We improve the ViT encoder by aggregating multi-level feature maps, and the intermediate and final feature maps in the ViT encoder, forming richer feature maps, and introduce window-major feature map organization for improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time detectors, e.g., YOLO and its variants, on COCO and other benchmark datasets. Code and models are available at (https://github.com/Atten4Vis/LW-DETR).
GlanceVAD: Exploring Glance Supervision for Label-efficient Video Anomaly Detection
Mar 12, 2024



In recent years, video anomaly detection has been extensively investigated in both unsupervised and weakly supervised settings to alleviate costly temporal labeling. Despite significant progress, these methods still suffer from unsatisfactory results such as numerous false alarms, primarily due to the absence of precise temporal anomaly annotation. In this paper, we present a novel labeling paradigm, termed "glance annotation", to achieve a better balance between anomaly detection accuracy and annotation cost. Specifically, glance annotation is a random frame within each abnormal event, which can be easily accessed and is cost-effective. To assess its effectiveness, we manually annotate the glance annotations for two standard video anomaly detection datasets: UCF-Crime and XD-Violence. Additionally, we propose a customized GlanceVAD method, that leverages gaussian kernels as the basic unit to compose the temporal anomaly distribution, enabling the learning of diverse and robust anomaly representations from the glance annotations. Through comprehensive analysis and experiments, we verify that the proposed labeling paradigm can achieve an excellent trade-off between annotation cost and model performance. Extensive experimental results also demonstrate the effectiveness of our GlanceVAD approach, which significantly outperforms existing advanced unsupervised and weakly supervised methods. Code and annotations will be publicly available at https://github.com/pipixin321/GlanceVAD.
Spatial Cascaded Clustering and Weighted Memory for Unsupervised Person Re-identification
Mar 01, 2024Recent unsupervised person re-identification (re-ID) methods achieve high performance by leveraging fine-grained local context. These methods are referred to as part-based methods. However, most part-based methods obtain local contexts through horizontal division, which suffer from misalignment due to various human poses. Additionally, the misalignment of semantic information in part features restricts the use of metric learning, thus affecting the effectiveness of part-based methods. The two issues mentioned above result in the under-utilization of part features in part-based methods. We introduce the Spatial Cascaded Clustering and Weighted Memory (SCWM) method to address these challenges. SCWM aims to parse and align more accurate local contexts for different human body parts while allowing the memory module to balance hard example mining and noise suppression. Specifically, we first analyze the foreground omissions and spatial confusions issues in the previous method. Then, we propose foreground and space corrections to enhance the completeness and reasonableness of the human parsing results. Next, we introduce a weighted memory and utilize two weighting strategies. These strategies address hard sample mining for global features and enhance noise resistance for part features, which enables better utilization of both global and part features. Extensive experiments on Market-1501 and MSMT17 validate the proposed method's effectiveness over many state-of-the-art methods.
Group DETR v2: Strong Object Detector with Encoder-Decoder Pretraining
Nov 07, 2022

We present a strong object detector with encoder-decoder pretraining and finetuning. Our method, called Group DETR v2, is built upon a vision transformer encoder ViT-Huge~\cite{dosovitskiy2020image}, a DETR variant DINO~\cite{zhang2022dino}, and an efficient DETR training method Group DETR~\cite{chen2022group}. The training process consists of self-supervised pretraining and finetuning a ViT-Huge encoder on ImageNet-1K, pretraining the detector on Object365, and finally finetuning it on COCO. Group DETR v2 achieves $\textbf{64.5}$ mAP on COCO test-dev, and establishes a new SoTA on the COCO leaderboard https://paperswithcode.com/sota/object-detection-on-coco
Content-Variant Reference Image Quality Assessment via Knowledge Distillation
Feb 26, 2022
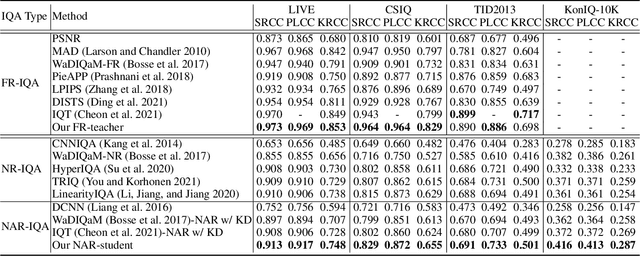
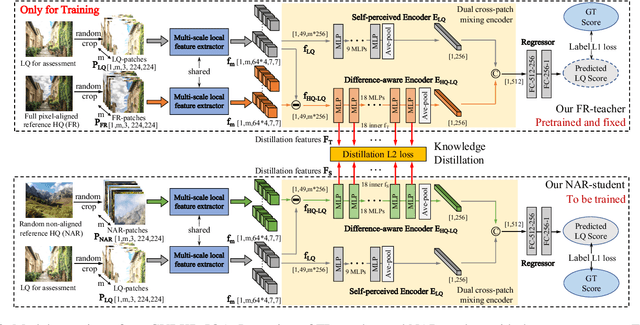

Generally, humans are more skilled at perceiving differences between high-quality (HQ) and low-quality (LQ) images than directly judging the quality of a single LQ image. This situation also applies to image quality assessment (IQA). Although recent no-reference (NR-IQA) methods have made great progress to predict image quality free from the reference image, they still have the potential to achieve better performance since HQ image information is not fully exploited. In contrast, full-reference (FR-IQA) methods tend to provide more reliable quality evaluation, but its practicability is affected by the requirement for pixel-level aligned reference images. To address this, we firstly propose the content-variant reference method via knowledge distillation (CVRKD-IQA). Specifically, we use non-aligned reference (NAR) images to introduce various prior distributions of high-quality images. The comparisons of distribution differences between HQ and LQ images can help our model better assess the image quality. Further, the knowledge distillation transfers more HQ-LQ distribution difference information from the FR-teacher to the NAR-student and stabilizing CVRKD-IQA performance. Moreover, to fully mine the local-global combined information, while achieving faster inference speed, our model directly processes multiple image patches from the input with the MLP-mixer. Cross-dataset experiments verify that our model can outperform all NAR/NR-IQA SOTAs, even reach comparable performance with FR-IQA methods on some occasions. Since the content-variant and non-aligned reference HQ images are easy to obtain, our model can support more IQA applications with its relative robustness to content variations. Our code and more detailed elaborations of supplements are available: https://github.com/guanghaoyin/CVRKD-IQA.
Multi-Centroid Representation Network for Domain Adaptive Person Re-ID
Dec 22, 2021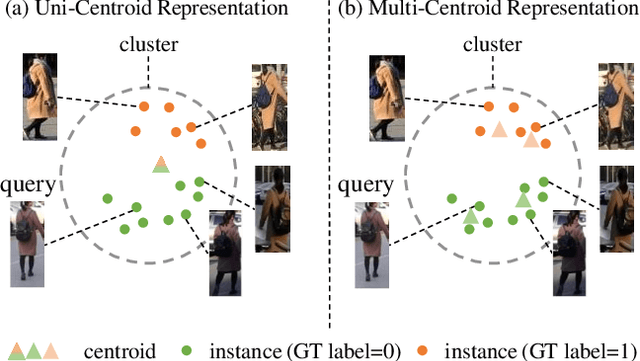
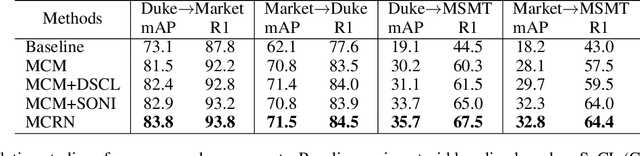
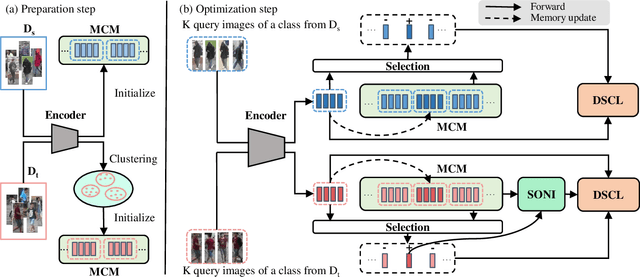
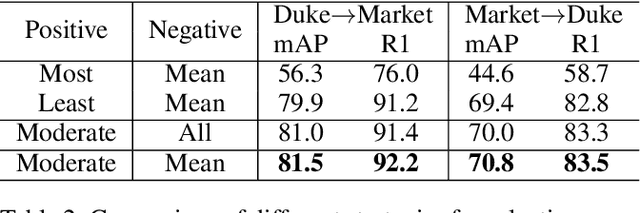
Recently, many approaches tackle the Unsupervised Domain Adaptive person re-identification (UDA re-ID) problem through pseudo-label-based contrastive learning. During training, a uni-centroid representation is obtained by simply averaging all the instance features from a cluster with the same pseudo label. However, a cluster may contain images with different identities (label noises) due to the imperfect clustering results, which makes the uni-centroid representation inappropriate. In this paper, we present a novel Multi-Centroid Memory (MCM) to adaptively capture different identity information within the cluster. MCM can effectively alleviate the issue of label noises by selecting proper positive/negative centroids for the query image. Moreover, we further propose two strategies to improve the contrastive learning process. First, we present a Domain-Specific Contrastive Learning (DSCL) mechanism to fully explore intradomain information by comparing samples only from the same domain. Second, we propose Second-Order Nearest Interpolation (SONI) to obtain abundant and informative negative samples. We integrate MCM, DSCL, and SONI into a unified framework named Multi-Centroid Representation Network (MCRN). Extensive experiments demonstrate the superiority of MCRN over state-of-the-art approaches on multiple UDA re-ID tasks and fully unsupervised re-ID tasks.
Modality-Aware Triplet Hard Mining for Zero-shot Sketch-Based Image Retrieval
Dec 16, 2021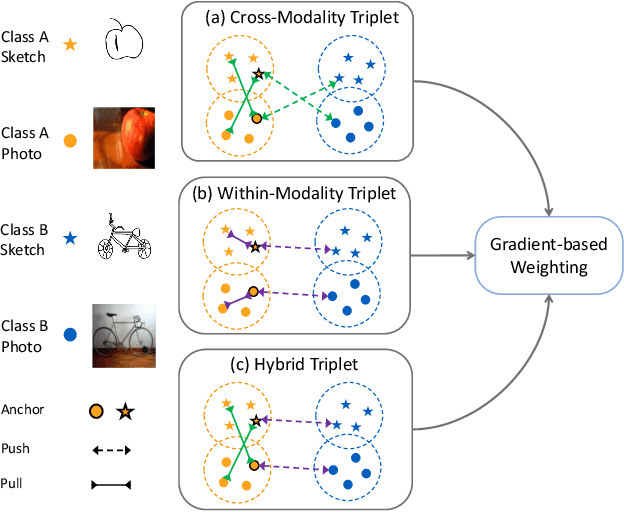



This paper tackles the Zero-Shot Sketch-Based Image Retrieval (ZS-SBIR) problem from the viewpoint of cross-modality metric learning. This task has two characteristics: 1) the zero-shot setting requires a metric space with good within-class compactness and the between-class discrepancy for recognizing the novel classes and 2) the sketch query and the photo gallery are in different modalities. The metric learning viewpoint benefits ZS-SBIR from two aspects. First, it facilitates improvement through recent good practices in deep metric learning (DML). By combining two fundamental learning approaches in DML, e.g., classification training and pairwise training, we set up a strong baseline for ZS-SBIR. Without bells and whistles, this baseline achieves competitive retrieval accuracy. Second, it provides an insight that properly suppressing the modality gap is critical. To this end, we design a novel method named Modality-Aware Triplet Hard Mining (MATHM). MATHM enhances the baseline with three types of pairwise learning, e.g., a cross-modality sample pair, a within-modality sample pair, and their combination.\We also design an adaptive weighting method to balance these three components during training dynamically. Experimental results confirm that MATHM brings another round of significant improvement based on the strong baseline and sets up new state-of-the-art performance. For example, on the TU-Berlin dataset, we achieve 47.88+2.94% mAP@all and 58.28+2.34% Prec@100. Code will be publicly available at: https://github.com/huangzongheng/MATHM.
Weakly Supervised Person Search with Region Siamese Networks
Sep 13, 2021

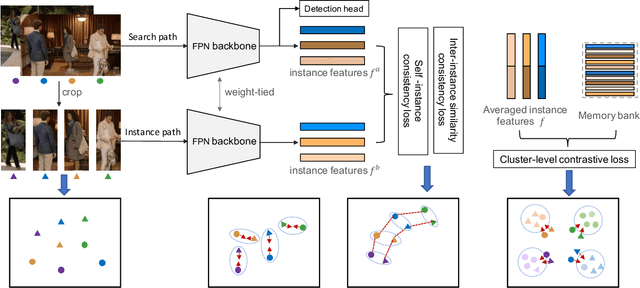
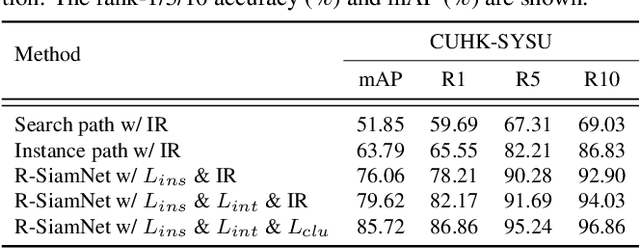
Supervised learning is dominant in person search, but it requires elaborate labeling of bounding boxes and identities. Large-scale labeled training data is often difficult to collect, especially for person identities. A natural question is whether a good person search model can be trained without the need of identity supervision. In this paper, we present a weakly supervised setting where only bounding box annotations are available. Based on this new setting, we provide an effective baseline model termed Region Siamese Networks (R-SiamNets). Towards learning useful representations for recognition in the absence of identity labels, we supervise the R-SiamNet with instance-level consistency loss and cluster-level contrastive loss. For instance-level consistency learning, the R-SiamNet is constrained to extract consistent features from each person region with or without out-of-region context. For cluster-level contrastive learning, we enforce the aggregation of closest instances and the separation of dissimilar ones in feature space. Extensive experiments validate the utility of our weakly supervised method. Our model achieves the rank-1 of 87.1% and mAP of 86.0% on CUHK-SYSU benchmark, which surpasses several fully supervised methods, such as OIM and MGTS, by a clear margin. More promising performance can be reached by incorporating extra training data. We hope this work could encourage the future research in this field.
Decoupled and Memory-Reinforced Networks: Towards Effective Feature Learning for One-Step Person Search
Feb 22, 2021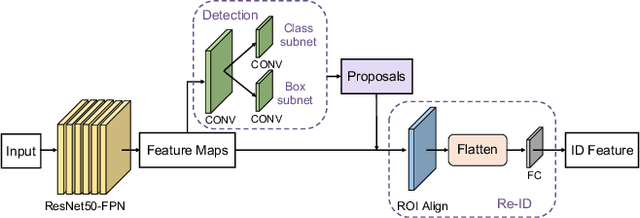
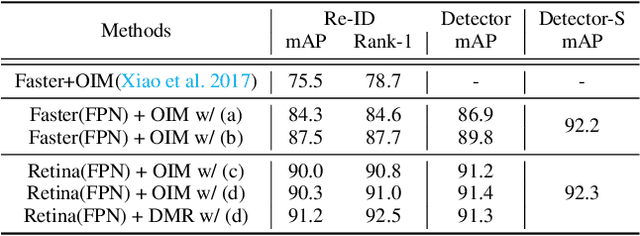
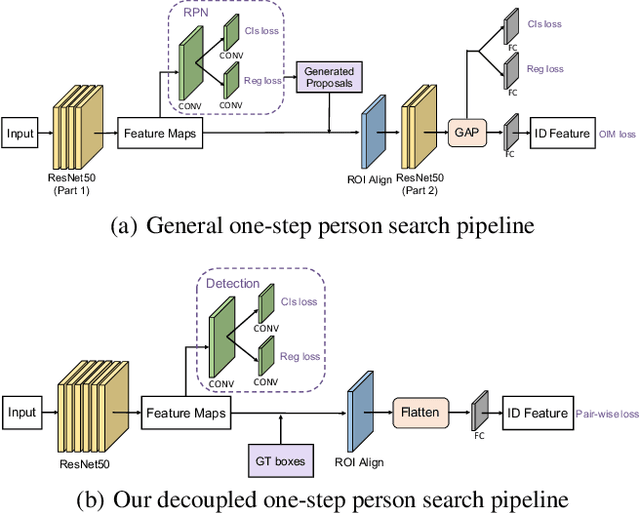
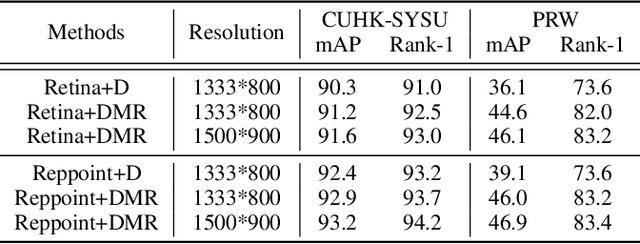
The goal of person search is to localize and match query persons from scene images. For high efficiency, one-step methods have been developed to jointly handle the pedestrian detection and identification sub-tasks using a single network. There are two major challenges in the current one-step approaches. One is the mutual interference between the optimization objectives of multiple sub-tasks. The other is the sub-optimal identification feature learning caused by small batch size when end-to-end training. To overcome these problems, we propose a decoupled and memory-reinforced network (DMRNet). Specifically, to reconcile the conflicts of multiple objectives, we simplify the standard tightly coupled pipelines and establish a deeply decoupled multi-task learning framework. Further, we build a memory-reinforced mechanism to boost the identification feature learning. By queuing the identification features of recently accessed instances into a memory bank, the mechanism augments the similarity pair construction for pairwise metric learning. For better encoding consistency of the stored features, a slow-moving average of the network is applied for extracting these features. In this way, the dual networks reinforce each other and converge to robust solution states. Experimentally, the proposed method obtains 93.2% and 46.9% mAP on CUHK-SYSU and PRW datasets, which exceeds all the existing one-step methods.