 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Video Streaming Super-Resolution with Adaptive Look-Up Table Fusion
Mar 01, 2023This paper focuses on Super-resolution for online video streaming data. Applying existing super-resolution methods to video streaming data is non-trivial for two reasons. First, to support application with constant interactions, video streaming has a high requirement for latency that most existing methods are less applicable, especially on low-end devices. Second, existing video streaming protocols (e.g., WebRTC) dynamically adapt the video quality to the network condition, thus video streaming in the wild varies greatly under different network bandwidths, which leads to diverse and dynamic degradations. To tackle the above two challenges, we proposed a novel video super-resolution method for online video streaming. First, we incorporate Look-Up Table (LUT) to lightweight convolution modules to achieve real-time latency. Second, for variant degradations, we propose a pixel-level LUT fusion strategy, where a set of LUT bases are built upon state-of-the-art SR networks pre-trained on different degraded data, and those LUT bases are combined with extracted weights from lightweight convolution modules to adaptively handle dynamic degradations. Extensive experiments are conducted on a newly proposed online video streaming dataset named LDV-WebRTC. All the results show that our method significantly outperforms existing LUT-based methods and offers competitive SR performance with faster speed compared to efficient CNN-based methods. Accelerated with our parallel LUT inference, our proposed method can even support online 720P video SR around 100 FPS.
Content-Variant Reference Image Quality Assessment via Knowledge Distillation
Feb 26, 2022
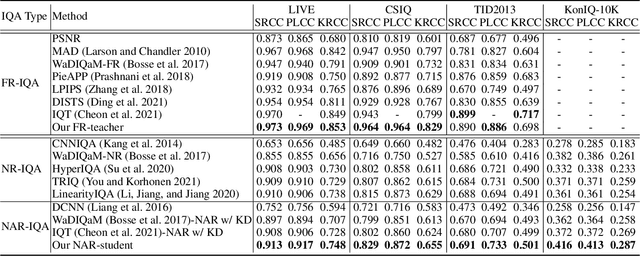
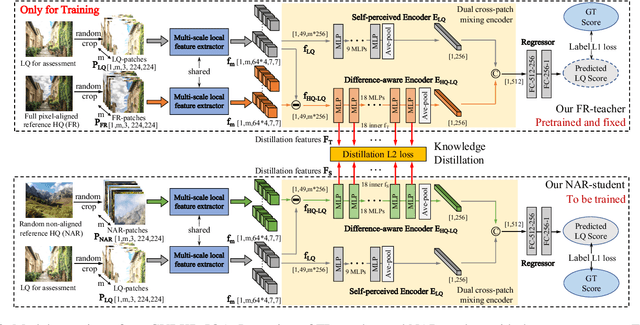

Generally, humans are more skilled at perceiving differences between high-quality (HQ) and low-quality (LQ) images than directly judging the quality of a single LQ image. This situation also applies to image quality assessment (IQA). Although recent no-reference (NR-IQA) methods have made great progress to predict image quality free from the reference image, they still have the potential to achieve better performance since HQ image information is not fully exploited. In contrast, full-reference (FR-IQA) methods tend to provide more reliable quality evaluation, but its practicability is affected by the requirement for pixel-level aligned reference images. To address this, we firstly propose the content-variant reference method via knowledge distillation (CVRKD-IQA). Specifically, we use non-aligned reference (NAR) images to introduce various prior distributions of high-quality images. The comparisons of distribution differences between HQ and LQ images can help our model better assess the image quality. Further, the knowledge distillation transfers more HQ-LQ distribution difference information from the FR-teacher to the NAR-student and stabilizing CVRKD-IQA performance. Moreover, to fully mine the local-global combined information, while achieving faster inference speed, our model directly processes multiple image patches from the input with the MLP-mixer. Cross-dataset experiments verify that our model can outperform all NAR/NR-IQA SOTAs, even reach comparable performance with FR-IQA methods on some occasions. Since the content-variant and non-aligned reference HQ images are easy to obtain, our model can support more IQA applications with its relative robustness to content variations. Our code and more detailed elaborations of supplements are available: https://github.com/guanghaoyin/CVRKD-IQA.
Conditional Meta-Network for Blind Super-Resolution with Multiple Degradations
Apr 09, 2021
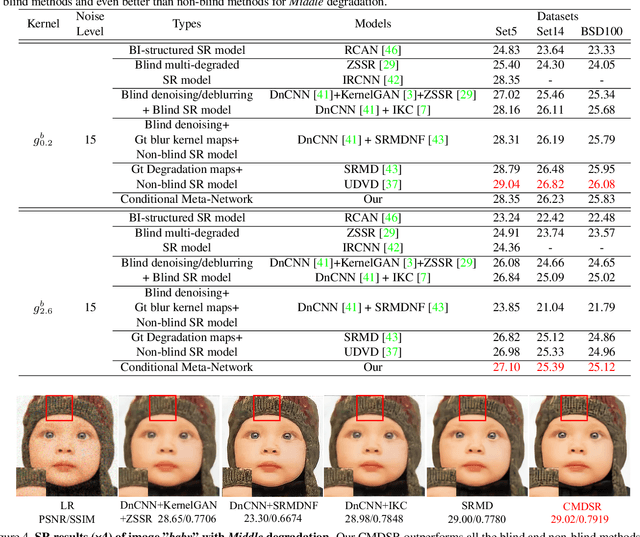
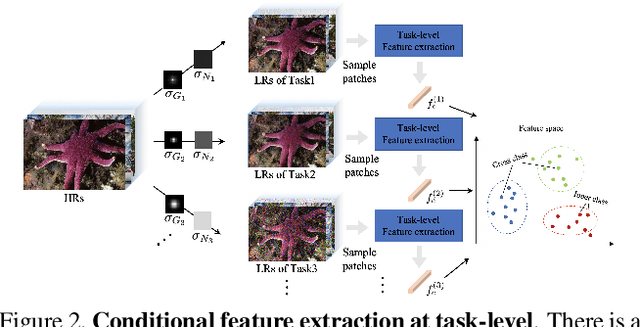
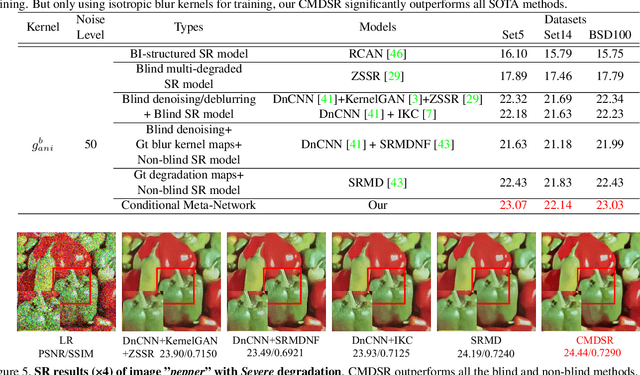
Although single-image super-resolution (SISR) methods have achieved great success on single degradation, they still suffer performance drop with multiple degrading effects in real scenarios. Recently, some blind and non-blind models for multiple degradations have been explored. However, those methods usually degrade significantly for distribution shifts between the training and test data. Towards this end, we propose a conditional meta-network framework (named CMDSR) for the first time, which helps SR framework learn how to adapt to changes in input distribution. We extract degradation prior at task-level with the proposed ConditionNet, which will be used to adapt the parameters of the basic SR network (BaseNet). Specifically, the ConditionNet of our framework first learns the degradation prior from a support set, which is composed of a series of degraded image patches from the same task. Then the adaptive BaseNet rapidly shifts its parameters according to the conditional features. Moreover, in order to better extract degradation prior, we propose a task contrastive loss to decrease the inner-task distance and increase the cross-task distance between task-level features. Without predefining degradation maps, our blind framework can conduct one single parameter update to yield considerable SR results. Extensive experiments demonstrate the effectiveness of CMDSR over various blind, even non-blind methods. The flexible BaseNet structure also reveals that CMDSR can be a general framework for large series of SISR models.
Joint Generative Learning and Super-Resolution For Real-World Camera-Screen Degradation
Sep 14, 2020



In real-world single image super-resolution (SISR) task, the low-resolution image suffers more complicated degradations, not only downsampled by unknown kernels. However, existing SISR methods are generally studied with the synthetic low-resolution generation such as bicubic interpolation (BI), which greatly limits their performance. Recently, some researchers investigate real-world SISR from the perspective of the camera and smartphone. However, except the acquisition equipment, the display device also involves more complicated degradations. In this paper, we focus on the camera-screen degradation and build a real-world dataset (Cam-ScreenSR), where HR images are original ground truths from the previous DIV2K dataset and corresponding LR images are camera-captured versions of HRs displayed on the screen. We conduct extensive experiments to demonstrate that involving more real degradations is positive to improve the generalization of SISR models. Moreover, we propose a joint two-stage model. Firstly, the downsampling degradation GAN(DD-GAN) is trained to model the degradation and produces more various of LR images, which is validated to be efficient for data augmentation. Then the dual residual channel attention network (DuRCAN) learns to recover the SR image. The weighted combination of L1 loss and proposed Laplacian loss are applied to sharpen the high-frequency edges. Extensive experimental results in both typical synthetic and complicated real-world degradations validate the proposed method outperforms than existing SOTA models with less parameters, faster speed and better visual results. Moreover, in real captured photographs, our model also delivers best visual quality with sharper edge, less artifacts, especially appropriate color enhancement, which has not been accomplished by previous methods.
A Efficient Multimodal Framework for Large Scale Emotion Recognition by Fusing Music and Electrodermal Activity Signals
Aug 22, 2020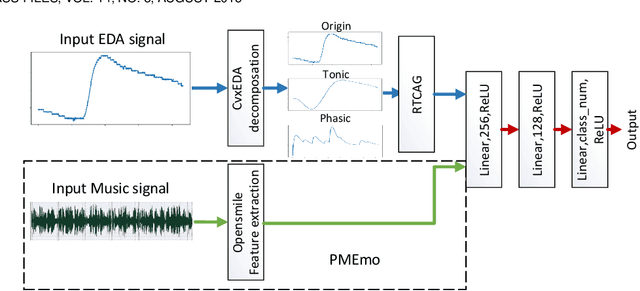
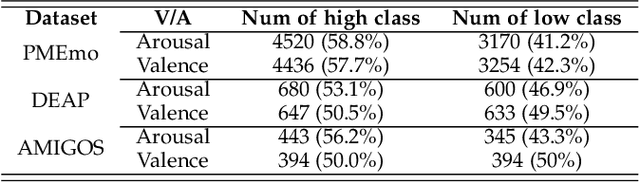
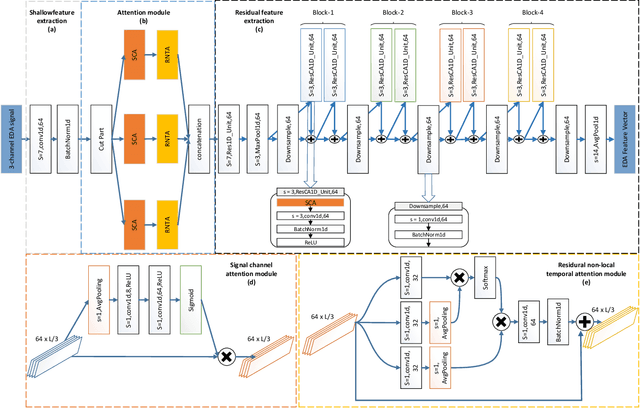

Considerable attention has been paid for physiological signal-based emotion recognition in field of affective computing. For the reliability and user friendly acquisition, Electrodermal Activity (EDA) has great advantage in practical applications. However, the EDA-based emotion recognition with hundreds of subjects still lacks effective solution. In this paper, our work makes an attempt to fuse the subject individual EDA features and the external evoked music features. And we propose an end-to-end multimodal framework, the 1-dimensional residual temporal and channel attention network (RTCAN-1D). For EDA features, the novel convex optimization-based EDA (CvxEDA) method is applied to decompose EDA signals into pahsic and tonic signals for mining the dynamic and steady features. The channel-temporal attention mechanism for EDA-based emotion recognition is firstly involved to improve the temporal- and channel-wise representation. For music features, we process the music signal with the open source toolkit openSMILE to obtain external feature vectors. The individual emotion features from EDA signals and external emotion benchmarks from music are fused in the classifing layers. We have conducted systematic comparisons on three multimodal datasets (PMEmo, DEAP, AMIGOS) for 2-classes valance/arousal emotion recognition. Our proposed RTCAN-1D outperforms the existing state-of-the-art models, which also validate that our work provides an reliable and efficient solution for large scale emotion recognition. Our code has been released at https://github.com/guanghaoyin/RTCAN-1D.
User independent Emotion Recognition with Residual Signal-Image Network
Aug 10, 2019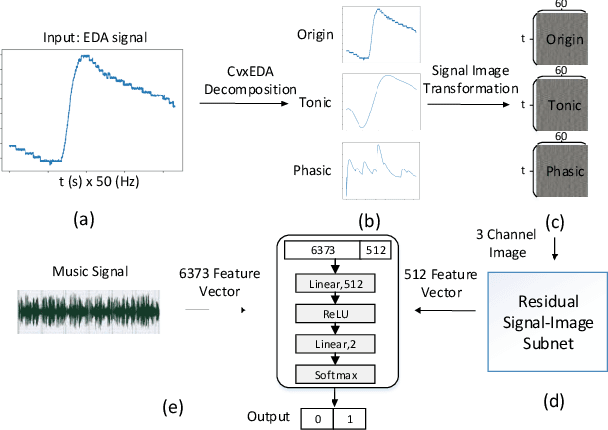
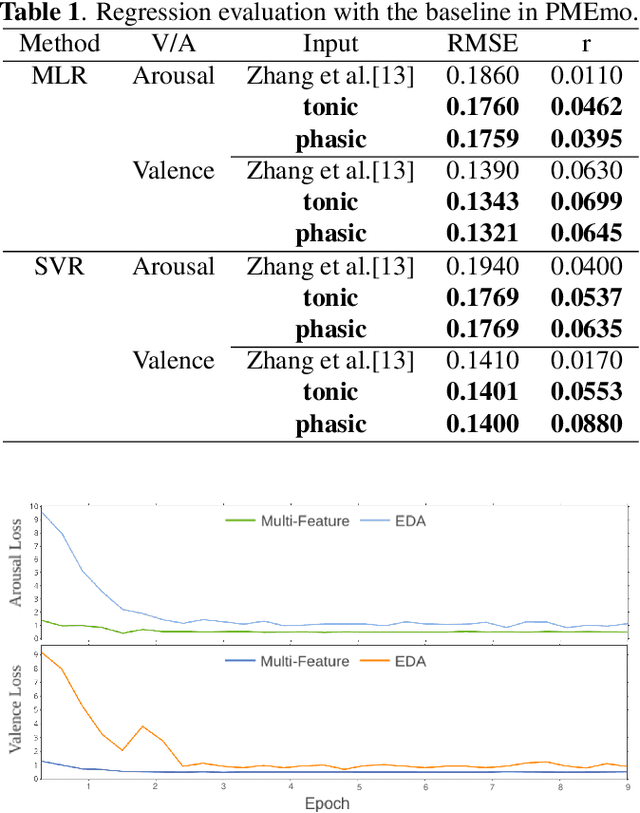
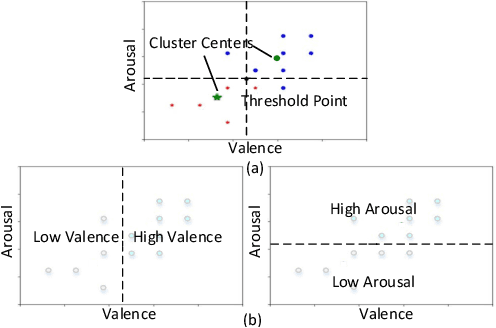
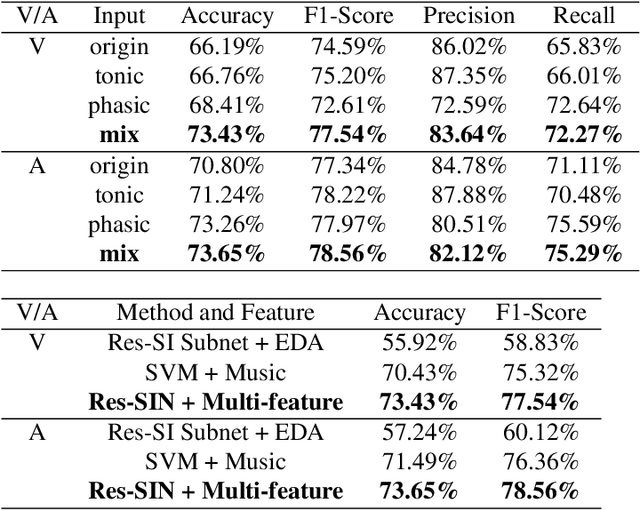
User independent emotion recognition with large scale physiological signals is a tough problem. There exist many advanced methods but they are conducted under relatively small datasets with dozens of subjects. Here, we propose Res-SIN, a novel end-to-end framework using Electrodermal Activity(EDA) signal images to classify human emotion. We first apply convex optimization-based EDA (cvxEDA) to decompose signals and mine the static and dynamic emotion changes. Then, we transform decomposed signals to images so that they can be effectively processed by CNN frameworks. The Res-SIN combines individual emotion features and external emotion benchmarks to accelerate convergence. We evaluate our approach on the PMEmo dataset, the currently largest emotional dataset containing music and EDA signals. To the best of author's knowledge, our method is the first attempt to classify large scale subject-independent emotion with 7962 pieces of EDA signals from 457 subjects. Experimental results demonstrate the reliability of our model and the binary classification accuracy of 73.65% and 73.43% on arousal and valence dimension can be used as a baseline.