 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Variant Reference Image Quality Assessment via Knowledge Distillation
Paper and Code

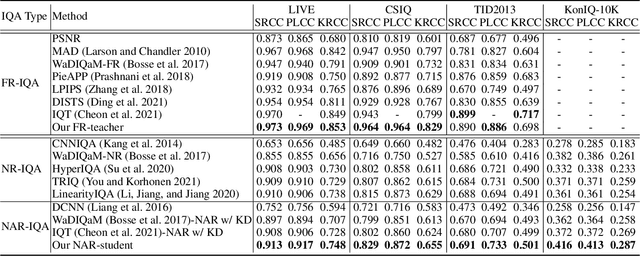
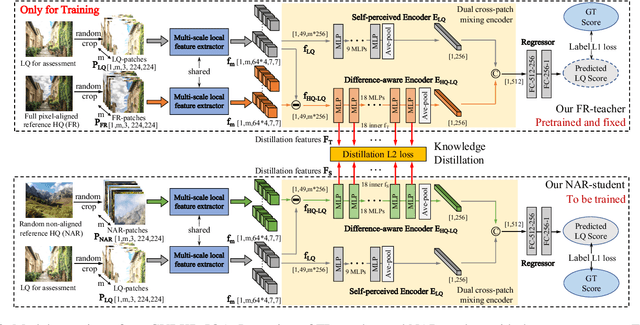

Generally, humans are more skilled at perceiving differences between high-quality (HQ) and low-quality (LQ) images than directly judging the quality of a single LQ image. This situation also applies to image quality assessment (IQA). Although recent no-reference (NR-IQA) methods have made great progress to predict image quality free from the reference image, they still have the potential to achieve better performance since HQ image information is not fully exploited. In contrast, full-reference (FR-IQA) methods tend to provide more reliable quality evaluation, but its practicability is affected by the requirement for pixel-level aligned reference images. To address this, we firstly propose the content-variant reference method via knowledge distillation (CVRKD-IQA). Specifically, we use non-aligned reference (NAR) images to introduce various prior distributions of high-quality images. The comparisons of distribution differences between HQ and LQ images can help our model better assess the image quality. Further, the knowledge distillation transfers more HQ-LQ distribution difference information from the FR-teacher to the NAR-student and stabilizing CVRKD-IQA performance. Moreover, to fully mine the local-global combined information, while achieving faster inference speed, our model directly processes multiple image patches from the input with the MLP-mixer. Cross-dataset experiments verify that our model can outperform all NAR/NR-IQA SOTAs, even reach comparable performance with FR-IQA methods on some occasions. Since the content-variant and non-aligned reference HQ images are easy to obtain, our model can support more IQA applications with its relative robustness to content variations. Our code and more detailed elaborations of supplements are available: https://github.com/guanghaoyin/CVRKD-IQA.