 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneWorld: Taming Scene Generation with 3D Unified Representation Autoencoder
Mar 17, 2026Existing diffusion-based 3D scene generation methods primarily operate in 2D image/video latent spaces, which makes maintaining cross-view appearance and geometric consistency inherently challenging. To bridge this gap, we present OneWorld, a framework that performs diffusion directly within a coherent 3D representation space. Central to our approach is the 3D Unified Representation Autoencoder (3D-URAE); it leverages pretrained 3D foundation models and augments their geometry-centric nature by injecting appearance and distilling semantics into a unified 3D latent space. Furthermore, we introduce token-level Cross-View-Correspondence (CVC) consistency loss to explicitly enforce structural alignment across views, and propose Manifold-Drift Forcing (MDF) to mitigate train-inference exposure bias and shape a robust 3D manifold by mixing drifted and original representations. Comprehensive experiments demonstrate that OneWorld generates high-quality 3D scenes with superior cross-view consistency compared to state-of-the-art 2D-based methods. Our code will be available at https://github.com/SensenGao/OneWorld.
MMGen: Unified Multi-modal Image Generation and Understanding in One Go
Mar 26, 2025A unified diffusion framework for multi-modal generation and understanding has the transformative potential to achieve seamless and controllable image diffusion and other cross-modal tasks. In this paper, we introduce MMGen, a unified framework that integrates multiple generative tasks into a single diffusion model. This includes: (1) multi-modal category-conditioned generation, where multi-modal outputs are generated simultaneously through a single inference process, given category information; (2) multi-modal visual understanding, which accurately predicts depth, surface normals, and segmentation maps from RGB images; and (3) multi-modal conditioned generation, which produces corresponding RGB images based on specific modality conditions and other aligned modalities. Our approach develops a novel diffusion transformer that flexibly supports multi-modal output, along with a simple modality-decoupling strategy to unify various tasks. Extensive experiments and applications demonstrate the effectiveness and superiority of MMGen across diverse tasks and conditions, highlighting its potential for applications that require simultaneous generation and understanding.
LaVin-DiT: Large Vision Diffusion Transformer
Nov 18, 2024This paper presents the Large Vision Diffusion Transformer (LaVin-DiT), a scalable and unified foundation model designed to tackle over 20 computer vision tasks in a generative framework. Unlike existing large vision models directly adapted from natural language processing architectures, which rely on less efficient autoregressive techniques and disrupt spatial relationships essential for vision data, LaVin-DiT introduces key innovations to optimize generative performance for vision tasks. First, to address the high dimensionality of visual data, we incorporate a spatial-temporal variational autoencoder that encodes data into a continuous latent space. Second, for generative modeling, we develop a joint diffusion transformer that progressively produces vision outputs. Third, for unified multi-task training, in-context learning is implemented. Input-target pairs serve as task context, which guides the diffusion transformer to align outputs with specific tasks within the latent space. During inference, a task-specific context set and test data as queries allow LaVin-DiT to generalize across tasks without fine-tuning. Trained on extensive vision datasets, the model is scaled from 0.1B to 3.4B parameters, demonstrating substantial scalability and state-of-the-art performance across diverse vision tasks. This work introduces a novel pathway for large vision foundation models, underscoring the promising potential of diffusion transformers. The code and models will be open-sourced.
TrackGo: A Flexible and Efficient Method for Controllable Video Generation
Aug 21, 2024



Recent years have seen substantial progress in diffusion-based controllable video generation. However, achieving precise control in complex scenarios, including fine-grained object parts, sophisticated motion trajectories, and coherent background movement, remains a challenge. In this paper, we introduce TrackGo, a novel approach that leverages free-form masks and arrows for conditional video generation. This method offers users with a flexible and precise mechanism for manipulating video content. We also propose the TrackAdapter for control implementation, an efficient and lightweight adapter designed to be seamlessly integrated into the temporal self-attention layers of a pretrained video generation model. This design leverages our observation that the attention map of these layers can accurately activate regions corresponding to motion in videos. Our experimental results demonstrate that our new approach, enhanced by the TrackAdapter, achieves state-of-the-art performance on key metrics such as FVD, FID, and ObjMC scores. The project page of TrackGo can be found at: https://zhtjtcz.github.io/TrackGo-Page/
Box-Level Active Detection
Mar 23, 2023Active learning selects informative samples for annotation within budget, which has proven efficient recently on object detection. However, the widely used active detection benchmarks conduct image-level evaluation, which is unrealistic in human workload estimation and biased towards crowded images. Furthermore, existing methods still perform image-level annotation, but equally scoring all targets within the same image incurs waste of budget and redundant labels. Having revealed above problems and limitations, we introduce a box-level active detection framework that controls a box-based budget per cycle, prioritizes informative targets and avoids redundancy for fair comparison and efficient application. Under the proposed box-level setting, we devise a novel pipeline, namely Complementary Pseudo Active Strategy (ComPAS). It exploits both human annotations and the model intelligence in a complementary fashion: an efficient input-end committee queries labels for informative objects only; meantime well-learned targets are identified by the model and compensated with pseudo-labels. ComPAS consistently outperforms 10 competitors under 4 settings in a unified codebase. With supervision from labeled data only, it achieves 100% supervised performance of VOC0712 with merely 19% box annotations. On the COCO dataset, it yields up to 4.3% mAP improvement over the second-best method. ComPAS also supports training with the unlabeled pool, where it surpasses 90% COCO supervised performance with 85% label reduction. Our source code is publicly available at https://github.com/lyumengyao/blad.
QueryPose: Sparse Multi-Person Pose Regression via Spatial-Aware Part-Level Query
Dec 15, 2022



We propose a sparse end-to-end multi-person pose regression framework, termed QueryPose, which can directly predict multi-person keypoint sequences from the input image. The existing end-to-end methods rely on dense representations to preserve the spatial detail and structure for precise keypoint localization. However, the dense paradigm introduces complex and redundant post-processes during inference. In our framework, each human instance is encoded by several learnable spatial-aware part-level queries associated with an instance-level query. First, we propose the Spatial Part Embedding Generation Module (SPEGM) that considers the local spatial attention mechanism to generate several spatial-sensitive part embeddings, which contain spatial details and structural information for enhancing the part-level queries. Second, we introduce the Selective Iteration Module (SIM) to adaptively update the sparse part-level queries via the generated spatial-sensitive part embeddings stage-by-stage. Based on the two proposed modules, the part-level queries are able to fully encode the spatial details and structural information for precise keypoint regression. With the bipartite matching, QueryPose avoids the hand-designed post-processes and surpasses the existing dense end-to-end methods with 73.6 AP on MS COCO mini-val set and 72.7 AP on CrowdPose test set. Code is available at https://github.com/buptxyb666/QueryPose.
AdaptivePose++: A Powerful Single-Stage Network for Multi-Person Pose Regression
Oct 08, 2022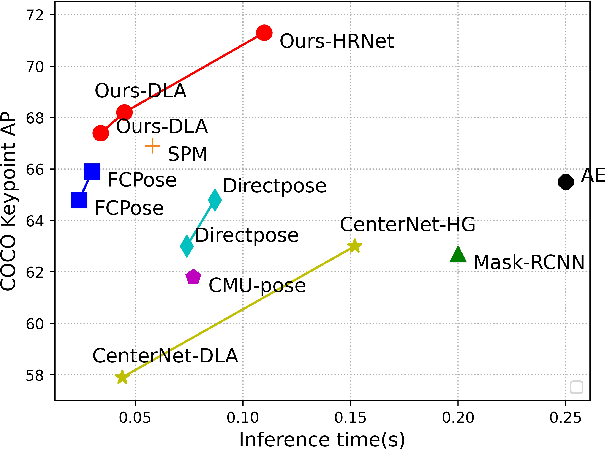

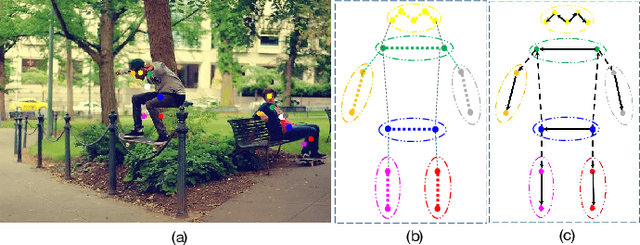
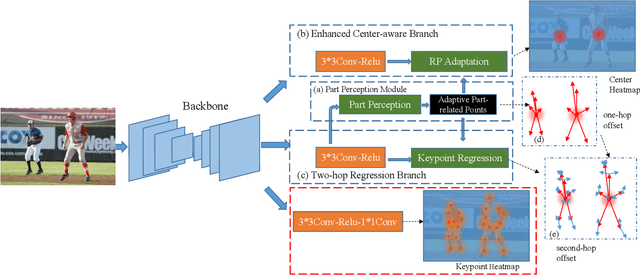
Multi-person pose estimation generally follows top-down and bottom-up paradigms. Both of them use an extra stage ($\boldsymbol{e.g.,}$ human detection in top-down paradigm or grouping process in bottom-up paradigm) to build the relationship between the human instance and corresponding keypoints, thus leading to the high computation cost and redundant two-stage pipeline. To address the above issue, we propose to represent the human parts as adaptive points and introduce a fine-grained body representation method. The novel body representation is able to sufficiently encode the diverse pose information and effectively model the relationship between the human instance and corresponding keypoints in a single-forward pass. With the proposed body representation, we further deliver a compact single-stage multi-person pose regression network, termed as AdaptivePose. During inference, our proposed network only needs a single-step decode operation to form the multi-person pose without complex post-processes and refinements. We employ AdaptivePose for both 2D/3D multi-person pose estimation tasks to verify the effectiveness of AdaptivePose. Without any bells and whistles, we achieve the most competitive performance on MS COCO and CrowdPose in terms of accuracy and speed. Furthermore, the outstanding performance on MuCo-3DHP and MuPoTS-3D further demonstrates the effectiveness and generalizability on 3D scenes. Code is available at https://github.com/buptxyb666/AdaptivePose.
MCIBI++: Soft Mining Contextual Information Beyond Image for Semantic Segmentation
Sep 09, 2022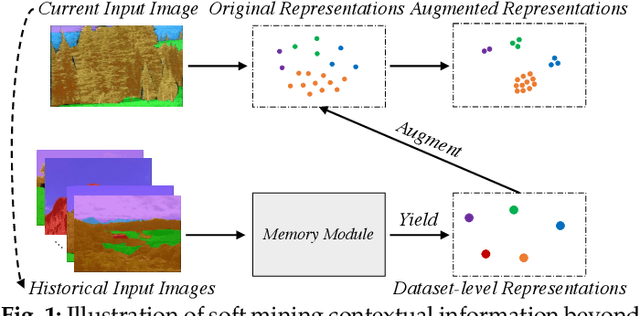


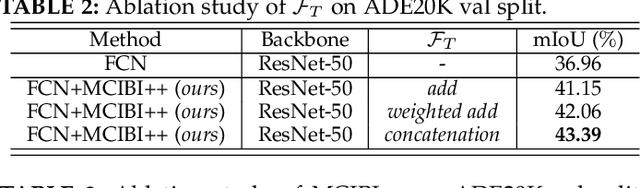
Co-occurrent visual pattern makes context aggregation become an essential paradigm for semantic segmentation.The existing studies focus on modeling the contexts within image while neglecting the valuable semantics of the corresponding category beyond image. To this end, we propose a novel soft mining contextual information beyond image paradigm named MCIBI++ to further boost the pixel-level representations. Specifically, we first set up a dynamically updated memory module to store the dataset-level distribution information of various categories and then leverage the information to yield the dataset-level category representations during network forward. After that, we generate a class probability distribution for each pixel representation and conduct the dataset-level context aggregation with the class probability distribution as weights. Finally, the original pixel representations are augmented with the aggregated dataset-level and the conventional image-level contextual information. Moreover, in the inference phase, we additionally design a coarse-to-fine iterative inference strategy to further boost the segmentation results. MCIBI++ can be effortlessly incorporated into the existing segmentation frameworks and bring consistent performance improvements. Also, MCIBI++ can be extended into the video semantic segmentation framework with considerable improvements over the baseline. Equipped with MCIBI++, we achieved the state-of-the-art performance on seven challenging image or video semantic segmentation benchmarks.
Single-Stage Open-world Instance Segmentation with Cross-task Consistency Regularization
Aug 18, 2022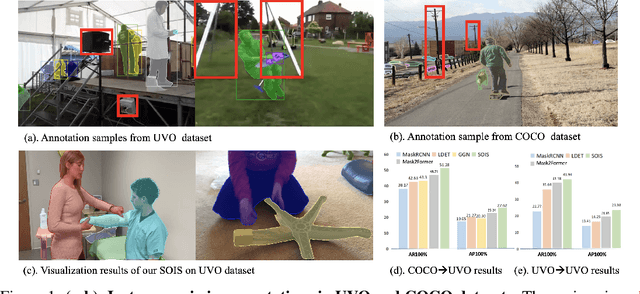
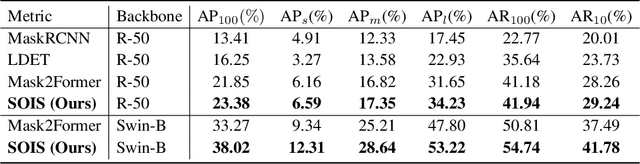
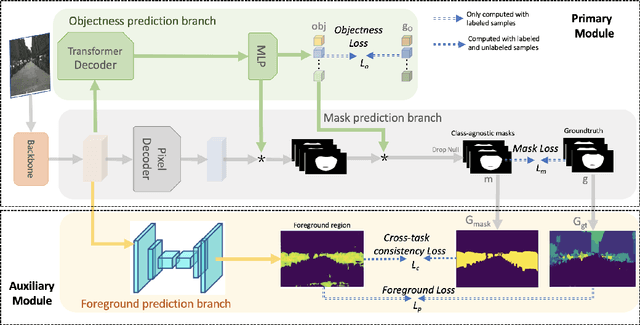

Open-world instance segmentation (OWIS) aims to segment class-agnostic instances from images, which has a wide range of real-world applications such as autonomous driving. Most existing approaches follow a two-stage pipeline: performing class-agnostic detection first and then class-specific mask segmentation. In contrast, this paper proposes a single-stage framework to produce a mask for each instance directly. Also, instance mask annotations could be noisy in the existing datasets; to overcome this issue, we introduce a new regularization loss. Specifically, we first train an extra branch to perform an auxiliary task of predicting foreground regions (i.e. regions belonging to any object instance), and then encourage the prediction from the auxiliary branch to be consistent with the predictions of the instance masks. The key insight is that such a cross-task consistency loss could act as an error-correcting mechanism to combat the errors in annotations. Further, we discover that the proposed cross-task consistency loss can be applied to images without any annotation, lending itself to a semi-supervised learning method. Through extensive experiments, we demonstrate that the proposed method can achieve impressive results in both fully-supervised and semi-supervised settings. Compared to SOTA methods, the proposed method significantly improves the $AP_{100}$ score by 4.75\% in UVO$\rightarrow$UVO setting and 4.05\% in COCO$\rightarrow$UVO setting. In the case of semi-supervised learning, our model learned with only 30\% labeled data, even outperforms its fully-supervised counterpart with 50\% labeled data. The code will be released soon.
You Should Look at All Objects
Jul 16, 2022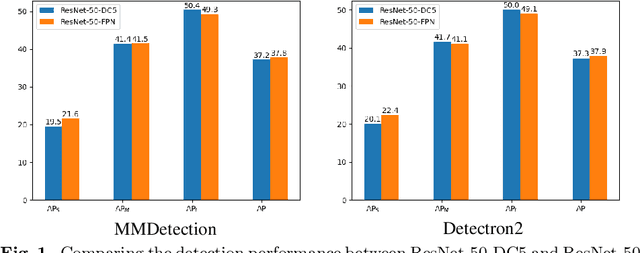
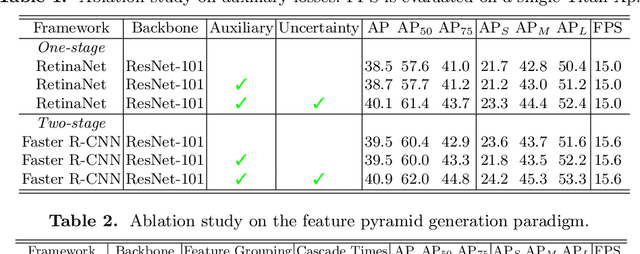
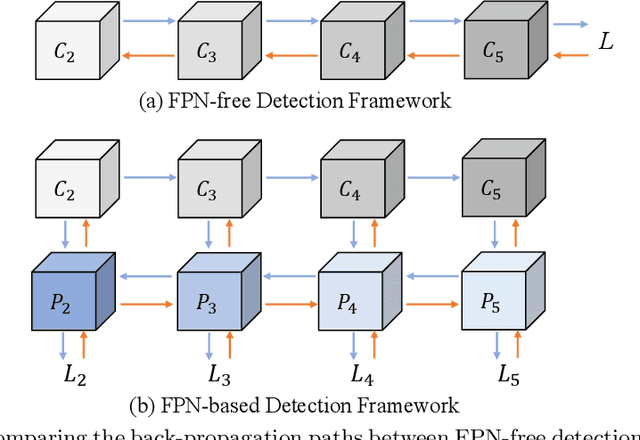
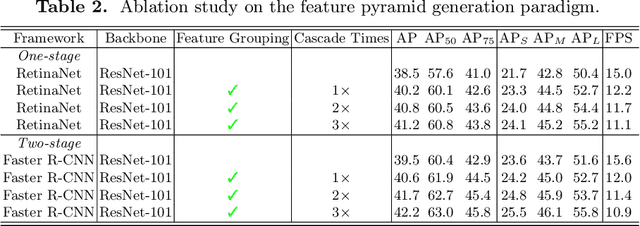
Feature pyramid network (FPN) is one of the key components for object detectors. However, there is a long-standing puzzle for researchers that the detection performance of large-scale objects are usually suppressed after introducing FPN. To this end, this paper first revisits FPN in the detection framework and reveals the nature of the success of FPN from the perspective of optimization. Then, we point out that the degraded performance of large-scale objects is due to the arising of improper back-propagation paths after integrating FPN. It makes each level of the backbone network only has the ability to look at the objects within a certain scale range. Based on these analysis, two feasible strategies are proposed to enable each level of the backbone to look at all objects in the FPN-based detection frameworks. Specifically, one is to introduce auxiliary objective functions to make each backbone level directly receive the back-propagation signals of various-scale objects during training. The other is to construct the feature pyramid in a more reasonable way to avoid the irrational back-propagation paths. Extensive experiments on the COCO benchmark validate the soundness of our analysis and the effectiveness of our methods. Without bells and whistles, we demonstrate that our method achieves solid improvements (more than 2%) on various detection frameworks: one-stage, two-stage, anchor-based, anchor-free and transformer-based detectors.