 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE-VL: Modeling Unified VLM through Semantic Discrete Encoding
Nov 26, 2024



We introduce MUSE-VL, a Unified Vision-Language Model through Semantic discrete Encoding for multimodal understanding and generation. Recently, the research community has begun exploring unified models for visual generation and understanding. However, existing vision tokenizers (e.g., VQGAN) only consider low-level information, which makes it difficult to align with texture semantic features. This results in high training complexity and necessitates a large amount of training data to achieve optimal performance. Additionally, their performance is still far from dedicated understanding models. This paper proposes Semantic Discrete Encoding (SDE), which effectively aligns the information of visual tokens and language tokens by adding semantic constraints to the visual tokenizer. This greatly reduces training difficulty and improves the performance of the unified model. The proposed model significantly surpasses the previous state-of-the-art in various vision-language benchmarks and achieves better performance than dedicated understanding models.
Single-Stage Open-world Instance Segmentation with Cross-task Consistency Regularization
Aug 18, 2022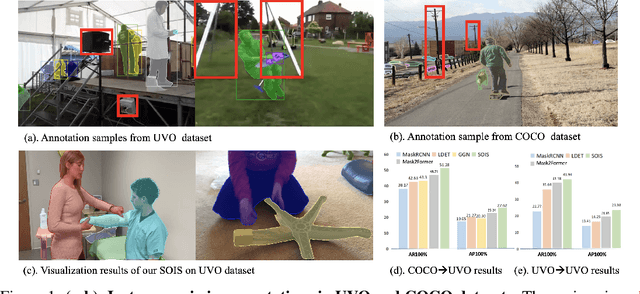
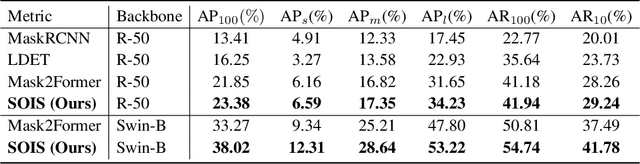
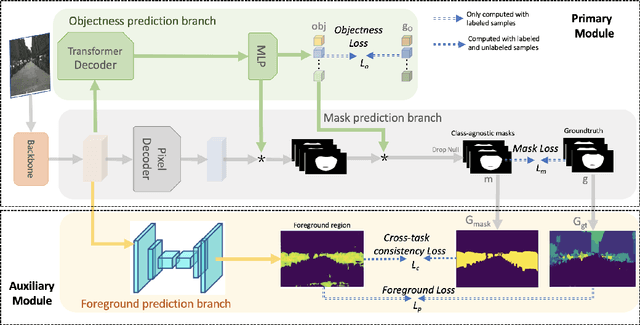

Open-world instance segmentation (OWIS) aims to segment class-agnostic instances from images, which has a wide range of real-world applications such as autonomous driving. Most existing approaches follow a two-stage pipeline: performing class-agnostic detection first and then class-specific mask segmentation. In contrast, this paper proposes a single-stage framework to produce a mask for each instance directly. Also, instance mask annotations could be noisy in the existing datasets; to overcome this issue, we introduce a new regularization loss. Specifically, we first train an extra branch to perform an auxiliary task of predicting foreground regions (i.e. regions belonging to any object instance), and then encourage the prediction from the auxiliary branch to be consistent with the predictions of the instance masks. The key insight is that such a cross-task consistency loss could act as an error-correcting mechanism to combat the errors in annotations. Further, we discover that the proposed cross-task consistency loss can be applied to images without any annotation, lending itself to a semi-supervised learning method. Through extensive experiments, we demonstrate that the proposed method can achieve impressive results in both fully-supervised and semi-supervised settings. Compared to SOTA methods, the proposed method significantly improves the $AP_{100}$ score by 4.75\% in UVO$\rightarrow$UVO setting and 4.05\% in COCO$\rightarrow$UVO setting. In the case of semi-supervised learning, our model learned with only 30\% labeled data, even outperforms its fully-supervised counterpart with 50\% labeled data. The code will be released soon.