 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlossGau: Efficient Inverse Rendering for Glossy Surface with Anisotropic Spherical Gaussian
Feb 19, 2025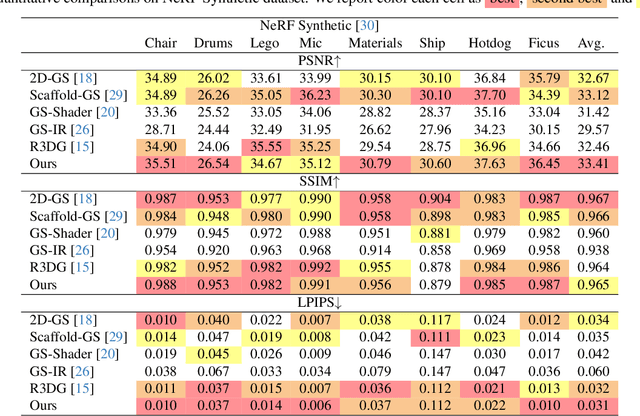
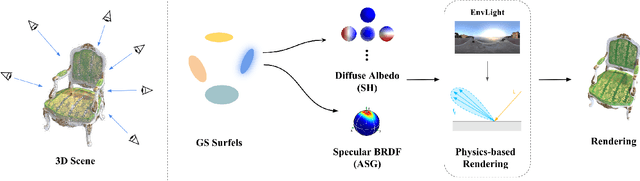
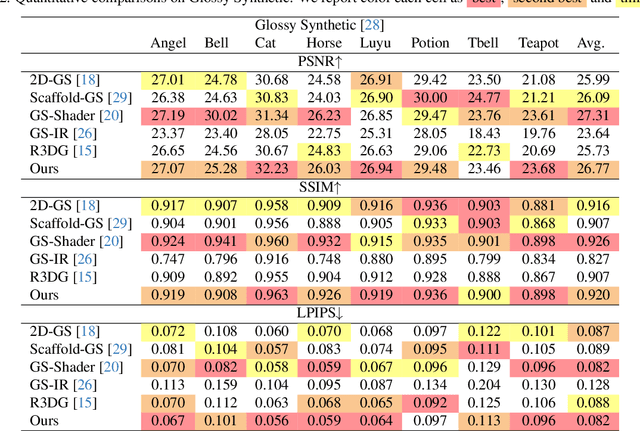

The reconstruction of 3D objects from calibrated photographs represents a fundamental yet intricate challenge in the domains of computer graphics and vision. Although neural reconstruction approaches based on Neural Radiance Fields (NeRF) have shown remarkable capabilities, their processing costs remain substantial. Recently, the advent of 3D Gaussian Splatting (3D-GS) largely improves the training efficiency and facilitates to generate realistic rendering in real-time. However, due to the limited ability of Spherical Harmonics (SH) to represent high-frequency information, 3D-GS falls short in reconstructing glossy objects. Researchers have turned to enhance the specular expressiveness of 3D-GS through inverse rendering. Yet these methods often struggle to maintain the training and rendering efficiency, undermining the benefits of Gaussian Splatting techniques. In this paper, we introduce GlossGau, an efficient inverse rendering framework that reconstructs scenes with glossy surfaces while maintaining training and rendering speeds comparable to vanilla 3D-GS. Specifically, we explicitly model the surface normals, Bidirectional Reflectance Distribution Function (BRDF) parameters, as well as incident lights and use Anisotropic Spherical Gaussian (ASG) to approximate the per-Gaussian Normal Distribution Function under the microfacet model. We utilize 2D Gaussian Splatting (2D-GS) as foundational primitives and apply regularization to significantly alleviate the normal estimation challenge encountered in related works. Experiments demonstrate that GlossGau achieves competitive or superior reconstruction on datasets with glossy surfaces. Compared with previous GS-based works that address the specular surface, our optimization time is considerably less.
MUSE-VL: Modeling Unified VLM through Semantic Discrete Encoding
Nov 26, 2024



We introduce MUSE-VL, a Unified Vision-Language Model through Semantic discrete Encoding for multimodal understanding and generation. Recently, the research community has begun exploring unified models for visual generation and understanding. However, existing vision tokenizers (e.g., VQGAN) only consider low-level information, which makes it difficult to align with texture semantic features. This results in high training complexity and necessitates a large amount of training data to achieve optimal performance. Additionally, their performance is still far from dedicated understanding models. This paper proposes Semantic Discrete Encoding (SDE), which effectively aligns the information of visual tokens and language tokens by adding semantic constraints to the visual tokenizer. This greatly reduces training difficulty and improves the performance of the unified model. The proposed model significantly surpasses the previous state-of-the-art in various vision-language benchmarks and achieves better performance than dedicated understanding models.
ZALM3: Zero-Shot Enhancement of Vision-Language Alignment via In-Context Information in Multi-Turn Multimodal Medical Dialogue
Sep 26, 2024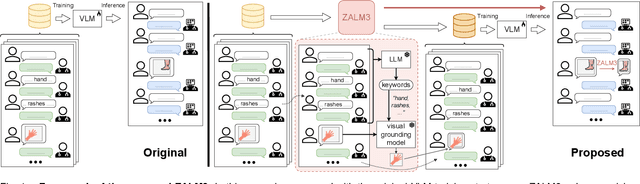
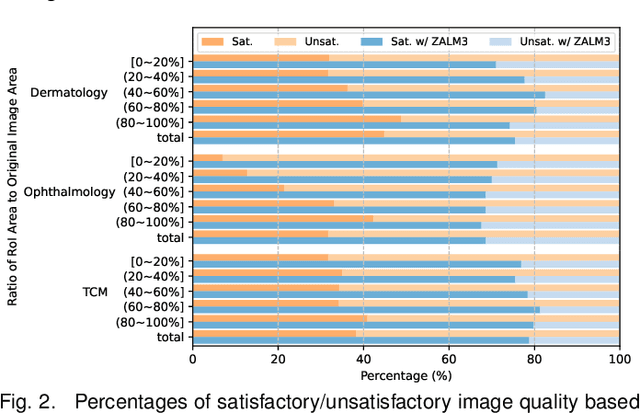
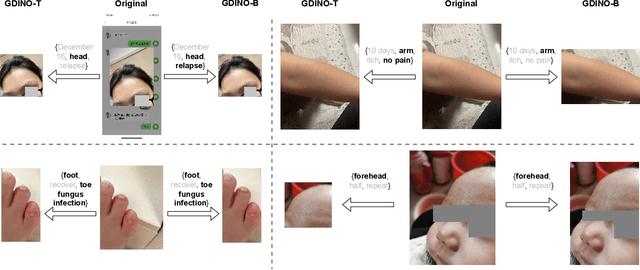
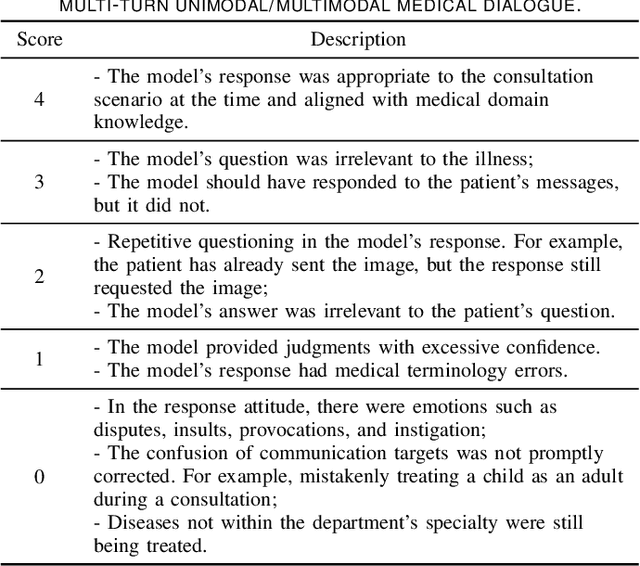
The rocketing prosperity of large language models (LLMs) in recent years has boosted the prevalence of vision-language models (VLMs) in the medical sector. In our online medical consultation scenario, a doctor responds to the texts and images provided by a patient in multiple rounds to diagnose her/his health condition, forming a multi-turn multimodal medical dialogue format. Unlike high-quality images captured by professional equipment in traditional medical visual question answering (Med-VQA), the images in our case are taken by patients' mobile phones. These images have poor quality control, with issues such as excessive background elements and the lesion area being significantly off-center, leading to degradation of vision-language alignment in the model training phase. In this paper, we propose ZALM3, a Zero-shot strategy to improve vision-language ALignment in Multi-turn Multimodal Medical dialogue. Since we observe that the preceding text conversations before an image can infer the regions of interest (RoIs) in the image, ZALM3 employs an LLM to summarize the keywords from the preceding context and a visual grounding model to extract the RoIs. The updated images eliminate unnecessary background noise and provide more effective vision-language alignment. To better evaluate our proposed method, we design a new subjective assessment metric for multi-turn unimodal/multimodal medical dialogue to provide a fine-grained performance comparison. Our experiments across three different clinical departments remarkably demonstrate the efficacy of ZALM3 with statistical significance.
Agriculture-Vision Challenge 2022 -- The Runner-Up Solution for Agricultural Pattern Recognition via Transformer-based Models
Jun 23, 2022
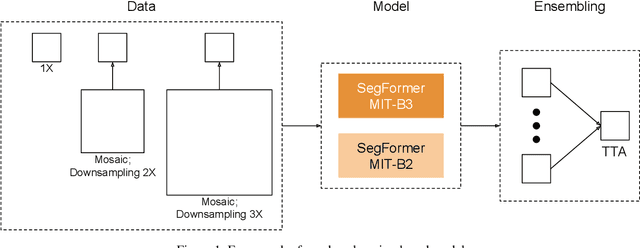
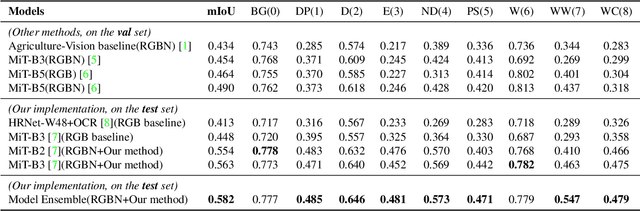
The Agriculture-Vision Challenge in CVPR is one of the most famous and competitive challenges for global researchers to break the boundary between computer vision and agriculture sectors, aiming at agricultural pattern recognition from aerial images. In this paper, we propose our solution to the third Agriculture-Vision Challenge in CVPR 2022. We leverage a data pre-processing scheme and several Transformer-based models as well as data augmentation techniques to achieve a mIoU of 0.582, accomplishing the 2nd place in this challenge.
A CNN Segmentation-Based Approach to Object Detection and Tracking in Ultrasound Scans with Application to the Vagus Nerve Detection
Jun 25, 2021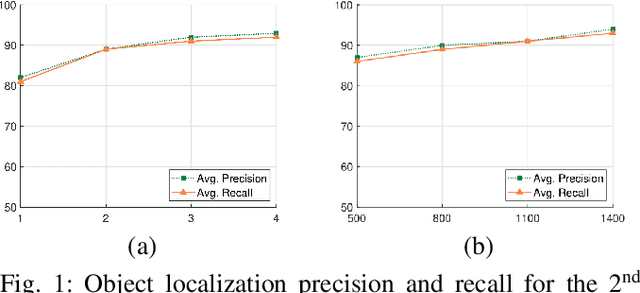
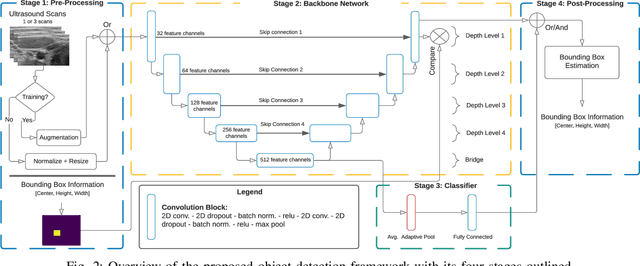
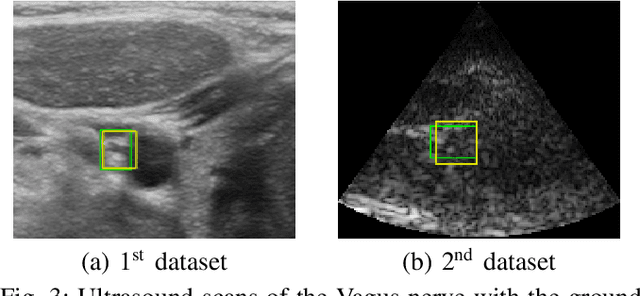
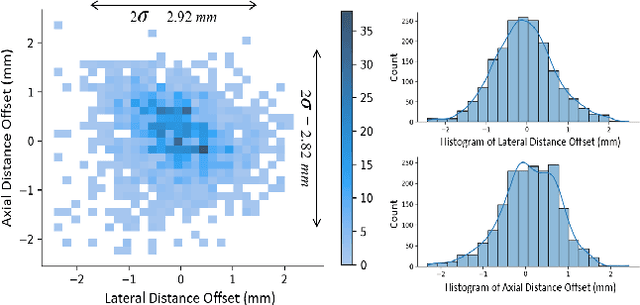
Ultrasound scanning is essential in several medical diagnostic and therapeutic applications. It is used to visualize and analyze anatomical features and structures that influence treatment plans. However, it is both labor intensive, and its effectiveness is operator dependent. Real-time accurate and robust automatic detection and tracking of anatomical structures while scanning would significantly impact diagnostic and therapeutic procedures to be consistent and efficient. In this paper, we propose a deep learning framework to automatically detect and track a specific anatomical target structure in ultrasound scans. Our framework is designed to be accurate and robust across subjects and imaging devices, to operate in real-time, and to not require a large training set. It maintains a localization precision and recall higher than 90% when trained on training sets that are as small as 20% in size of the original training set. The framework backbone is a weakly trained segmentation neural network based on U-Net. We tested the framework on two different ultrasound datasets with the aim to detect and track the Vagus nerve, where it outperformed current state-of-the-art real-time object detection networks.
Selective Feature Connection Mechanism: Concatenating Multi-layer CNN Features with a Feature Selector
Nov 15, 2018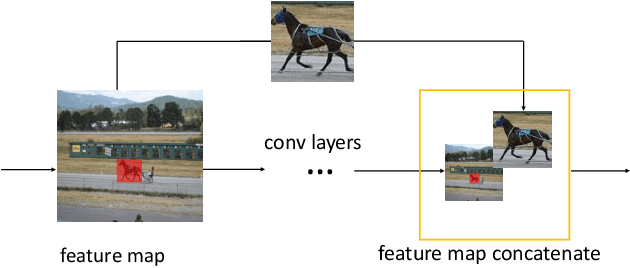

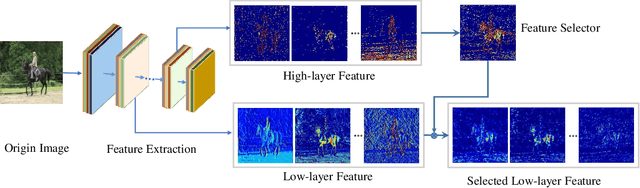

Different layers of deep convolutional neural networks(CNN) can encode different-level information. High-layer features always contain more semantic information, and low-layer features contain more detail information. However, low-layer features suffer from the background clutter and semantic ambiguity. During visual recognition, the feature combination of the low-layer and high-level features plays an important role in context modulation. Directly combining the high-layer and low-layer features, the background clutter and semantic ambiguity may be caused due to the introduction of detailed information.In this paper, we propose a general network architecture to concatenate CNN features of different layers in a simple and effective way, called Selective Feature Connection Mechanism (SFCM). Low level features are selectively linked to high-level features with an feature selector which is generated by high-level features. The proposed connection mechanism can effectively overcome the above-mentioned drawbacks. We demonstrate the effectiveness, superiority, and universal applicability of this method on many challenging computer vision tasks, such as image classification, scene text detection, and image-to-image translation.
Accurate and efficient video de-fencing using convolutional neural networks and temporal information
Jun 28, 2018
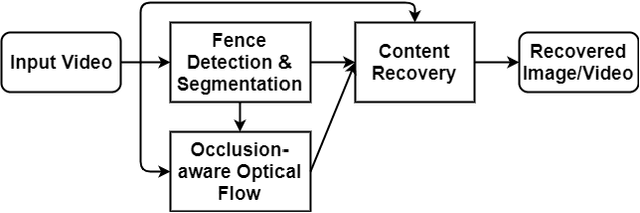
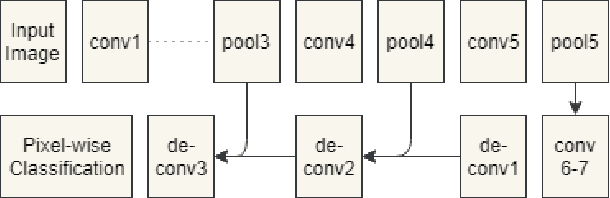

De-fencing is to eliminate the captured fence on an image or a video, providing a clear view of the scene. It has been applied for many purposes including assisting photographers and improving the performance of computer vision algorithms such as object detection and recognition. However, the state-of-the-art de-fencing methods have limited performance caused by the difficulty of fence segmentation and also suffer from the motion of the camera or objects. To overcome these problems, we propose a novel method consisting of segmentation using convolutional neural networks and a fast/robust recovery algorithm. The segmentation algorithm using convolutional neural network achieves significant improvement in the accuracy of fence segmentation. The recovery algorithm using optical flow produces plausible de-fenced images and videos. The proposed method is experimented on both our diverse and complex dataset and publicly available datasets. The experimental results demonstrate that the proposed method achieves the state-of-the-art performance for both segmentation and content recovery.