 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGST : Discriminator Guided Scene Text detector
Feb 28, 2020
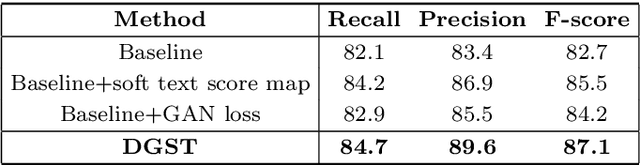
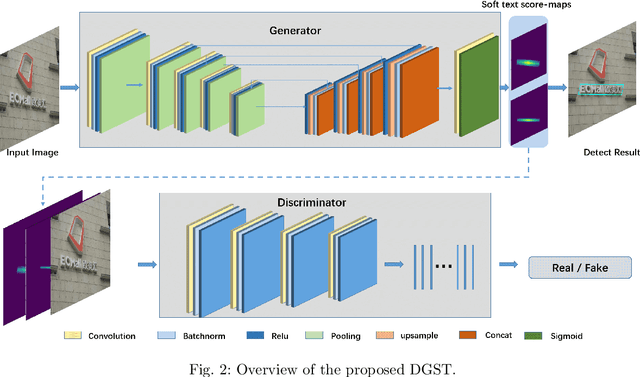
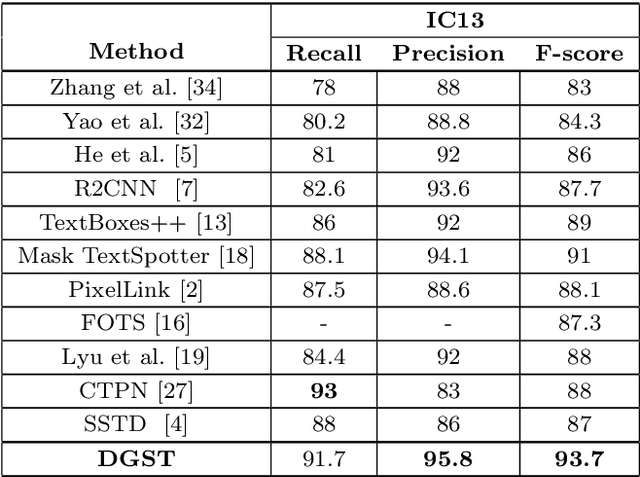
Scene text detection task has attracted considerable attention in computer vision because of its wide application. In recent years, many researchers have introduced methods of semantic segmentation into the task of scene text detection, and achieved promising results. This paper proposes a detector framework based on the conditional generative adversarial networks to improve the segmentation effect of scene text detection, called DGST (Discriminator Guided Scene Text detector). Instead of binary text score maps generated by some existing semantic segmentation based methods, we generate a multi-scale soft text score map with more information to represent the text position more reasonably, and solve the problem of text pixel adhesion in the process of text extraction. Experiments on standard datasets demonstrate that the proposed DGST brings noticeable gain and outperforms state-of-the-art methods. Specifically, it achieves an F-measure of 87% on ICDAR 2015 dataset.
Weakly Supervised Soft-detection-based Aggregation Method for Image Retrieval
Nov 27, 2018

In recent year, the compact representations based on activations of Convolutional Neural Network (CNN) achieve remarkable performance in image retrieval. Some interested object only takes up a small part of the whole image. Therefore, it is significant to extract the discriminative representations that contain regional information of pivotal small object. In this paper, we propose a novel weakly supervised soft-detection-based aggregation (SDA) method free from bounding box annotations for image retrieval. In order to highlight the certain discriminative pattern of objects and suppress the noise of background, we employ trainable soft region proposals that indicate the probability of interested object and reflect the significance of candidate regions. We conduct comprehensive experiments on standard image retrieval datasets. Our weakly supervised SDA method achieves state-of-the-art performance on most benchmarks. The results demonstrate that the proposed SDA method is effective for image retrieval.
Selective Feature Connection Mechanism: Concatenating Multi-layer CNN Features with a Feature Selector
Nov 15, 2018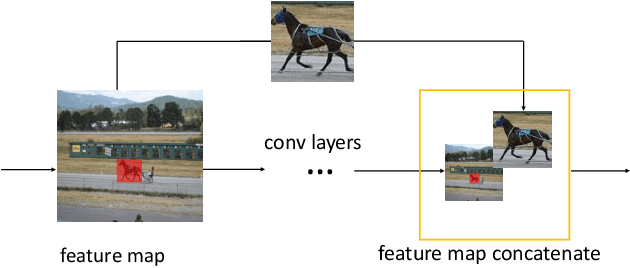

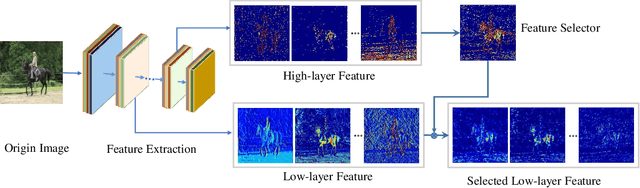

Different layers of deep convolutional neural networks(CNN) can encode different-level information. High-layer features always contain more semantic information, and low-layer features contain more detail information. However, low-layer features suffer from the background clutter and semantic ambiguity. During visual recognition, the feature combination of the low-layer and high-level features plays an important role in context modulation. Directly combining the high-layer and low-layer features, the background clutter and semantic ambiguity may be caused due to the introduction of detailed information.In this paper, we propose a general network architecture to concatenate CNN features of different layers in a simple and effective way, called Selective Feature Connection Mechanism (SFCM). Low level features are selectively linked to high-level features with an feature selector which is generated by high-level features. The proposed connection mechanism can effectively overcome the above-mentioned drawbacks. We demonstrate the effectiveness, superiority, and universal applicability of this method on many challenging computer vision tasks, such as image classification, scene text detection, and image-to-image translation.
Unsupervised Semantic-based Aggregation of Deep Convolutional Features
Apr 03, 2018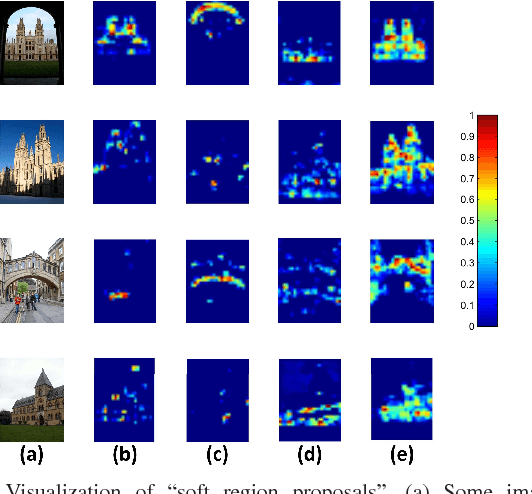
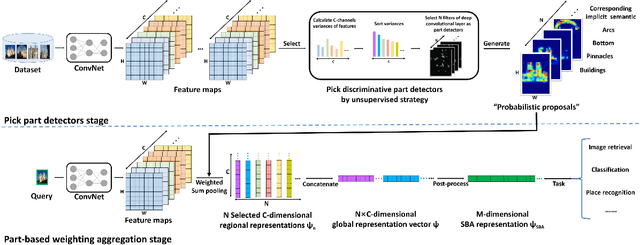
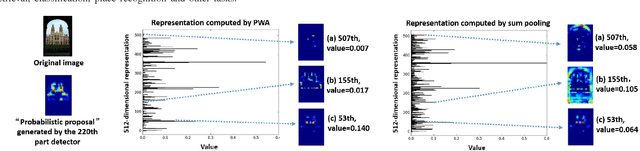

In this paper, we propose a simple but effective semantic-based aggregation (SBA) method. The proposed SBA utilizes the discriminative filters of deep convolutional layers as semantic detectors. Moreover, we propose the effective unsupervised strategy to select some semantic detectors to generate the "probabilistic proposals", which highlight certain discriminative pattern of objects and suppress the noise of background. The final global SBA representation could then be acquired by aggregating the regional representations weighted by the selected "probabilistic proposals" corresponding to various semantic content. Our unsupervised SBA is easy to generalize and achieves excellent performance on various tasks. We conduct comprehensive experiments and show that our unsupervised SBA outperforms the state-of-the-art unsupervised and supervised aggregation methods on image retrieval, place recognition and cloud classification.
Iterative Manifold Embedding Layer Learned by Incomplete Data for Large-scale Image Retrieval
Apr 03, 2018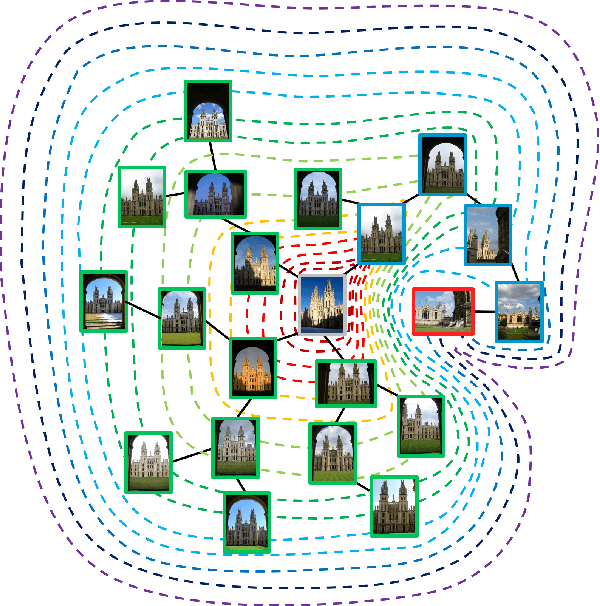
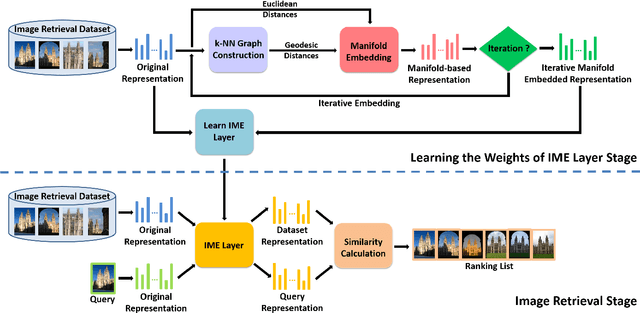
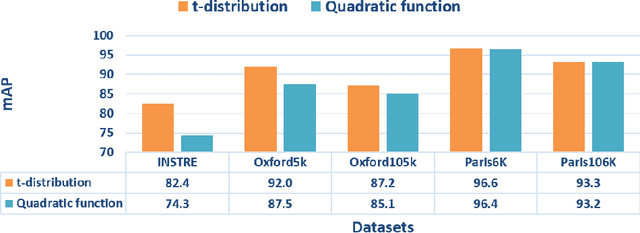
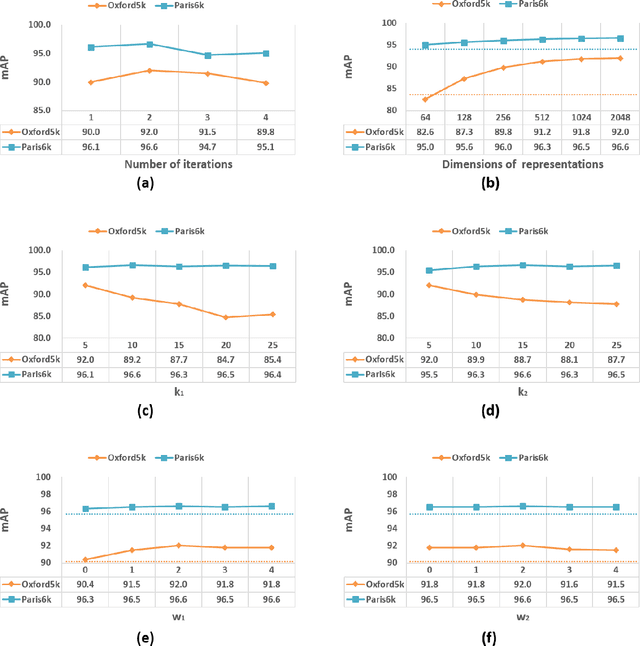
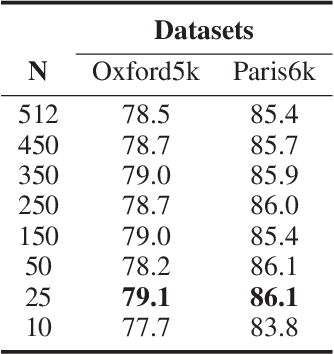
Existing manifold learning methods are not appropriate for image retrieval task, because most of them are unable to process query image and they have much additional computational cost especially for large scale database. Therefore, we propose the iterative manifold embedding (IME) layer, of which the weights are learned off-line by unsupervised strategy, to explore the intrinsic manifolds by incomplete data. On the large scale database that contains 27000 images, IME layer is more than 120 times faster than other manifold learning methods to embed the original representations at query time. We embed the original descriptors of database images which lie on manifold in a high dimensional space into manifold-based representations iteratively to generate the IME representations in off-line learning stage. According to the original descriptors and the IME representations of database images, we estimate the weights of IME layer by ridge regression. In on-line retrieval stage, we employ the IME layer to map the original representation of query image with ignorable time cost (2 milliseconds). We experiment on five public standard datasets for image retrieval. The proposed IME layer significantly outperforms related dimension reduction methods and manifold learning methods. Without post-processing, Our IME layer achieves a boost in performance of state-of-the-art image retrieval methods with post-processing on most datasets, and needs less computational cost.
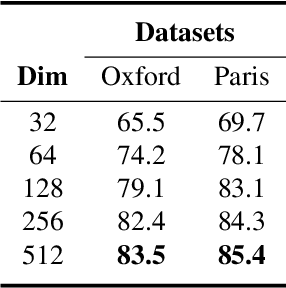
Unsupervised Part-based Weighting Aggregation of Deep Convolutional Features for Image Retrieval
Nov 29, 2017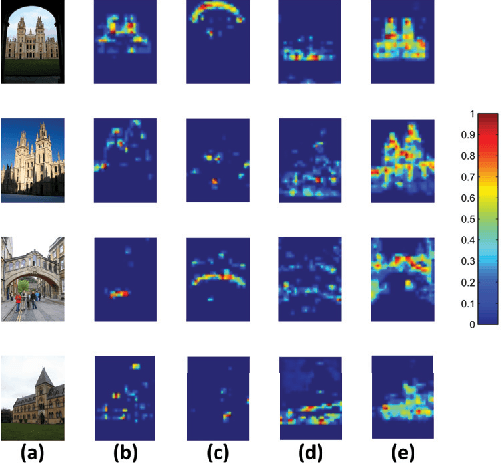
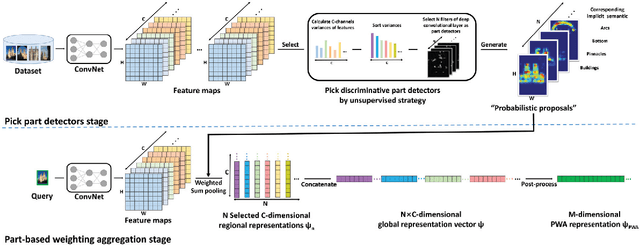
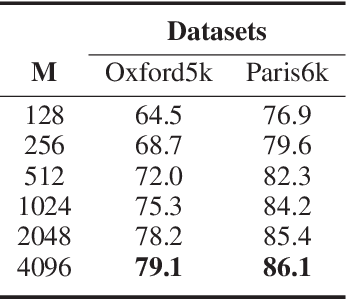
In this paper, we propose a simple but effective semantic part-based weighting aggregation (PWA) for image retrieval. The proposed PWA utilizes the discriminative filters of deep convolutional layers as part detectors. Moreover, we propose the effective unsupervised strategy to select some part detectors to generate the "probabilistic proposals", which highlight certain discriminative parts of objects and suppress the noise of background. The final global PWA representation could then be acquired by aggregating the regional representations weighted by the selected "probabilistic proposals" corresponding to various semantic content. We conduct comprehensive experiments on four standard datasets and show that our unsupervised PWA outperforms the state-of-the-art unsupervised and supervised aggregation methods. Code is available at https://github.com/XJhaoren/PWA.