 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering LLMs with Parameterized Skills for Adversarial Long-Horizon Planning
Sep 16, 2025Recent advancements in Large Language Models(LLMs) have led to the development of LLM-based AI agents. A key challenge is the creation of agents that can effectively ground themselves in complex, adversarial long-horizon environments. Existing methods mainly focus on (1) using LLMs as policies to interact with the environment through generating low-level feasible actions, and (2) utilizing LLMs to generate high-level tasks or language guides to stimulate action generation. However, the former struggles to generate reliable actions, while the latter relies heavily on expert experience to translate high-level tasks into specific action sequences. To address these challenges, we introduce the Plan with Language, Act with Parameter (PLAP) planning framework that facilitates the grounding of LLM-based agents in long-horizon environments. The PLAP method comprises three key components: (1) a skill library containing environment-specific parameterized skills, (2) a skill planner powered by LLMs, and (3) a skill executor converting the parameterized skills into executable action sequences. We implement PLAP in MicroRTS, a long-horizon real-time strategy game that provides an unfamiliar and challenging environment for LLMs. The experimental results demonstrate the effectiveness of PLAP. In particular, GPT-4o-driven PLAP in a zero-shot setting outperforms 80% of baseline agents, and Qwen2-72B-driven PLAP, with carefully crafted few-shot examples, surpasses the top-tier scripted agent, CoacAI. Additionally, we design comprehensive evaluation metrics and test 6 closed-source and 2 open-source LLMs within the PLAP framework, ultimately releasing an LLM leaderboard ranking long-horizon skill planning ability. Our code is available at https://github.com/AI-Research-TeamX/PLAP.
Self-Guided Function Calling in Large Language Models via Stepwise Experience Recall
Aug 21, 2025Function calling enables large language models (LLMs) to interact with external systems by leveraging tools and APIs. When faced with multi-step tool usage, LLMs still struggle with tool selection, parameter generation, and tool-chain planning. Existing methods typically rely on manually designing task-specific demonstrations, or retrieving from a curated library. These approaches demand substantial expert effort and prompt engineering becomes increasingly complex and inefficient as tool diversity and task difficulty scale. To address these challenges, we propose a self-guided method, Stepwise Experience Recall (SEER), which performs fine-grained, stepwise retrieval from a continually updated experience pool. Instead of relying on static or manually curated library, SEER incrementally augments the experience pool with past successful trajectories, enabling continuous expansion of the pool and improved model performance over time. Evaluated on the ToolQA benchmark, SEER achieves an average improvement of 6.1\% on easy and 4.7\% on hard questions. We further test SEER on $\tau$-bench, which includes two real-world domains. Powered by Qwen2.5-7B and Qwen2.5-72B models, SEER demonstrates substantial accuracy gains of 7.44\% and 23.38\%, respectively.
Strategy-Augmented Planning for Large Language Models via Opponent Exploitation
May 13, 2025Efficiently modeling and exploiting opponents is a long-standing challenge in adversarial domains. Large Language Models (LLMs) trained on extensive textual data have recently demonstrated outstanding performance in general tasks, introducing new research directions for opponent modeling. Some studies primarily focus on directly using LLMs to generate decisions based on the elaborate prompt context that incorporates opponent descriptions, while these approaches are limited to scenarios where LLMs possess adequate domain expertise. To address that, we introduce a two-stage Strategy-Augmented Planning (SAP) framework that significantly enhances the opponent exploitation capabilities of LLM-based agents by utilizing a critical component, the Strategy Evaluation Network (SEN). Specifically, in the offline stage, we construct an explicit strategy space and subsequently collect strategy-outcome pair data for training the SEN network. During the online phase, SAP dynamically recognizes the opponent's strategies and greedily exploits them by searching best response strategy on the well-trained SEN, finally translating strategy to a course of actions by carefully designed prompts. Experimental results show that SAP exhibits robust generalization capabilities, allowing it to perform effectively not only against previously encountered opponent strategies but also against novel, unseen strategies. In the MicroRTS environment, SAP achieves a 85.35\% performance improvement over baseline methods and matches the competitiveness of reinforcement learning approaches against state-of-the-art (SOTA) rule-based AI.
TUMS: Enhancing Tool-use Abilities of LLMs with Multi-structure Handlers
May 13, 2025Recently, large language models(LLMs) have played an increasingly important role in solving a wide range of NLP tasks, leveraging their capabilities of natural language understanding and generating. Integration with external tools further enhances LLMs' effectiveness, providing more precise, timely, and specialized responses. However, LLMs still encounter difficulties with non-executable actions and improper actions, which are primarily attributed to incorrect parameters. The process of generating parameters by LLMs is confined to the tool level, employing the coarse-grained strategy without considering the different difficulties of various tools. To address this issue, we propose TUMS, a novel framework designed to enhance the tool-use capabilities of LLMs by transforming tool-level processing into parameter-level processing. Specifically, our framework consists of four key components: (1) an intent recognizer that identifies the user's intent to help LLMs better understand the task; (2) a task decomposer that breaks down complex tasks into simpler subtasks, each involving a tool call; (3) a subtask processor equipped with multi-structure handlers to generate accurate parameters; and (4) an executor. Our empirical studies have evidenced the effectiveness and efficiency of the TUMS framework with an average of 19.6\% and 50.6\% improvement separately on easy and hard benchmarks of ToolQA, meanwhile, we demonstrated the key contribution of each part with ablation experiments, offering more insights and stimulating future research on Tool-augmented LLMs.
DGST : Discriminator Guided Scene Text detector
Feb 28, 2020
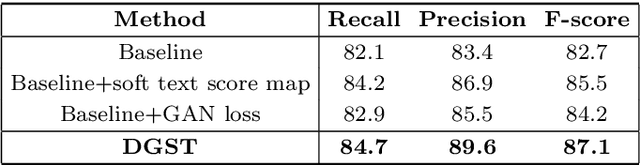
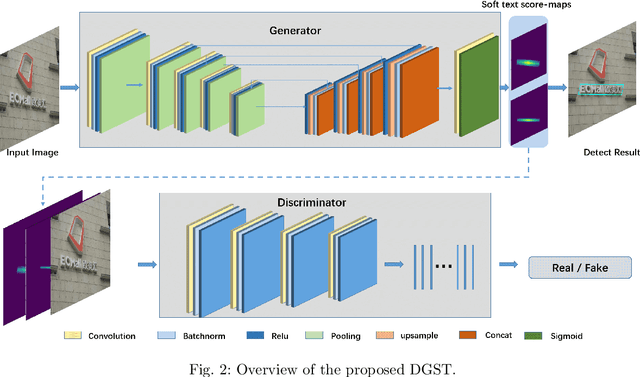
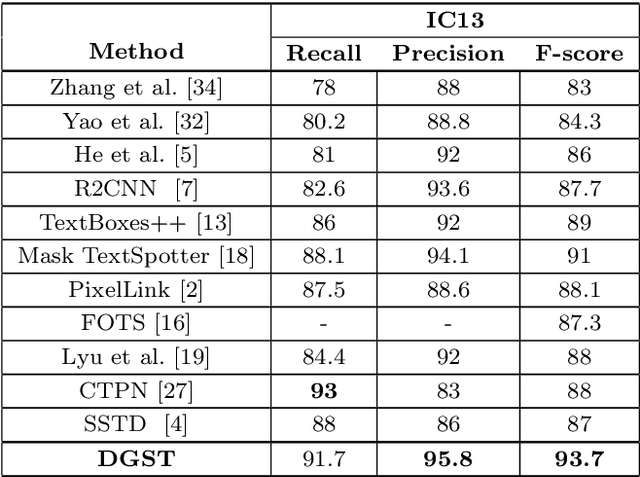
Scene text detection task has attracted considerable attention in computer vision because of its wide application. In recent years, many researchers have introduced methods of semantic segmentation into the task of scene text detection, and achieved promising results. This paper proposes a detector framework based on the conditional generative adversarial networks to improve the segmentation effect of scene text detection, called DGST (Discriminator Guided Scene Text detector). Instead of binary text score maps generated by some existing semantic segmentation based methods, we generate a multi-scale soft text score map with more information to represent the text position more reasonably, and solve the problem of text pixel adhesion in the process of text extraction. Experiments on standard datasets demonstrate that the proposed DGST brings noticeable gain and outperforms state-of-the-art methods. Specifically, it achieves an F-measure of 87% on ICDAR 2015 dataset.
Multi-Fusion Chinese WordNet (MCW) : Compound of Machine Learning and Manual Correction
Feb 05, 2020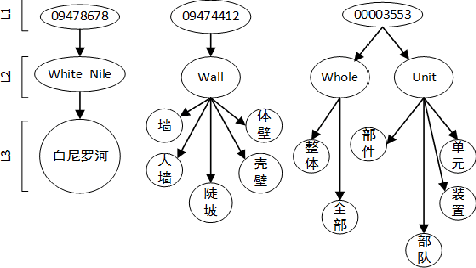
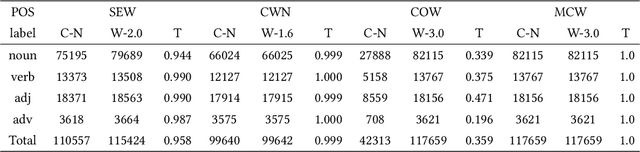
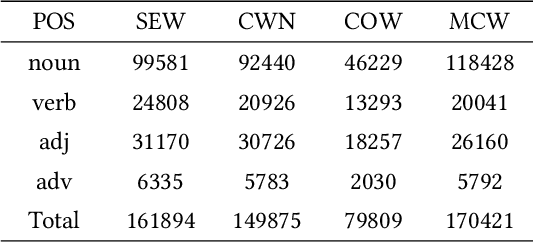
Princeton WordNet (PWN) is a lexicon-semantic network based on cognitive linguistics, which promotes the development of natural language processing. Based on PWN, five Chinese wordnets have been developed to solve the problems of syntax and semantics. They include: Northeastern University Chinese WordNet (NEW), Sinica Bilingual Ontological WordNet (BOW), Southeast University Chinese WordNet (SEW), Taiwan University Chinese WordNet (CWN), Chinese Open WordNet (COW). By using them, we found that these word networks have low accuracy and coverage, and cannot completely portray the semantic network of PWN. So we decided to make a new Chinese wordnet called Multi-Fusion Chinese Wordnet (MCW) to make up those shortcomings. The key idea is to extend the SEW with the help of Oxford bilingual dictionary and Xinhua bilingual dictionary, and then correct it. More specifically, we used machine learning and manual adjustment in our corrections. Two standards were formulated to help our work. We conducted experiments on three tasks including relatedness calculation, word similarity and word sense disambiguation for the comparison of lemma's accuracy, at the same time, coverage also was compared. The results indicate that MCW can benefit from coverage and accuracy via our method. However, it still has room for improvement, especially with lemmas. In the future, we will continue to enhance the accuracy of MCW and expand the concepts in it.