 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Graph for Multi-Agent LLM Calibration
May 28, 2026Multi-agent LLM systems often treat agreement as evidence: when many agents in a panel give the same answer, that answer is assumed to be more reliable. We show that this assumption can fail after agents communicate. Communication can induce correlated failures and false consensus, so the same vote share may reflect reliable agreement in one topology but over-confidence in another. We propose CAGE-CAL, a counterfactual agent-graph calibration framework for multi-agent LLMs. For each query, CAGE-CAL compares an observed post-communication agent graph with a matched counterfactual no-communication graph, capturing both pairwise failure correlations and group-level dependencies. Rather than simply counting how many agents agree, CAGE-CAL estimates the counterfactual shift between observed and no-communication dependence, and calibrates confidence accordingly. Across five benchmarks, CAGE-CAL improves reliability discrimination with competitive ECE, and its calibrated confidence further improves topology selection over the best fixed-topology strategy.
RICE-PO: Turning Retrieval Interactions into Credit Signals for Reasoning Agents
May 25, 2026Retrieval is increasingly moving from one-shot matching toward interactive reasoning, where language agents iteratively inspect evidence, reformulate queries, and search again. Training such agents raises a credit-assignment challenge: executable actions such as queries or summaries can be directly evaluated by the retriever, while latent reasoning steps are not directly observable and only affect future executable actions. This asymmetry makes outcome-level reward assignment unreliable, as the same final reward may credit reasoning steps that did not actually shape retrieval success. We propose RICE-PO, a critic-free policy optimization framework that converts retrieval interactions into localized learning signals. RICE-PO selects high-uncertainty executable actions as anchors, evaluates local counterfactual branches using retrieval metrics, and propagates credit to latent reasoning steps only when reasoning-to-action influence is strong and future residual effects are stable. On BRIGHT and BEIR, RICE-PO consistently outperforms prompt-based agents and group-based RL baselines under the same retriever setting. These results show that the structure of agent-environment interaction itself can provide useful supervision for training reasoning-based retrieval agents.
In-Context Optimization for Retrieval-Augmented Generation: A Gradient-Descent Perspective
May 25, 2026In-context learning has recently been linked to implicit gradient descent in linear self-attention models, suggesting that context can induce a forward-pass update. Retrieval-augmented generation (RAG) also relies on context, but retrieved documents are usually treated as static evidence rather than signals for adaptation. We study RAG as an in-context optimization process. First, we show that one linear self-attention layer can implement one gradient-descent step on a unified linearized RAG objective covering both projection-based and dot-product retrieval interfaces. This gives an exact regime where retrieval-augmented prediction and in-context optimization coincide. We use this result not as a literal model of LLM computation, but as a guide for adapting the interaction between queries and retrieved evidence. We then test the boundary of this correspondence: it remains stable under controlled linear extensions, but becomes feature-distribution dependent under nonlinear architectures. Finally, we turn this view into a lightweight method for frozen RAG LLMs. The method keeps the retriever and backbone fixed, and predicts a context-conditioned update to a generator-side evidence-use interface. Across seven QA benchmarks, two retrievers, and two frozen LLM backbones, this forward-only update improves a shared-interface baseline, transfers to held-out tasks, and approaches test-time gradient adaptation at much lower per-query cost.
Efficient and Effective Internal Memory Retrieval for LLM-Based Healthcare Prediction
Apr 08, 2026Large language models (LLMs) hold significant promise for healthcare, yet their reliability in high-stakes clinical settings is often compromised by hallucinations and a lack of granular medical context. While Retrieval Augmented Generation (RAG) can mitigate these issues, standard supervised pipelines require computationally intensive searches over massive external knowledge bases, leading to high latency that is impractical for time-sensitive care. To address this, we introduce Keys to Knowledge (K2K), a novel framework that replaces external retrieval with internal, key-based knowledge access. By encoding essential clinical information directly into the model's parameter space, K2K enables rapid retrieval from internal key-value memory without inference-time overhead. We further enhance retrieval quality through activation-guided probe construction and cross-attention reranking. Experimental results demonstrate that K2K achieves state-of-the-art performance across four benchmark healthcare outcome prediction datasets.
Digital Skin, Digital Bias: Uncovering Tone-Based Biases in LLMs and Emoji Embeddings
Apr 08, 2026Skin-toned emojis are crucial for fostering personal identity and social inclusion in online communication. As AI models, particularly Large Language Models (LLMs), increasingly mediate interactions on web platforms, the risk that these systems perpetuate societal biases through their representation of such symbols is a significant concern. This paper presents the first large-scale comparative study of bias in skin-toned emoji representations across two distinct model classes. We systematically evaluate dedicated emoji embedding models (emoji2vec, emoji-sw2v) against four modern LLMs (Llama, Gemma, Qwen, and Mistral). Our analysis first reveals a critical performance gap: while LLMs demonstrate robust support for skin tone modifiers, widely-used specialized emoji models exhibit severe deficiencies. More importantly, a multi-faceted investigation into semantic consistency, representational similarity, sentiment polarity, and core biases uncovers systemic disparities. We find evidence of skewed sentiment and inconsistent meanings associated with emojis across different skin tones, highlighting latent biases within these foundational models. Our findings underscore the urgent need for developers and platforms to audit and mitigate these representational harms, ensuring that AI's role on the web promotes genuine equity rather than reinforcing societal biases.
Self-evolving AI agents for protein discovery and directed evolution
Mar 28, 2026Protein scientific discovery is bottlenecked by the manual orchestration of information and algorithms, while general agents are insufficient in complex domain projects. VenusFactory2 provides an autonomous framework that shifts from static tool usage to dynamic workflow synthesis via a self-evolving multi-agent infrastructure to address protein-related demands. It outperforms a set of well-known agents on the VenusAgentEval benchmark, and autonomously organizes the discovery and optimization of proteins from a single natural language prompt.
Rank-and-Reason: Multi-Agent Collaboration Accelerates Zero-Shot Protein Mutation Prediction
Feb 03, 2026Zero-shot mutation prediction is vital for low-resource protein engineering, yet existing protein language models (PLMs) often yield statistically confident results that ignore fundamental biophysical constraints. Currently, selecting candidates for wet-lab validation relies on manual expert auditing of PLM outputs, a process that is inefficient, subjective, and highly dependent on domain expertise. To address this, we propose Rank-and-Reason (VenusRAR), a two-stage agentic framework to automate this workflow and maximize expected wet-lab fitness. In the Rank-Stage, a Computational Expert and Virtual Biologist aggregate a context-aware multi-modal ensemble, establishing a new Spearman correlation record of 0.551 (vs. 0.518) on ProteinGym. In the Reason-Stage, an agentic Expert Panel employs chain-of-thought reasoning to audit candidates against geometric and structural constraints, improving the Top-5 Hit Rate by up to 367% on ProteinGym-DMS99. The wet-lab validation on Cas12i3 nuclease further confirms the framework's efficacy, achieving a 46.7% positive rate and identifying two novel mutants with 4.23-fold and 5.05-fold activity improvements. Code and datasets are released on GitHub (https://github.com/ai4protein/VenusRAR/).
GLEN-Bench: A Graph-Language based Benchmark for Nutritional Health
Jan 26, 2026Nutritional interventions are important for managing chronic health conditions, but current computational methods provide limited support for personalized dietary guidance. We identify three key gaps: (1) dietary pattern studies often ignore real-world constraints such as socioeconomic status, comorbidities, and limited food access; (2) recommendation systems rarely explain why a particular food helps a given patient; and (3) no unified benchmark evaluates methods across the connected tasks needed for nutritional interventions. We introduce GLEN-Bench, the first comprehensive graph-language based benchmark for nutritional health assessment. We combine NHANES health records, FNDDS food composition data, and USDA food-access metrics to build a knowledge graph that links demographics, health conditions, dietary behaviors, poverty-related constraints, and nutrient needs. We test the benchmark using opioid use disorder, where models must detect subtle nutritional differences across disease stages. GLEN-Bench includes three linked tasks: risk detection identifies at-risk individuals from dietary and socioeconomic patterns; recommendation suggests personalized foods that meet clinical needs within resource constraints; and question answering provides graph-grounded, natural-language explanations to facilitate comprehension. We evaluate these graph-language approaches, including graph neural networks, large language models, and hybrid architectures, to establish solid baselines and identify practical design choices. Our analysis identifies clear dietary patterns linked to health risks, providing insights that can guide practical interventions.
NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
Hollywood Town: Long-Video Generation via Cross-Modal Multi-Agent Orchestration
Oct 25, 2025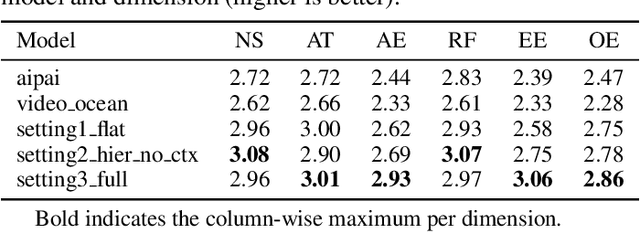
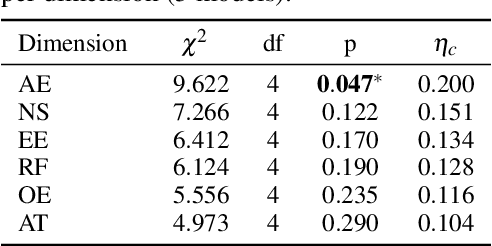
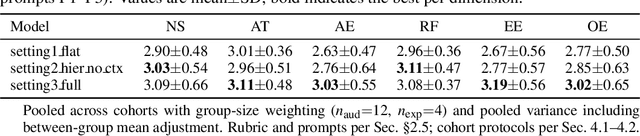
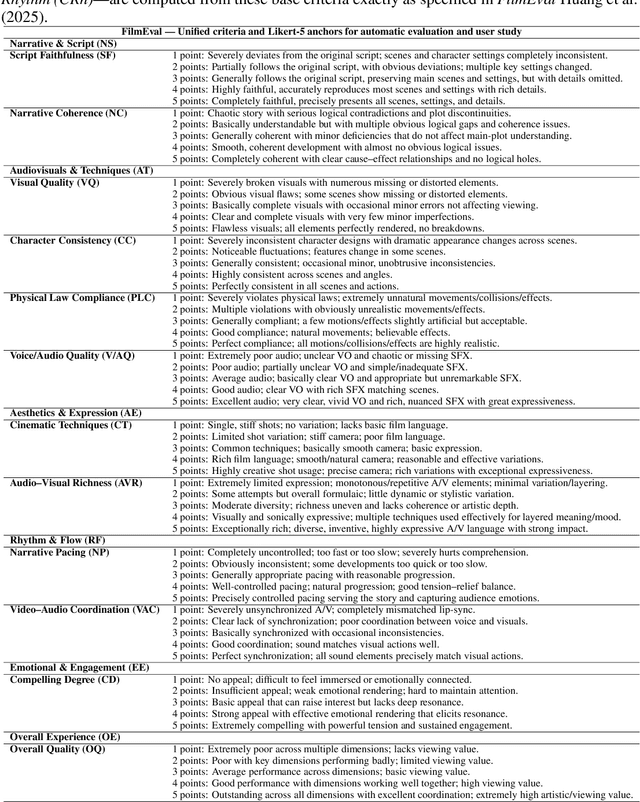
Recent advancements in multi-agent systems have demonstrated significant potential for enhancing creative task performance, such as long video generation. This study introduces three innovations to improve multi-agent collaboration. First, we propose OmniAgent, a hierarchical, graph-based multi-agent framework for long video generation that leverages a film-production-inspired architecture to enable modular specialization and scalable inter-agent collaboration. Second, inspired by context engineering, we propose hypergraph nodes that enable temporary group discussions among agents lacking sufficient context, reducing individual memory requirements while ensuring adequate contextual information. Third, we transition from directed acyclic graphs (DAGs) to directed cyclic graphs with limited retries, allowing agents to reflect and refine outputs iteratively, thereby improving earlier stages through feedback from subsequent nodes. These contributions lay the groundwork for developing more robust multi-agent systems in creative tasks.