 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal World Modeling for Robot Control
Jan 29, 2026This work highlights that video world modeling, alongside vision-language pre-training, establishes a fresh and independent foundation for robot learning. Intuitively, video world models provide the ability to imagine the near future by understanding the causality between actions and visual dynamics. Inspired by this, we introduce LingBot-VA, an autoregressive diffusion framework that learns frame prediction and policy execution simultaneously. Our model features three carefully crafted designs: (1) a shared latent space, integrating vision and action tokens, driven by a Mixture-of-Transformers (MoT) architecture, (2) a closed-loop rollout mechanism, allowing for ongoing acquisition of environmental feedback with ground-truth observations, (3) an asynchronous inference pipeline, parallelizing action prediction and motor execution to support efficient control. We evaluate our model on both simulation benchmarks and real-world scenarios, where it shows significant promise in long-horizon manipulation, data efficiency in post-training, and strong generalizability to novel configurations. The code and model are made publicly available to facilitate the community.
Polybasic Speculative Decoding Through a Theoretical Perspective
Oct 30, 2025



Inference latency stands as a critical bottleneck in the large-scale deployment of Large Language Models (LLMs). Speculative decoding methods have recently shown promise in accelerating inference without compromising the output distribution. However, existing work typically relies on a dualistic draft-verify framework and lacks rigorous theoretical grounding. In this paper, we introduce a novel \emph{polybasic} speculative decoding framework, underpinned by a comprehensive theoretical analysis. Specifically, we prove a fundamental theorem that characterizes the optimal inference time for multi-model speculative decoding systems, shedding light on how to extend beyond the dualistic approach to a more general polybasic paradigm. Through our theoretical investigation of multi-model token generation, we expose and optimize the interplay between model capabilities, acceptance lengths, and overall computational cost. Our framework supports both standalone implementation and integration with existing speculative techniques, leading to accelerated performance in practice. Experimental results across multiple model families demonstrate that our approach yields speedup ratios ranging from $3.31\times$ to $4.01\times$ for LLaMA2-Chat 7B, up to $3.87 \times$ for LLaMA3-8B, up to $4.43 \times$ for Vicuna-7B and up to $3.85 \times$ for Qwen2-7B -- all while preserving the original output distribution. We release our theoretical proofs and implementation code to facilitate further investigation into polybasic speculative decoding.
StereoCarla: A High-Fidelity Driving Dataset for Generalizable Stereo
Sep 16, 2025Stereo matching plays a crucial role in enabling depth perception for autonomous driving and robotics. While recent years have witnessed remarkable progress in stereo matching algorithms, largely driven by learning-based methods and synthetic datasets, the generalization performance of these models remains constrained by the limited diversity of existing training data. To address these challenges, we present StereoCarla, a high-fidelity synthetic stereo dataset specifically designed for autonomous driving scenarios. Built on the CARLA simulator, StereoCarla incorporates a wide range of camera configurations, including diverse baselines, viewpoints, and sensor placements as well as varied environmental conditions such as lighting changes, weather effects, and road geometries. We conduct comprehensive cross-domain experiments across four standard evaluation datasets (KITTI2012, KITTI2015, Middlebury, ETH3D) and demonstrate that models trained on StereoCarla outperform those trained on 11 existing stereo datasets in terms of generalization accuracy across multiple benchmarks. Furthermore, when integrated into multi-dataset training, StereoCarla contributes substantial improvements to generalization accuracy, highlighting its compatibility and scalability. This dataset provides a valuable benchmark for developing and evaluating stereo algorithms under realistic, diverse, and controllable settings, facilitating more robust depth perception systems for autonomous vehicles. Code can be available at https://github.com/XiandaGuo/OpenStereo, and data can be available at https://xiandaguo.net/StereoCarla.
Residual Learning Inspired Crossover Operator and Strategy Enhancements for Evolutionary Multitasking
Mar 27, 2025

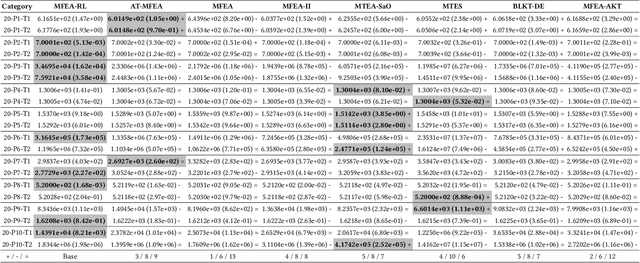

In evolutionary multitasking, strategies such as crossover operators and skill factor assignment are critical for effective knowledge transfer. Existing improvements to crossover operators primarily focus on low-dimensional variable combinations, such as arithmetic crossover or partially mapped crossover, which are insufficient for modeling complex high-dimensional interactions.Moreover, static or semi-dynamic crossover strategies fail to adapt to the dynamic dependencies among tasks. In addition, current Multifactorial Evolutionary Algorithm frameworks often rely on fixed skill factor assignment strategies, lacking flexibility. To address these limitations, this paper proposes the Multifactorial Evolutionary Algorithm-Residual Learning (MFEA-RL) method based on residual learning. The method employs a Very Deep Super-Resolution (VDSR) model to generate high-dimensional residual representations of individuals, enhancing the modeling of complex relationships within dimensions. A ResNet-based mechanism dynamically assigns skill factors to improve task adaptability, while a random mapping mechanism efficiently performs crossover operations and mitigates the risk of negative transfer. Theoretical analysis and experimental results show that MFEA-RL outperforms state-of-the-art multitasking algorithms. It excels in both convergence and adaptability on standard evolutionary multitasking benchmarks, including CEC2017-MTSO and WCCI2020-MTSO. Additionally, its effectiveness is validated through a real-world application scenario.
VenusFactory: A Unified Platform for Protein Engineering Data Retrieval and Language Model Fine-Tuning
Mar 19, 2025Natural language processing (NLP) has significantly influenced scientific domains beyond human language, including protein engineering, where pre-trained protein language models (PLMs) have demonstrated remarkable success. However, interdisciplinary adoption remains limited due to challenges in data collection, task benchmarking, and application. This work presents VenusFactory, a versatile engine that integrates biological data retrieval, standardized task benchmarking, and modular fine-tuning of PLMs. VenusFactory supports both computer science and biology communities with choices of both a command-line execution and a Gradio-based no-code interface, integrating $40+$ protein-related datasets and $40+$ popular PLMs. All implementations are open-sourced on https://github.com/tyang816/VenusFactory.
SR-FoT: A Syllogistic-Reasoning Framework of Thought for Large Language Models Tackling Knowledge-based Reasoning Tasks
Jan 20, 2025Deductive reasoning is a crucial logical capability that assists us in solving complex problems based on existing knowledge. Although augmented by Chain-of-Thought prompts, Large Language Models (LLMs) might not follow the correct reasoning paths. Enhancing the deductive reasoning abilities of LLMs, and leveraging their extensive built-in knowledge for various reasoning tasks, remains an open question. Attempting to mimic the human deductive reasoning paradigm, we propose a multi-stage Syllogistic-Reasoning Framework of Thought (SR-FoT) that enables LLMs to perform syllogistic deductive reasoning to handle complex knowledge-based reasoning tasks. Our SR-FoT begins by interpreting the question and then uses the interpretation and the original question to propose a suitable major premise. It proceeds by generating and answering minor premise questions in two stages to match the minor premises. Finally, it guides LLMs to use the previously generated major and minor premises to perform syllogistic deductive reasoning to derive the answer to the original question. Extensive and thorough experiments on knowledge-based reasoning tasks have demonstrated the effectiveness and advantages of our SR-FoT.
Stereo Anything: Unifying Stereo Matching with Large-Scale Mixed Data
Nov 21, 2024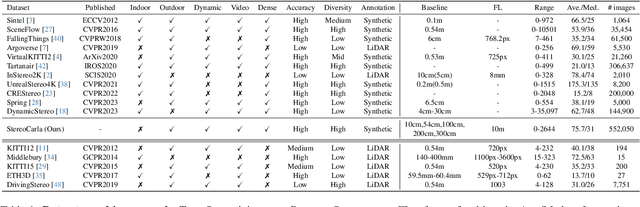
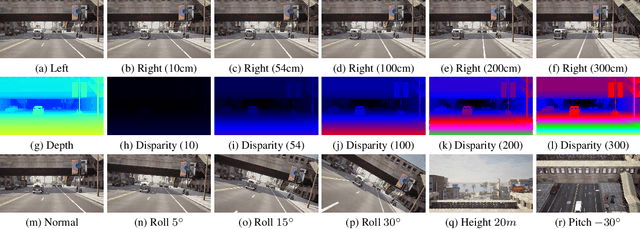

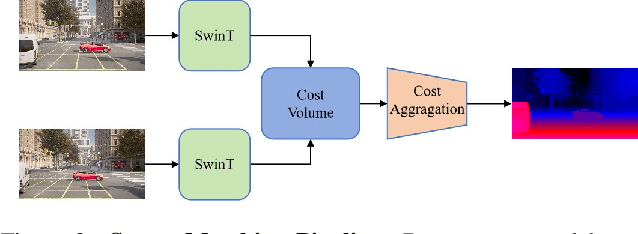
Stereo matching has been a pivotal component in 3D vision, aiming to find corresponding points between pairs of stereo images to recover depth information. In this work, we introduce StereoAnything, a highly practical solution for robust stereo matching. Rather than focusing on a specialized model, our goal is to develop a versatile foundational model capable of handling stereo images across diverse environments. To this end, we scale up the dataset by collecting labeled stereo images and generating synthetic stereo pairs from unlabeled monocular images. To further enrich the model's ability to generalize across different conditions, we introduce a novel synthetic dataset that complements existing data by adding variability in baselines, camera angles, and scene types. We extensively evaluate the zero-shot capabilities of our model on five public datasets, showcasing its impressive ability to generalize to new, unseen data. Code will be available at \url{https://github.com/XiandaGuo/OpenStereo}.
Retrieval-Enhanced Mutation Mastery: Augmenting Zero-Shot Prediction of Protein Language Model
Oct 28, 2024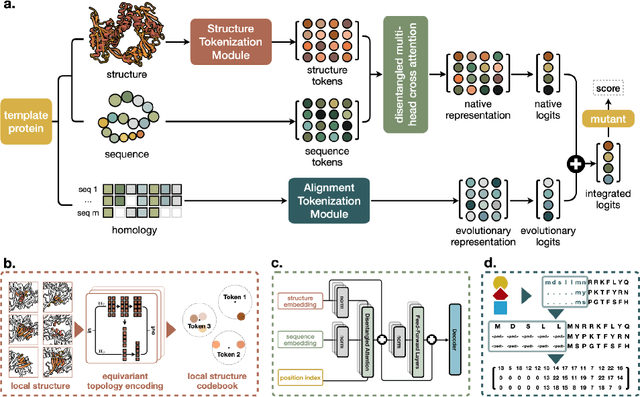
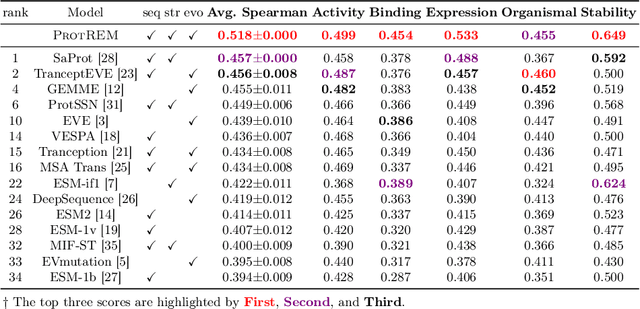
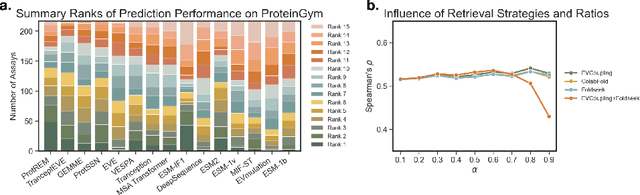
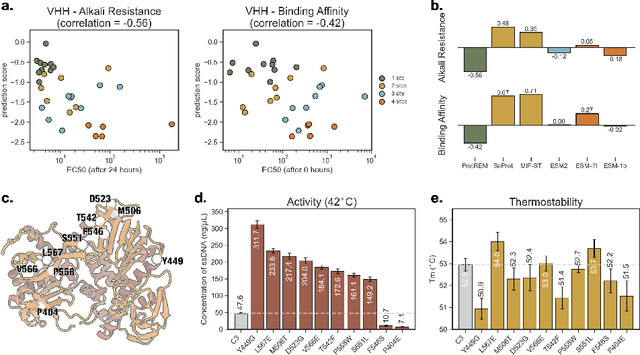
Enzyme engineering enables the modification of wild-type proteins to meet industrial and research demands by enhancing catalytic activity, stability, binding affinities, and other properties. The emergence of deep learning methods for protein modeling has demonstrated superior results at lower costs compared to traditional approaches such as directed evolution and rational design. In mutation effect prediction, the key to pre-training deep learning models lies in accurately interpreting the complex relationships among protein sequence, structure, and function. This study introduces a retrieval-enhanced protein language model for comprehensive analysis of native properties from sequence and local structural interactions, as well as evolutionary properties from retrieved homologous sequences. The state-of-the-art performance of the proposed ProtREM is validated on over 2 million mutants across 217 assays from an open benchmark (ProteinGym). We also conducted post-hoc analyses of the model's ability to improve the stability and binding affinity of a VHH antibody. Additionally, we designed 10 new mutants on a DNA polymerase and conducted wet-lab experiments to evaluate their enhanced activity at higher temperatures. Both in silico and experimental evaluations confirmed that our method provides reliable predictions of mutation effects, offering an auxiliary tool for biologists aiming to evolve existing enzymes. The implementation is publicly available at https://github.com/tyang816/ProtREM.
Refining Packing and Shuffling Strategies for Enhanced Performance in Generative Language Models
Aug 19, 2024



Packing and shuffling tokens is a common practice in training auto-regressive language models (LMs) to prevent overfitting and improve efficiency. Typically documents are concatenated to chunks of maximum sequence length (MSL) and then shuffled. However setting the atom size, the length for each data chunk accompanied by random shuffling, to MSL may lead to contextual incoherence due to tokens from different documents being packed into the same chunk. An alternative approach is to utilize padding, another common data packing strategy, to avoid contextual incoherence by only including one document in each shuffled chunk. To optimize both packing strategies (concatenation vs padding), we investigated the optimal atom size for shuffling and compared their performance and efficiency. We found that matching atom size to MSL optimizes performance for both packing methods (concatenation and padding), and padding yields lower final perplexity (higher performance) than concatenation at the cost of more training steps and lower compute efficiency. This trade-off informs the choice of packing methods in training language models.
Towards CausalGPT: A Multi-Agent Approach for Faithful Knowledge Reasoning via Promoting Causal Consistency in LLMs
Sep 04, 2023Despite advancements in LLMs, knowledge-based reasoning remains a longstanding issue due to the fragility of knowledge recall and inference. Existing methods primarily encourage LLMs to autonomously plan and solve problems or to extensively sample reasoning chains without addressing the conceptual and inferential fallacies. Attempting to alleviate inferential fallacies and drawing inspiration from multi-agent collaboration, we present a framework to increase faithfulness and causality for knowledge-based reasoning. Specifically, we propose to employ multiple intelligent agents (i.e., reasoners and an evaluator) to work collaboratively in a reasoning-and-consensus paradigm for elevated reasoning faithfulness. The reasoners focus on providing solutions with human-like causality to solve open-domain problems. On the other hand, the \textit{evaluator} agent scrutinizes if a solution is deducible from a non-causal perspective and if it still holds when challenged by a counterfactual candidate. According to the extensive and comprehensive evaluations on a variety of knowledge reasoning tasks (e.g., science question answering and commonsense reasoning), our framework outperforms all compared state-of-the-art approaches by large margins.