 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoCarla: A High-Fidelity Driving Dataset for Generalizable Stereo
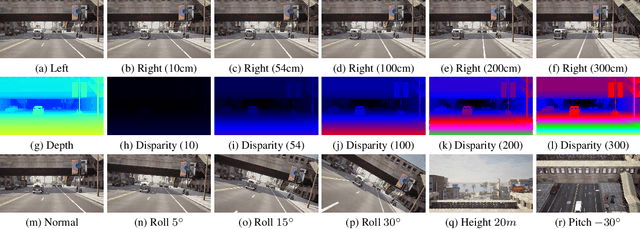
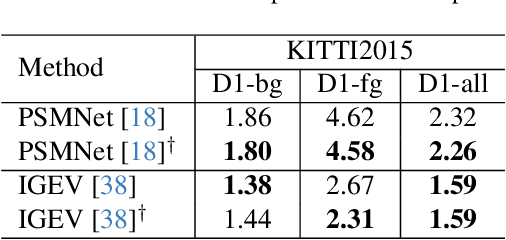
Sep 16, 2025Stereo matching plays a crucial role in enabling depth perception for autonomous driving and robotics. While recent years have witnessed remarkable progress in stereo matching algorithms, largely driven by learning-based methods and synthetic datasets, the generalization performance of these models remains constrained by the limited diversity of existing training data. To address these challenges, we present StereoCarla, a high-fidelity synthetic stereo dataset specifically designed for autonomous driving scenarios. Built on the CARLA simulator, StereoCarla incorporates a wide range of camera configurations, including diverse baselines, viewpoints, and sensor placements as well as varied environmental conditions such as lighting changes, weather effects, and road geometries. We conduct comprehensive cross-domain experiments across four standard evaluation datasets (KITTI2012, KITTI2015, Middlebury, ETH3D) and demonstrate that models trained on StereoCarla outperform those trained on 11 existing stereo datasets in terms of generalization accuracy across multiple benchmarks. Furthermore, when integrated into multi-dataset training, StereoCarla contributes substantial improvements to generalization accuracy, highlighting its compatibility and scalability. This dataset provides a valuable benchmark for developing and evaluating stereo algorithms under realistic, diverse, and controllable settings, facilitating more robust depth perception systems for autonomous vehicles. Code can be available at https://github.com/XiandaGuo/OpenStereo, and data can be available at https://xiandaguo.net/StereoCarla.
RecipeGen: A Step-Aligned Multimodal Benchmark for Real-World Recipe Generation
Jun 07, 2025



Creating recipe images is a key challenge in food computing, with applications in culinary education and multimodal recipe assistants. However, existing datasets lack fine-grained alignment between recipe goals, step-wise instructions, and visual content. We present RecipeGen, the first large-scale, real-world benchmark for recipe-based Text-to-Image (T2I), Image-to-Video (I2V), and Text-to-Video (T2V) generation. RecipeGen contains 26,453 recipes, 196,724 images, and 4,491 videos, covering diverse ingredients, cooking procedures, styles, and dish types. We further propose domain-specific evaluation metrics to assess ingredient fidelity and interaction modeling, benchmark representative T2I, I2V, and T2V models, and provide insights for future recipe generation models. Project page is available now.
Stereo Anything: Unifying Stereo Matching with Large-Scale Mixed Data
Nov 21, 2024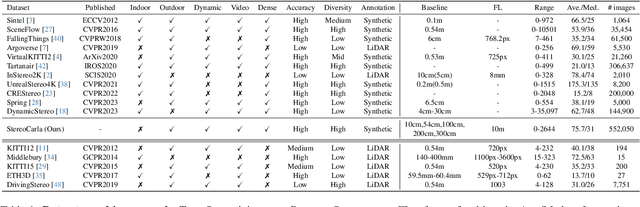

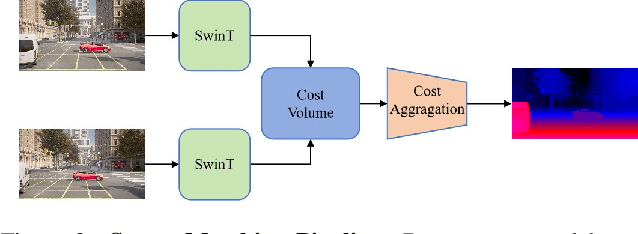
Stereo matching has been a pivotal component in 3D vision, aiming to find corresponding points between pairs of stereo images to recover depth information. In this work, we introduce StereoAnything, a highly practical solution for robust stereo matching. Rather than focusing on a specialized model, our goal is to develop a versatile foundational model capable of handling stereo images across diverse environments. To this end, we scale up the dataset by collecting labeled stereo images and generating synthetic stereo pairs from unlabeled monocular images. To further enrich the model's ability to generalize across different conditions, we introduce a novel synthetic dataset that complements existing data by adding variability in baselines, camera angles, and scene types. We extensively evaluate the zero-shot capabilities of our model on five public datasets, showcasing its impressive ability to generalize to new, unseen data. Code will be available at \url{https://github.com/XiandaGuo/OpenStereo}.
DriveMLLM: A Benchmark for Spatial Understanding with Multimodal Large Language Models in Autonomous Driving
Nov 20, 2024Autonomous driving requires a comprehensive understanding of 3D environments to facilitate high-level tasks such as motion prediction, planning, and mapping. In this paper, we introduce DriveMLLM, a benchmark specifically designed to evaluate the spatial understanding capabilities of multimodal large language models (MLLMs) in autonomous driving. DriveMLLM includes 2,734 front-facing camera images and introduces both absolute and relative spatial reasoning tasks, accompanied by linguistically diverse natural language questions. To measure MLLMs' performance, we propose novel evaluation metrics focusing on spatial understanding. We evaluate several state-of-the-art MLLMs on DriveMLLM, and our results reveal the limitations of current models in understanding complex spatial relationships in driving contexts. We believe these findings underscore the need for more advanced MLLM-based spatial reasoning methods and highlight the potential for DriveMLLM to drive further research in autonomous driving. Code will be available at \url{https://github.com/XiandaGuo/Drive-MLLM}.
LightStereo: Channel Boost Is All Your Need for Efficient 2D Cost Aggregation
Jun 28, 2024We present LightStereo, a cutting-edge stereo-matching network crafted to accelerate the matching process. Departing from conventional methodologies that rely on aggregating computationally intensive 4D costs, LightStereo adopts the 3D cost volume as a lightweight alternative. While similar approaches have been explored previously, our breakthrough lies in enhancing performance through a dedicated focus on the channel dimension of the 3D cost volume, where the distribution of matching costs is encapsulated. Our exhaustive exploration has yielded plenty of strategies to amplify the capacity of the pivotal dimension, ensuring both precision and efficiency. We compare the proposed LightStereo with existing state-of-the-art methods across various benchmarks, which demonstrate its superior performance in speed, accuracy, and resource utilization. LightStereo achieves a competitive EPE metric in the SceneFlow datasets while demanding a minimum of only 22 GFLOPs, with an inference time of just 17 ms. Our comprehensive analysis reveals the effect of 2D cost aggregation for stereo matching, paving the way for real-world applications of efficient stereo systems. Code will be available at \url{https://github.com/XiandaGuo/OpenStereo}.
Instruct Large Language Models to Drive like Humans
Jun 11, 2024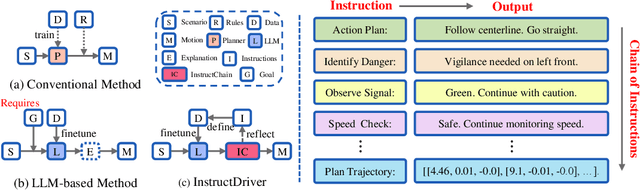
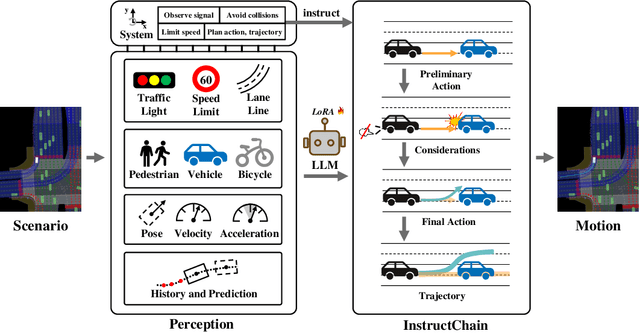

Motion planning in complex scenarios is the core challenge in autonomous driving. Conventional methods apply predefined rules or learn from driving data to plan the future trajectory. Recent methods seek the knowledge preserved in large language models (LLMs) and apply them in the driving scenarios. Despite the promising results, it is still unclear whether the LLM learns the underlying human logic to drive. In this paper, we propose an InstructDriver method to transform LLM into a motion planner with explicit instruction tuning to align its behavior with humans. We derive driving instruction data based on human logic (e.g., do not cause collisions) and traffic rules (e.g., proceed only when green lights). We then employ an interpretable InstructChain module to further reason the final planning reflecting the instructions. Our InstructDriver allows the injection of human rules and learning from driving data, enabling both interpretability and data scalability. Different from existing methods that experimented on closed-loop or simulated settings, we adopt the real-world closed-loop motion planning nuPlan benchmark for better evaluation. InstructDriver demonstrates the effectiveness of the LLM planner in a real-world closed-loop setting. Our code is publicly available at https://github.com/bonbon-rj/InstructDriver.
OpenStereo: A Comprehensive Benchmark for Stereo Matching and Strong Baseline
Dec 01, 2023
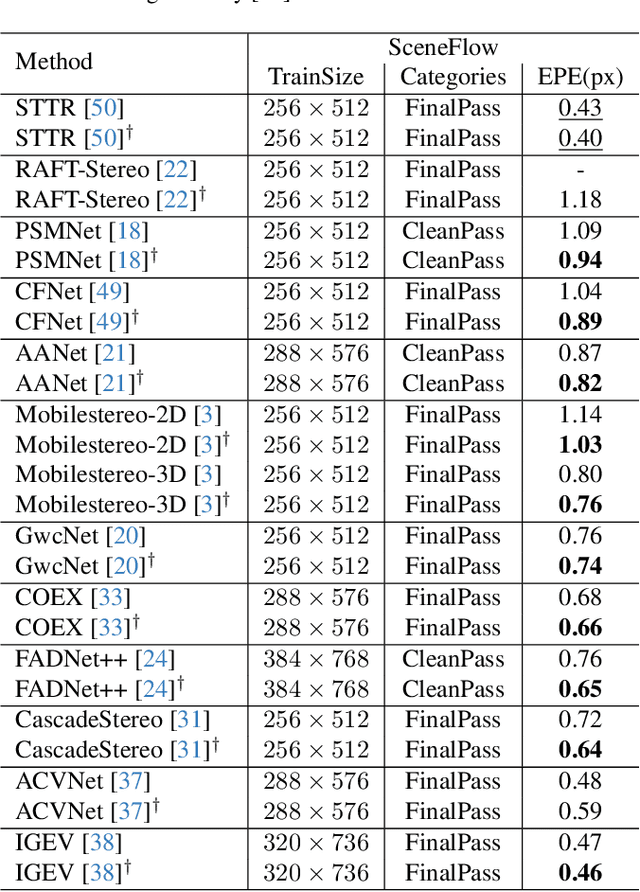
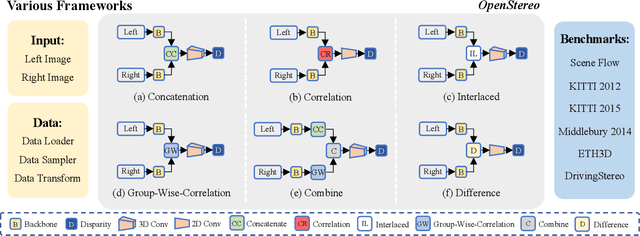
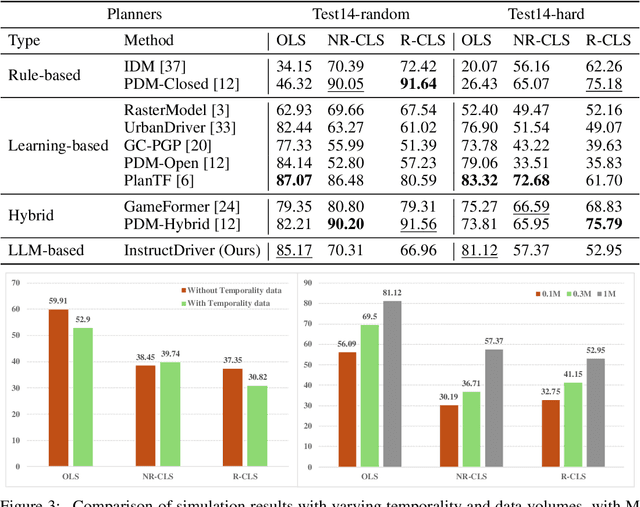
Stereo matching, a pivotal technique in computer vision, plays a crucial role in robotics, autonomous navigation, and augmented reality. Despite the development of numerous impressive methods in recent years, replicating their results and determining the most suitable architecture for practical application remains challenging. Addressing this gap, our paper introduces a comprehensive benchmark focusing on practical applicability rather than solely on performance enhancement. Specifically, we develop a flexible and efficient stereo matching codebase, called OpenStereo. OpenStereo includes training and inference codes of more than 12 network models, making it, to our knowledge, the most complete stereo matching toolbox available. Based on OpenStereo, we conducted experiments on the SceneFlow dataset and have achieved or surpassed the performance metrics reported in the original paper. Additionally, we conduct an in-depth revisitation of recent developments in stereo matching through ablative experiments. These investigations inspired the creation of StereoBase, a simple yet strong baseline model. Our extensive comparative analyses of StereoBase against numerous contemporary stereo matching methods on the SceneFlow dataset demonstrate its remarkably strong performance. The source code is available at https://github.com/XiandaGuo/OpenStereo.
Grid-SD2E: A General Grid-Feedback in a System for Cognitive Learning
Apr 04, 2023Comprehending how the brain interacts with the external world through generated neural signals is crucial for determining its working mechanism, treating brain diseases, and understanding intelligence. Although many theoretical models have been proposed, they have thus far been difficult to integrate and develop. In this study, we were inspired in part by grid cells in creating a more general and robust grid module and constructing an interactive and self-reinforcing cognitive system together with Bayesian reasoning, an approach called space-division and exploration-exploitation with grid-feedback (Grid-SD2E). Here, a grid module can be used as an interaction medium between the outside world and a system, as well as a self-reinforcement medium within the system. The space-division and exploration-exploitation (SD2E) receives the 0/1 signals of a grid through its space-division (SD) module. The system described in this paper is also a theoretical model derived from experiments conducted by other researchers and our experience on neural decoding. Herein, we analyse the rationality of the system based on the existing theories in both neuroscience and cognitive science, and attempt to propose special and general rules to explain the different interactions between people and between people and the external world. What's more, based on this model, the smallest computing unit is extracted, which is analogous to a single neuron in the brain.
A Simple Baseline for Supervised Surround-view Depth Estimation
Mar 14, 2023



Depth estimation has been widely studied and serves as the fundamental step of 3D perception for autonomous driving. Though significant progress has been made for monocular depth estimation in the past decades, these attempts are mainly conducted on the KITTI benchmark with only front-view cameras, which ignores the correlations across surround-view cameras. In this paper, we propose S3Depth, a Simple Baseline for Supervised Surround-view Depth Estimation, to jointly predict the depth maps across multiple surrounding cameras. Specifically, we employ a global-to-local feature extraction module which combines CNN with transformer layers for enriched representations. Further, the Adjacent-view Attention mechanism is proposed to enable the intra-view and inter-view feature propagation. The former is achieved by the self-attention module within each view, while the latter is realized by the adjacent attention module, which computes the attention across multi-cameras to exchange the multi-scale representations across surround-view feature maps. Extensive experiments show that our method achieves superior performance over existing state-of-the-art methods on both DDAD and nuScenes datasets.