 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Attention Yields Accurate Results for Tabular Data
Feb 18, 2025



Tabular data inherently exhibits significant feature heterogeneity, but existing transformer-based methods lack specialized mechanisms to handle this property. To bridge the gap, we propose MAYA, an encoder-decoder transformer-based framework. In the encoder, we design a Mixture of Attention (MOA) that constructs multiple parallel attention branches and averages the features at each branch, effectively fusing heterogeneous features while limiting parameter growth. Additionally, we employ collaborative learning with a dynamic consistency weight constraint to produce more robust representations. In the decoder stage, cross-attention is utilized to seamlessly integrate tabular data with corresponding label features. This dual-attention mechanism effectively captures both intra-instance and inter-instance interactions. We evaluate the proposed method on a wide range of datasets and compare it with other state-of-the-art transformer-based methods. Extensive experiments demonstrate that our model achieves superior performance among transformer-based methods in both tabular classification and regression tasks.
GUNet: A Graph Convolutional Network United Diffusion Model for Stable and Diversity Pose Generation
Sep 18, 2024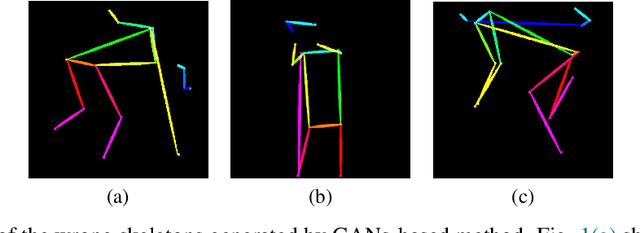



Pose skeleton images are an important reference in pose-controllable image generation. In order to enrich the source of skeleton images, recent works have investigated the generation of pose skeletons based on natural language. These methods are based on GANs. However, it remains challenging to perform diverse, structurally correct and aesthetically pleasing human pose skeleton generation with various textual inputs. To address this problem, we propose a framework with GUNet as the main model, PoseDiffusion. It is the first generative framework based on a diffusion model and also contains a series of variants fine-tuned based on a stable diffusion model. PoseDiffusion demonstrates several desired properties that outperform existing methods. 1) Correct Skeletons. GUNet, a denoising model of PoseDiffusion, is designed to incorporate graphical convolutional neural networks. It is able to learn the spatial relationships of the human skeleton by introducing skeletal information during the training process. 2) Diversity. We decouple the key points of the skeleton and characterise them separately, and use cross-attention to introduce textual conditions. Experimental results show that PoseDiffusion outperforms existing SoTA algorithms in terms of stability and diversity of text-driven pose skeleton generation. Qualitative analyses further demonstrate its superiority for controllable generation in Stable Diffusion.
OpenStereo: A Comprehensive Benchmark for Stereo Matching and Strong Baseline
Dec 01, 2023
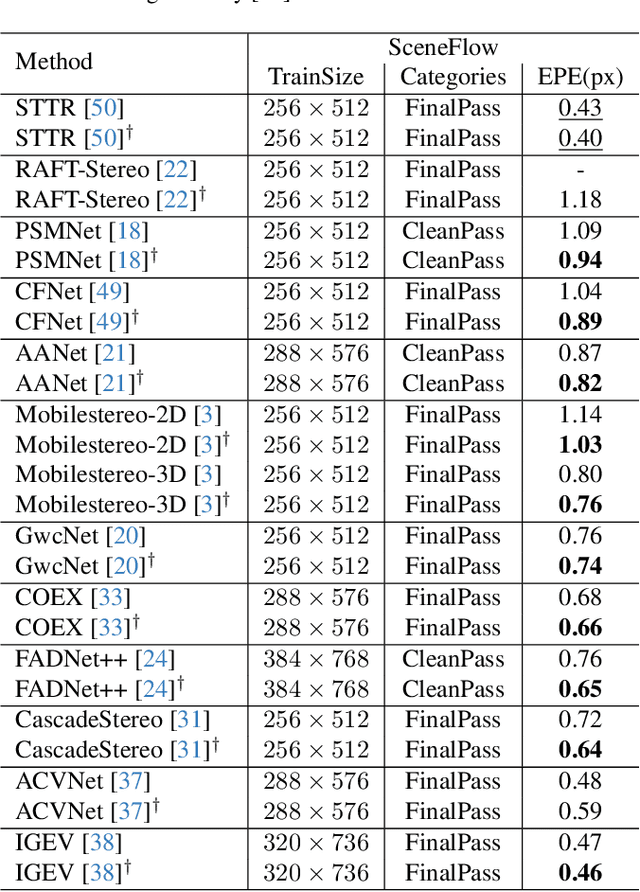
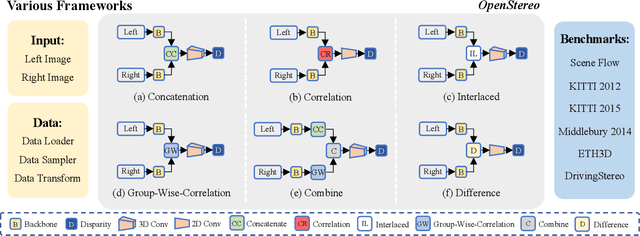
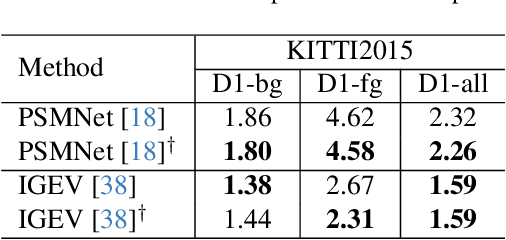
Stereo matching, a pivotal technique in computer vision, plays a crucial role in robotics, autonomous navigation, and augmented reality. Despite the development of numerous impressive methods in recent years, replicating their results and determining the most suitable architecture for practical application remains challenging. Addressing this gap, our paper introduces a comprehensive benchmark focusing on practical applicability rather than solely on performance enhancement. Specifically, we develop a flexible and efficient stereo matching codebase, called OpenStereo. OpenStereo includes training and inference codes of more than 12 network models, making it, to our knowledge, the most complete stereo matching toolbox available. Based on OpenStereo, we conducted experiments on the SceneFlow dataset and have achieved or surpassed the performance metrics reported in the original paper. Additionally, we conduct an in-depth revisitation of recent developments in stereo matching through ablative experiments. These investigations inspired the creation of StereoBase, a simple yet strong baseline model. Our extensive comparative analyses of StereoBase against numerous contemporary stereo matching methods on the SceneFlow dataset demonstrate its remarkably strong performance. The source code is available at https://github.com/XiandaGuo/OpenStereo.
DyGait: Exploiting Dynamic Representations for High-performance Gait Recognition
Mar 27, 2023
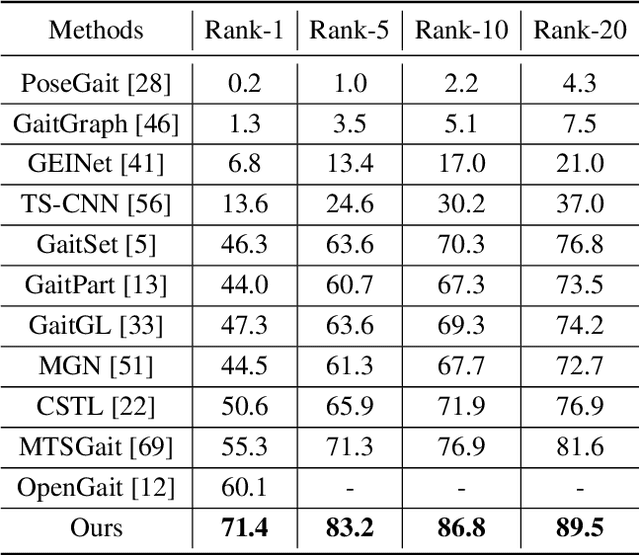

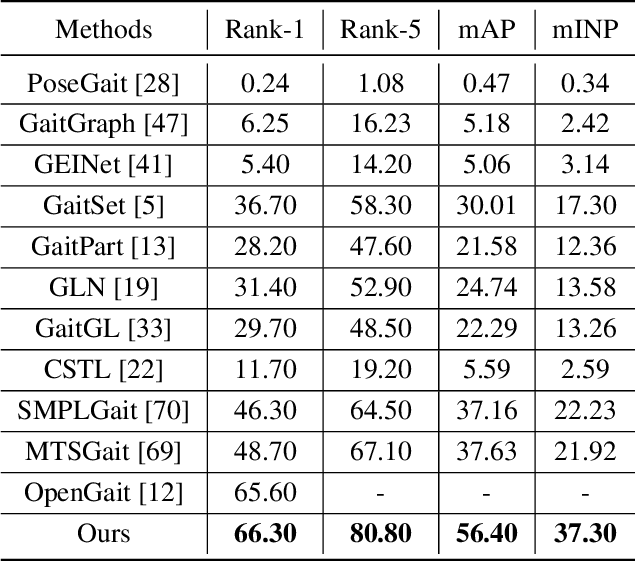
Gait recognition is a biometric technology that recognizes the identity of humans through their walking patterns. Compared with other biometric technologies, gait recognition is more difficult to disguise and can be applied to the condition of long-distance without the cooperation of subjects. Thus, it has unique potential and wide application for crime prevention and social security. At present, most gait recognition methods directly extract features from the video frames to establish representations. However, these architectures learn representations from different features equally but do not pay enough attention to dynamic features, which refers to a representation of dynamic parts of silhouettes over time (e.g. legs). Since dynamic parts of the human body are more informative than other parts (e.g. bags) during walking, in this paper, we propose a novel and high-performance framework named DyGait. This is the first framework on gait recognition that is designed to focus on the extraction of dynamic features. Specifically, to take full advantage of the dynamic information, we propose a Dynamic Augmentation Module (DAM), which can automatically establish spatial-temporal feature representations of the dynamic parts of the human body. The experimental results show that our DyGait network outperforms other state-of-the-art gait recognition methods. It achieves an average Rank-1 accuracy of 71.4% on the GREW dataset, 66.3% on the Gait3D dataset, 98.4% on the CASIA-B dataset and 98.3% on the OU-MVLP dataset.
A Simple Baseline for Supervised Surround-view Depth Estimation
Mar 14, 2023



Depth estimation has been widely studied and serves as the fundamental step of 3D perception for autonomous driving. Though significant progress has been made for monocular depth estimation in the past decades, these attempts are mainly conducted on the KITTI benchmark with only front-view cameras, which ignores the correlations across surround-view cameras. In this paper, we propose S3Depth, a Simple Baseline for Supervised Surround-view Depth Estimation, to jointly predict the depth maps across multiple surrounding cameras. Specifically, we employ a global-to-local feature extraction module which combines CNN with transformer layers for enriched representations. Further, the Adjacent-view Attention mechanism is proposed to enable the intra-view and inter-view feature propagation. The former is achieved by the self-attention module within each view, while the latter is realized by the adjacent attention module, which computes the attention across multi-cameras to exchange the multi-scale representations across surround-view feature maps. Extensive experiments show that our method achieves superior performance over existing state-of-the-art methods on both DDAD and nuScenes datasets.
Gait Recognition in the Wild: A Benchmark
May 05, 2022



Gait benchmarks empower the research community to train and evaluate high-performance gait recognition systems. Even though growing efforts have been devoted to cross-view recognition, academia is restricted by current existing databases captured in the controlled environment. In this paper, we contribute a new benchmark for Gait REcognition in the Wild (GREW). The GREW dataset is constructed from natural videos, which contains hundreds of cameras and thousands of hours streams in open systems. With tremendous manual annotations, the GREW consists of 26K identities and 128K sequences with rich attributes for unconstrained gait recognition. Moreover, we add a distractor set of over 233K sequences, making it more suitable for real-world applications. Compared with prevailing predefined cross-view datasets, the GREW has diverse and practical view variations, as well as more natural challenging factors. To the best of our knowledge, this is the first large-scale dataset for gait recognition in the wild. Equipped with this benchmark, we dissect the unconstrained gait recognition problem. Representative appearance-based and model-based methods are explored, and comprehensive baselines are established. Experimental results show (1) The proposed GREW benchmark is necessary for training and evaluating gait recognizer in the wild. (2) For state-of-the-art gait recognition approaches, there is a lot of room for improvement. (3) The GREW benchmark can be used as effective pre-training for controlled gait recognition. Benchmark website is https://www.grew-benchmark.org/.
WebFace260M: A Benchmark for Million-Scale Deep Face Recognition
Apr 21, 2022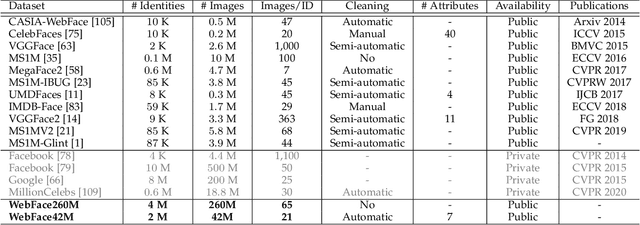

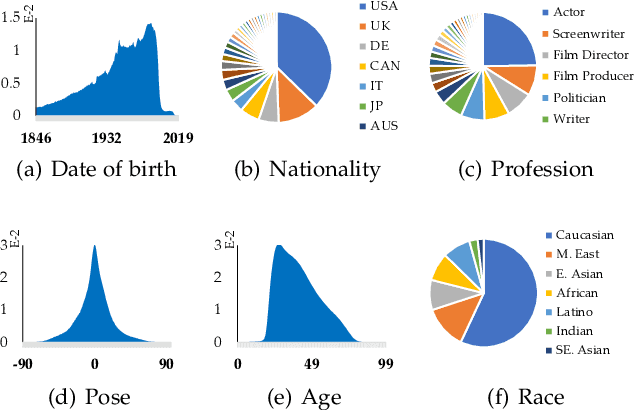
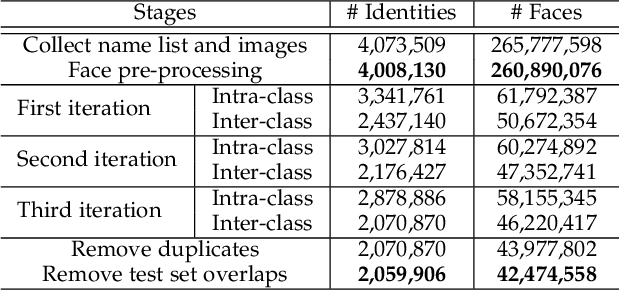
Face benchmarks empower the research community to train and evaluate high-performance face recognition systems. In this paper, we contribute a new million-scale recognition benchmark, containing uncurated 4M identities/260M faces (WebFace260M) and cleaned 2M identities/42M faces (WebFace42M) training data, as well as an elaborately designed time-constrained evaluation protocol. Firstly, we collect 4M name lists and download 260M faces from the Internet. Then, a Cleaning Automatically utilizing Self-Training (CAST) pipeline is devised to purify the tremendous WebFace260M, which is efficient and scalable. To the best of our knowledge, the cleaned WebFace42M is the largest public face recognition training set and we expect to close the data gap between academia and industry. Referring to practical deployments, Face Recognition Under Inference Time conStraint (FRUITS) protocol and a new test set with rich attributes are constructed. Besides, we gather a large-scale masked face sub-set for biometrics assessment under COVID-19. For a comprehensive evaluation of face matchers, three recognition tasks are performed under standard, masked and unbiased settings, respectively. Equipped with this benchmark, we delve into million-scale face recognition problems. A distributed framework is developed to train face recognition models efficiently without tampering with the performance. Enabled by WebFace42M, we reduce 40% failure rate on the challenging IJB-C set and rank 3rd among 430 entries on NIST-FRVT. Even 10% data (WebFace4M) shows superior performance compared with the public training sets. Furthermore, comprehensive baselines are established under the FRUITS-100/500/1000 milliseconds protocols. The proposed benchmark shows enormous potential on standard, masked and unbiased face recognition scenarios. Our WebFace260M website is https://www.face-benchmark.org.
Face-NMS: A Core-set Selection Approach for Efficient Face Recognition
Sep 10, 2021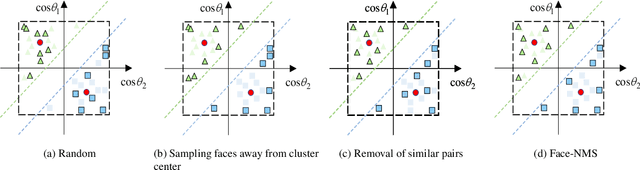
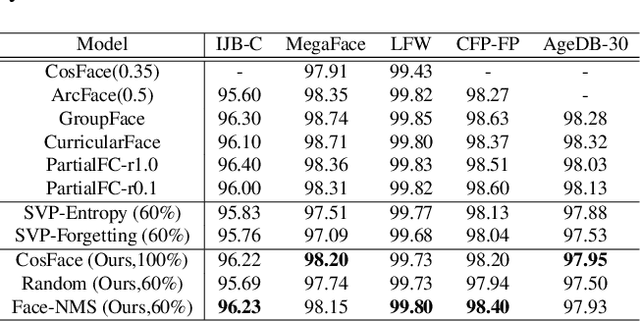
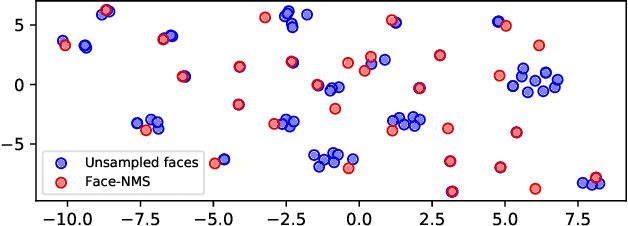
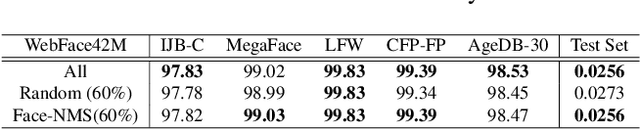
Recently, face recognition in the wild has achieved remarkable success and one key engine is the increasing size of training data. For example, the largest face dataset, WebFace42M contains about 2 million identities and 42 million faces. However, a massive number of faces raise the constraints in training time, computing resources, and memory cost. The current research on this problem mainly focuses on designing an efficient Fully-connected layer (FC) to reduce GPU memory consumption caused by a large number of identities. In this work, we relax these constraints by resolving the redundancy problem of the up-to-date face datasets caused by the greedily collecting operation (i.e. the core-set selection perspective). As the first attempt in this perspective on the face recognition problem, we find that existing methods are limited in both performance and efficiency. For superior cost-efficiency, we contribute a novel filtering strategy dubbed Face-NMS. Face-NMS works on feature space and simultaneously considers the local and global sparsity in generating core sets. In practice, Face-NMS is analogous to Non-Maximum Suppression (NMS) in the object detection community. It ranks the faces by their potential contribution to the overall sparsity and filters out the superfluous face in the pairs with high similarity for local sparsity. With respect to the efficiency aspect, Face-NMS accelerates the whole pipeline by applying a smaller but sufficient proxy dataset in training the proxy model. As a result, with Face-NMS, we successfully scale down the WebFace42M dataset to 60% while retaining its performance on the main benchmarks, offering a 40% resource-saving and 1.64 times acceleration. The code is publicly available for reference at https://github.com/HuangJunJie2017/Face-NMS.
Masked Face Recognition Challenge: The WebFace260M Track Report
Aug 16, 2021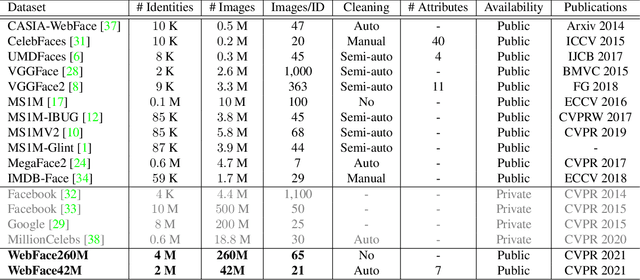
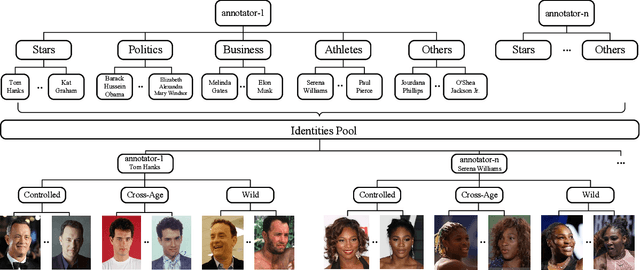
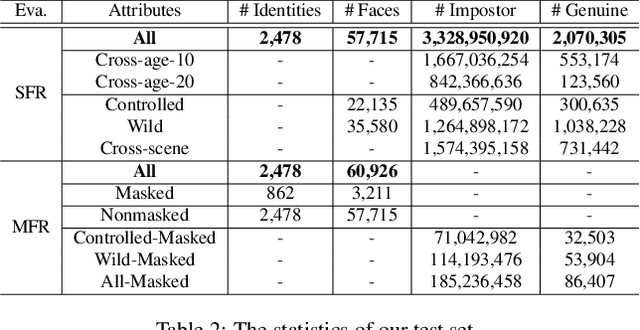
According to WHO statistics, there are more than 204,617,027 confirmed COVID-19 cases including 4,323,247 deaths worldwide till August 12, 2021. During the coronavirus epidemic, almost everyone wears a facial mask. Traditionally, face recognition approaches process mostly non-occluded faces, which include primary facial features such as the eyes, nose, and mouth. Removing the mask for authentication in airports or laboratories will increase the risk of virus infection, posing a huge challenge to current face recognition systems. Due to the sudden outbreak of the epidemic, there are yet no publicly available real-world masked face recognition (MFR) benchmark. To cope with the above-mentioned issue, we organize the Face Bio-metrics under COVID Workshop and Masked Face Recognition Challenge in ICCV 2021. Enabled by the ultra-large-scale WebFace260M benchmark and the Face Recognition Under Inference Time conStraint (FRUITS) protocol, this challenge (WebFace260M Track) aims to push the frontiers of practical MFR. Since public evaluation sets are mostly saturated or contain noise, a new test set is gathered consisting of elaborated 2,478 celebrities and 60,926 faces. Meanwhile, we collect the world-largest real-world masked test set. In the first phase of WebFace260M Track, 69 teams (total 833 solutions) participate in the challenge and 49 teams exceed the performance of our baseline. There are second phase of the challenge till October 1, 2021 and on-going leaderboard. We will actively update this report in the future.
WebFace260M: A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition
Mar 06, 2021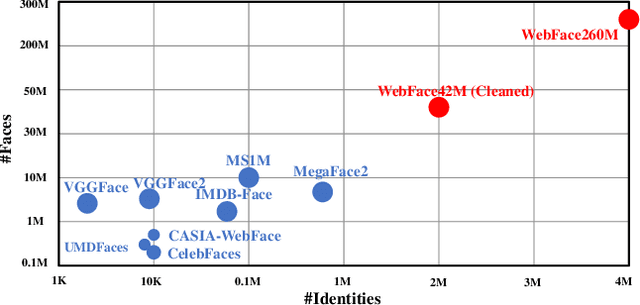
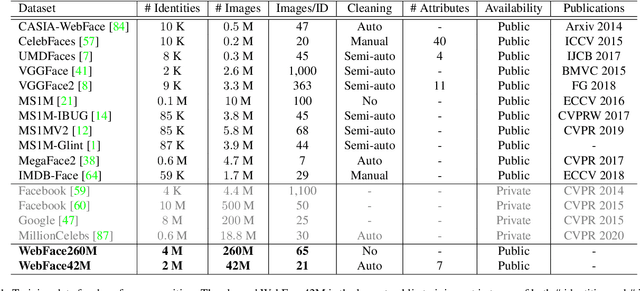
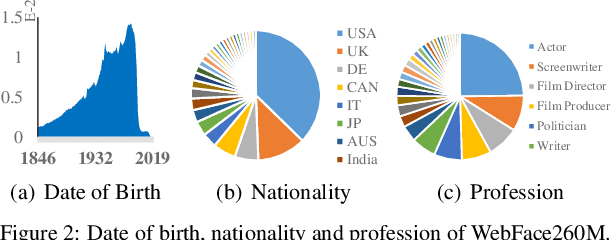
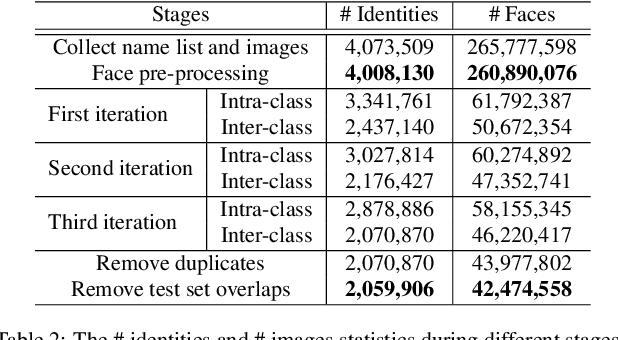
In this paper, we contribute a new million-scale face benchmark containing noisy 4M identities/260M faces (WebFace260M) and cleaned 2M identities/42M faces (WebFace42M) training data, as well as an elaborately designed time-constrained evaluation protocol. Firstly, we collect 4M name list and download 260M faces from the Internet. Then, a Cleaning Automatically utilizing Self-Training (CAST) pipeline is devised to purify the tremendous WebFace260M, which is efficient and scalable. To the best of our knowledge, the cleaned WebFace42M is the largest public face recognition training set and we expect to close the data gap between academia and industry. Referring to practical scenarios, Face Recognition Under Inference Time conStraint (FRUITS) protocol and a test set are constructed to comprehensively evaluate face matchers. Equipped with this benchmark, we delve into million-scale face recognition problems. A distributed framework is developed to train face recognition models efficiently without tampering with the performance. Empowered by WebFace42M, we reduce relative 40% failure rate on the challenging IJB-C set, and ranks the 3rd among 430 entries on NIST-FRVT. Even 10% data (WebFace4M) shows superior performance compared with public training set. Furthermore, comprehensive baselines are established on our rich-attribute test set under FRUITS-100ms/500ms/1000ms protocol, including MobileNet, EfficientNet, AttentionNet, ResNet, SENet, ResNeXt and RegNet families. Benchmark website is https://www.face-benchmark.org.