 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSS-CRS: Liberating AIxCC Cyber Reasoning Systems for Real-World Open-Source Security
Mar 09, 2026DARPA's AI Cyber Challenge (AIxCC) showed that cyber reasoning systems (CRSs) can go beyond vulnerability discovery to autonomously confirm and patch bugs: seven teams built such systems and open-sourced them after the competition. Yet all seven open-sourced CRSs remain largely unusable outside their original teams, each bound to the competition cloud infrastructure that no longer exists. We present OSS-CRS, an open, locally deployable framework for running and combining CRS techniques against real-world open-source projects, with budget-aware resource management. We ported the first-place system (Atlantis) and discovered 10 previously unknown bugs (three of high severity) across 8 OSS-Fuzz projects. OSS-CRS is publicly available.
SoK: DARPA's AI Cyber Challenge (AIxCC): Competition Design, Architectures, and Lessons Learned
Feb 07, 2026DARPA's AI Cyber Challenge (AIxCC, 2023--2025) is the largest competition to date for building fully autonomous cyber reasoning systems (CRSs) that leverage recent advances in AI -- particularly large language models (LLMs) -- to discover and remediate vulnerabilities in real-world open-source software. This paper presents the first systematic analysis of AIxCC. Drawing on design documents, source code, execution traces, and discussions with organizers and competing teams, we examine the competition's structure and key design decisions, characterize the architectural approaches of finalist CRSs, and analyze competition results beyond the final scoreboard. Our analysis reveals the factors that truly drove CRS performance, identifies genuine technical advances achieved by teams, and exposes limitations that remain open for future research. We conclude with lessons for organizing future competitions and broader insights toward deploying autonomous CRSs in practice.
ATLANTIS: AI-driven Threat Localization, Analysis, and Triage Intelligence System
Sep 18, 2025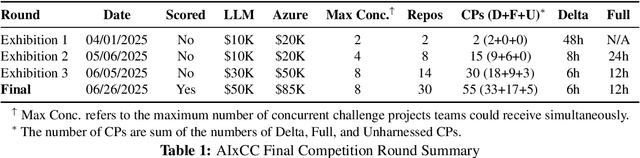
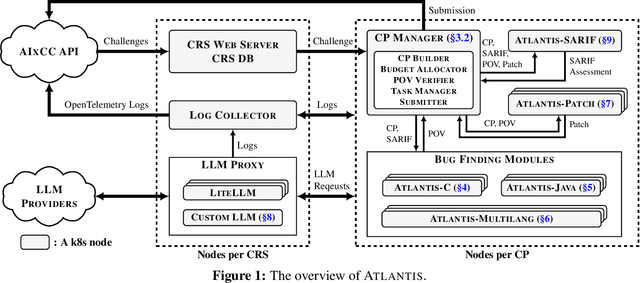
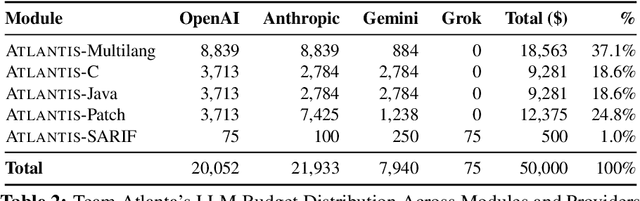
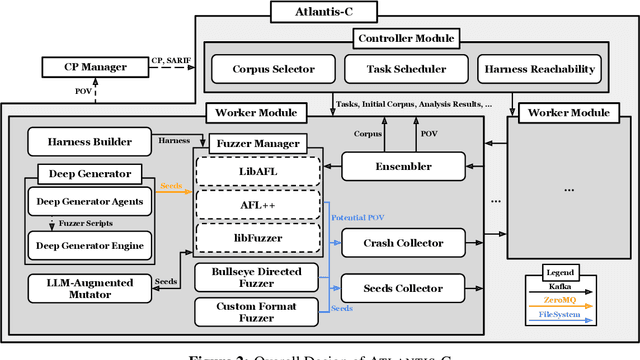
We present ATLANTIS, the cyber reasoning system developed by Team Atlanta that won 1st place in the Final Competition of DARPA's AI Cyber Challenge (AIxCC) at DEF CON 33 (August 2025). AIxCC (2023-2025) challenged teams to build autonomous cyber reasoning systems capable of discovering and patching vulnerabilities at the speed and scale of modern software. ATLANTIS integrates large language models (LLMs) with program analysis -- combining symbolic execution, directed fuzzing, and static analysis -- to address limitations in automated vulnerability discovery and program repair. Developed by researchers at Georgia Institute of Technology, Samsung Research, KAIST, and POSTECH, the system addresses core challenges: scaling across diverse codebases from C to Java, achieving high precision while maintaining broad coverage, and producing semantically correct patches that preserve intended behavior. We detail the design philosophy, architectural decisions, and implementation strategies behind ATLANTIS, share lessons learned from pushing the boundaries of automated security when program analysis meets modern AI, and release artifacts to support reproducibility and future research.
GUNet: A Graph Convolutional Network United Diffusion Model for Stable and Diversity Pose Generation
Sep 18, 2024



Pose skeleton images are an important reference in pose-controllable image generation. In order to enrich the source of skeleton images, recent works have investigated the generation of pose skeletons based on natural language. These methods are based on GANs. However, it remains challenging to perform diverse, structurally correct and aesthetically pleasing human pose skeleton generation with various textual inputs. To address this problem, we propose a framework with GUNet as the main model, PoseDiffusion. It is the first generative framework based on a diffusion model and also contains a series of variants fine-tuned based on a stable diffusion model. PoseDiffusion demonstrates several desired properties that outperform existing methods. 1) Correct Skeletons. GUNet, a denoising model of PoseDiffusion, is designed to incorporate graphical convolutional neural networks. It is able to learn the spatial relationships of the human skeleton by introducing skeletal information during the training process. 2) Diversity. We decouple the key points of the skeleton and characterise them separately, and use cross-attention to introduce textual conditions. Experimental results show that PoseDiffusion outperforms existing SoTA algorithms in terms of stability and diversity of text-driven pose skeleton generation. Qualitative analyses further demonstrate its superiority for controllable generation in Stable Diffusion.
ASTER: Automatic Speech Recognition System Accessibility Testing for Stutterers
Aug 30, 2023



The popularity of automatic speech recognition (ASR) systems nowadays leads to an increasing need for improving their accessibility. Handling stuttering speech is an important feature for accessible ASR systems. To improve the accessibility of ASR systems for stutterers, we need to expose and analyze the failures of ASR systems on stuttering speech. The speech datasets recorded from stutterers are not diverse enough to expose most of the failures. Furthermore, these datasets lack ground truth information about the non-stuttered text, rendering them unsuitable as comprehensive test suites. Therefore, a methodology for generating stuttering speech as test inputs to test and analyze the performance of ASR systems is needed. However, generating valid test inputs in this scenario is challenging. The reason is that although the generated test inputs should mimic how stutterers speak, they should also be diverse enough to trigger more failures. To address the challenge, we propose ASTER, a technique for automatically testing the accessibility of ASR systems. ASTER can generate valid test cases by injecting five different types of stuttering. The generated test cases can both simulate realistic stuttering speech and expose failures in ASR systems. Moreover, ASTER can further enhance the quality of the test cases with a multi-objective optimization-based seed updating algorithm. We implemented ASTER as a framework and evaluated it on four open-source ASR models and three commercial ASR systems. We conduct a comprehensive evaluation of ASTER and find that it significantly increases the word error rate, match error rate, and word information loss in the evaluated ASR systems. Additionally, our user study demonstrates that the generated stuttering audio is indistinguishable from real-world stuttering audio clips.
The Scope of ChatGPT in Software Engineering: A Thorough Investigation
May 20, 2023ChatGPT demonstrates immense potential to transform software engineering (SE) by exhibiting outstanding performance in tasks such as code and document generation. However, the high reliability and risk control requirements of SE make the lack of interpretability for ChatGPT a concern. To address this issue, we carried out a study evaluating ChatGPT's capabilities and limitations in SE. We broke down the abilities needed for AI models to tackle SE tasks into three categories: 1) syntax understanding, 2) static behavior understanding, and 3) dynamic behavior understanding. Our investigation focused on ChatGPT's ability to comprehend code syntax and semantic structures, including abstract syntax trees (AST), control flow graphs (CFG), and call graphs (CG). We assessed ChatGPT's performance on cross-language tasks involving C, Java, Python, and Solidity. Our findings revealed that while ChatGPT excels at understanding code syntax (AST), it struggles with comprehending code semantics, particularly dynamic semantics. We conclude that ChatGPT possesses capabilities akin to an Abstract Syntax Tree (AST) parser, demonstrating initial competencies in static code analysis. Additionally, our study highlights that ChatGPT is susceptible to hallucination when interpreting code semantic structures and fabricating non-existent facts. These results underscore the need to explore methods for verifying the correctness of ChatGPT's outputs to ensure its dependability in SE. More importantly, our study provide an iniital answer why the generated codes from LLMs are usually synatx correct but vulnerabale.