 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTER: Automatic Speech Recognition System Accessibility Testing for Stutterers
Aug 30, 2023



The popularity of automatic speech recognition (ASR) systems nowadays leads to an increasing need for improving their accessibility. Handling stuttering speech is an important feature for accessible ASR systems. To improve the accessibility of ASR systems for stutterers, we need to expose and analyze the failures of ASR systems on stuttering speech. The speech datasets recorded from stutterers are not diverse enough to expose most of the failures. Furthermore, these datasets lack ground truth information about the non-stuttered text, rendering them unsuitable as comprehensive test suites. Therefore, a methodology for generating stuttering speech as test inputs to test and analyze the performance of ASR systems is needed. However, generating valid test inputs in this scenario is challenging. The reason is that although the generated test inputs should mimic how stutterers speak, they should also be diverse enough to trigger more failures. To address the challenge, we propose ASTER, a technique for automatically testing the accessibility of ASR systems. ASTER can generate valid test cases by injecting five different types of stuttering. The generated test cases can both simulate realistic stuttering speech and expose failures in ASR systems. Moreover, ASTER can further enhance the quality of the test cases with a multi-objective optimization-based seed updating algorithm. We implemented ASTER as a framework and evaluated it on four open-source ASR models and three commercial ASR systems. We conduct a comprehensive evaluation of ASTER and find that it significantly increases the word error rate, match error rate, and word information loss in the evaluated ASR systems. Additionally, our user study demonstrates that the generated stuttering audio is indistinguishable from real-world stuttering audio clips.
SemMT: A Semantic-based Testing Approach for Machine Translation Systems
Dec 03, 2020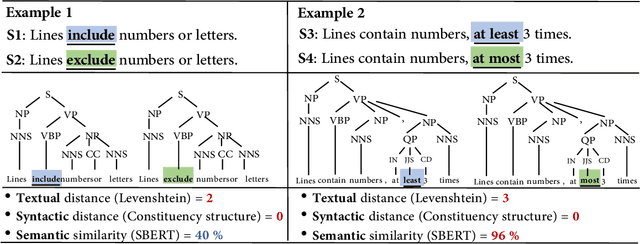
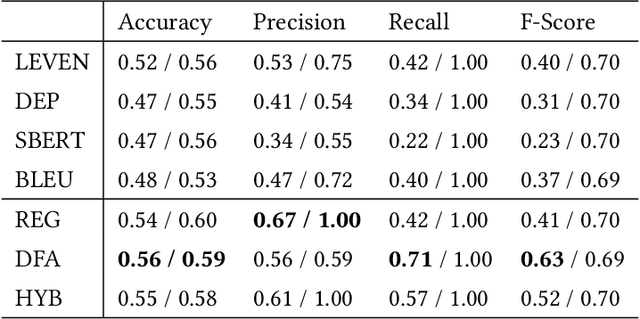

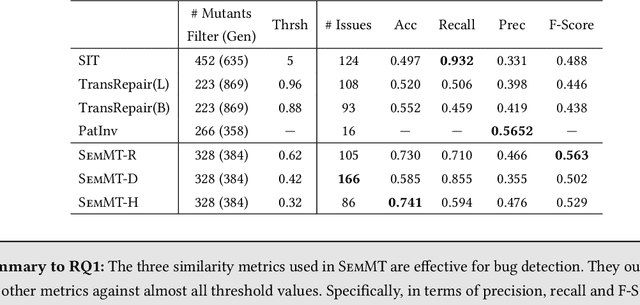
Machine translation has wide applications in daily life. In mission-critical applications such as translating official documents, incorrect translation can have unpleasant or sometimes catastrophic consequences. This motivates recent research on testing methodologies for machine translation systems. Existing methodologies mostly rely on metamorphic relations designed at the textual level (e.g., Levenshtein distance) or syntactic level (e.g., the distance between grammar structures) to determine the correctness of translation results. However, these metamorphic relations do not consider whether the original and translated sentences have the same meaning (i.e., Semantic similarity). Therefore, in this paper, we propose SemMT, an automatic testing approach for machine translation systems based on semantic similarity checking. SemMT applies round-trip translation and measures the semantic similarity between the original and translated sentences. Our insight is that the semantics expressed by the logic and numeric constraint in sentences can be captured using regular expressions (or deterministic finite automata) where efficient equivalence/similarity checking algorithms are available. Leveraging the insight, we propose three semantic similarity metrics and implement them in SemMT. The experiment result reveals SemMT can achieve higher effectiveness compared with state-of-the-art works, achieving an increase of 21% and 23% on accuracy and F-Score, respectively. We also explore potential improvements that can be achieved when proper combinations of metrics are adopted. Finally, we discuss a solution to locate the suspicious trip in round-trip translation, which may shed lights on further exploration.
An Effective Algorithm for Learning Single Occurrence Regular Expressions with Interleaving
Jun 05, 2019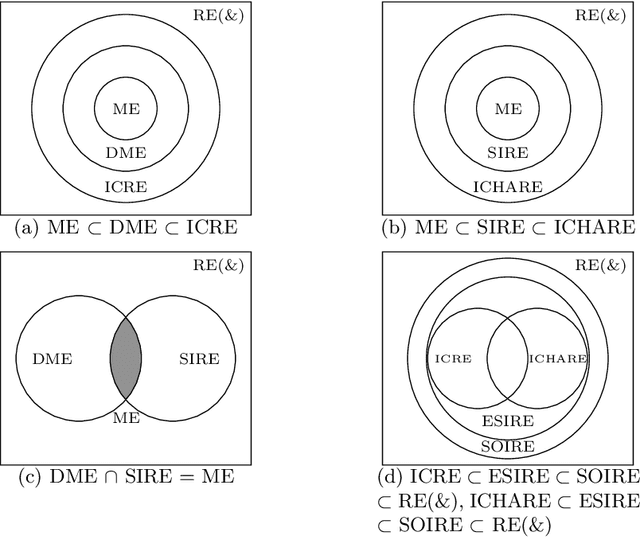
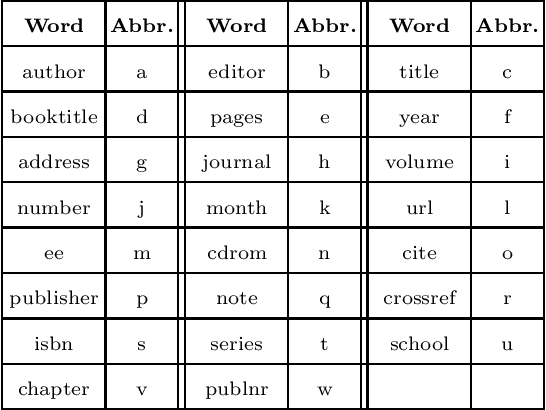
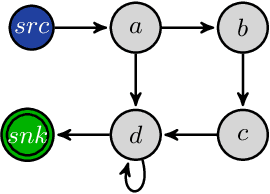
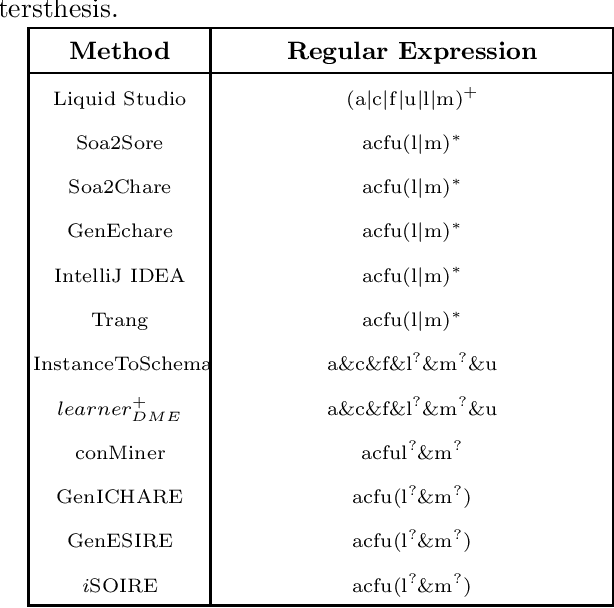
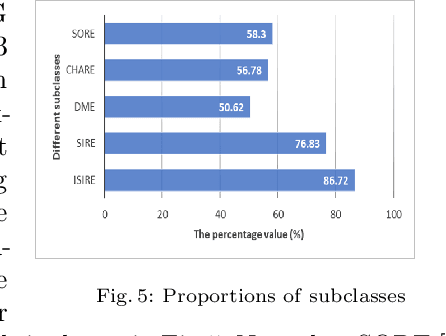
The advantages offered by the presence of a schema are numerous. However, many XML documents in practice are not accompanied by a (valid) schema, making schema inference an attractive research problem. The fundamental task in XML schema learning is inferring restricted subclasses of regular expressions. Most previous work either lacks support for interleaving or only has limited support for interleaving. In this paper, we first propose a new subclass Single Occurrence Regular Expressions with Interleaving (SOIRE), which has unrestricted support for interleaving. Then, based on single occurrence automaton and maximum independent set, we propose an algorithm iSOIRE to infer SOIREs. Finally, we further conduct a series of experiments on real datasets to evaluate the effectiveness of our work, comparing with both ongoing learning algorithms in academia and industrial tools in real-world. The results reveal the practicability of SOIRE and the effectiveness of iSOIRE, showing the high preciseness and conciseness of our work.
Learning Restricted Regular Expressions with Interleaving
Apr 30, 2019
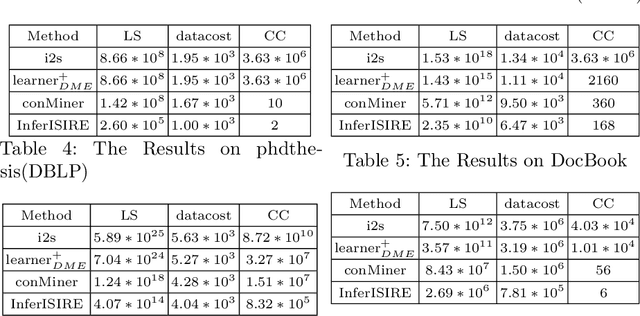

The advantages for the presence of an XML schema for XML documents are numerous. However, many XML documents in practice are not accompanied by a schema or by a valid schema. Relax NG is a popular and powerful schema language, which supports the unconstrained interleaving operator. Focusing on the inference of Relax NG, we propose a new subclass of regular expressions with interleaving and design a polynomial inference algorithm. Then we conducted a series of experiments based on large-scale real data and on three XML data corpora, and experimental results show that our subclass has a better practicality than previous ones, and the regular expressions inferred by our algorithm are more precise.