 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom What to How: Bridging User Requirements with Software Development Using Large Language Models
Feb 14, 2026Recently, large language models (LLMs) are extensively utilized to enhance development efficiency, leading to numerous benchmarks for evaluating their performance. However, these benchmarks predominantly focus on implementation, overlooking the equally critical aspect of software design. This gap raises two pivotal questions: (1) Can LLMs handle software design? (2) Can LLMs write code following the specific designs? To investigate these questions, this paper proposes DesBench, a design-aware benchmark for evaluating LLMs on three software design-related tasks: design-aware code generation, object-oriented modeling, and the design of acceptance test cases. DesBench comprises 30 manually crafted Java projects that include requirement documents, design models, implementations, and acceptance tests, amounting to a total of 30 design models, 194 Java classes, and 737 test cases. We evaluated seven state-of-the-art LLMs, including three DeepSeek R1, two Qwen2.5, and two GPT models, using DesBench. The results reveal that LLMs remain significantly challenged by the intricacies of software design: (1) For code generation, LLMs struggle to produce correct implementations when provided with only high-level or no designs. (2) In object-oriented modeling, while LLMs can accurately identify objects and classes, they face challenges in defining operations and inter-class relationships. (3) Acceptance test cases generated by LLMs from functional requirements achieve code coverage quality comparable to those written by humans. Our research highlights the current limitations of LLMs in managing software design and calls for further investigation into new design methodologies and languages suitable for LLM-based development.
ModelWisdom: An Integrated Toolkit for TLA+ Model Visualization, Digest and Repair
Feb 12, 2026Model checking in TLA+ provides strong correctness guarantees, yet practitioners continue to face significant challenges in interpreting counterexamples, understanding large state-transition graphs, and repairing faulty models. These difficulties stem from the limited explainability of raw model-checker output and the substantial manual effort required to trace violations back to source specifications. Although the TLA+ Toolbox includes a state diagram viewer, it offers only a static, fully expanded graph without folding, color highlighting, or semantic explanations, which limits its scalability and interpretability. We present ModelWisdom, an interactive environment that uses visualization and large language models to make TLA+ model checking more interpretable and actionable. ModelWisdom offers: (i) Model Visualization, with colorized violation highlighting, click-through links from transitions to TLA+ code, and mapping between violating states and broken properties; (ii) Graph Optimization, including tree-based structuring and node/edge folding to manage large models; (iii) Model Digest, which summarizes and explains subgraphs via large language models (LLMs) and performs preprocessing and partial explanations; and (iv) Model Repair, which extracts error information and supports iterative debugging. Together, these capabilities turn raw model-checker output into an interactive, explainable workflow, improving understanding and reducing debugging effort for nontrivial TLA+ specifications. The website to ModelWisdom is available: https://model-wisdom.pages.dev. A demonstrative video can be found at https://www.youtube.com/watch?v=plyZo30VShA.
Isolating Language-Coding from Problem-Solving: Benchmarking LLMs with PseudoEval
Feb 26, 2025Existing code generation benchmarks for Large Language Models (LLMs) such as HumanEval and MBPP are designed to study LLMs' end-to-end performance, where the benchmarks feed a problem description in natural language as input and examine the generated code in specific programming languages. However, the evaluation scores revealed in this way provide a little hint as to the bottleneck of the code generation -- whether LLMs are struggling with their problem-solving capability or language-coding capability. To answer this question, we construct PseudoEval, a multilingual code generation benchmark that provides a solution written in pseudocode as input. By doing so, the bottleneck of code generation in various programming languages could be isolated and identified. Our study yields several interesting findings. For example, we identify that the bottleneck of LLMs in Python programming is problem-solving, while Rust is struggling relatively more in language-coding. Also, our study indicates that problem-solving capability may transfer across programming languages, while language-coding needs more language-specific effort, especially for undertrained programming languages. Finally, we release the pipeline of constructing PseudoEval to facilitate the extension to existing benchmarks. PseudoEval is available at: https://anonymous.4open.science/r/PseudocodeACL25-7B74.
From Informal to Formal -- Incorporating and Evaluating LLMs on Natural Language Requirements to Verifiable Formal Proofs
Jan 27, 2025The research in AI-based formal mathematical reasoning has shown an unstoppable growth trend. These studies have excelled in mathematical competitions like IMO, showing significant progress. However, these studies intertwined multiple skills simultaneously, i.e., problem-solving, reasoning, and writing formal specifications, making it hard to precisely identify the LLMs' strengths and weaknesses in each task. This paper focuses on formal verification, an immediate application scenario of formal reasoning, and decomposes it into six sub-tasks. We constructed 18k high-quality instruction-response pairs across five mainstream formal specification languages (Coq, Lean4, Dafny, ACSL, and TLA+) in six formal-verification-related tasks by distilling GPT-4o. They are split into a 14k+ fine-tuning dataset FM-alpaca and a 4k benchmark FM-Bench. We found that LLMs are good at writing proof segments when given either the code, or the detailed description of proof steps. Also, the fine-tuning brought about a nearly threefold improvement at most. Interestingly, we observed that fine-tuning with formal data also enhances mathematics, reasoning, and coding abilities. We hope our findings inspire further research. Fine-tuned models are released to facilitate subsequent studies
How Should I Build A Benchmark?
Jan 18, 2025Various benchmarks have been proposed to assess the performance of large language models (LLMs) in different coding scenarios. We refer to them as code-related benchmarks. However, there are no systematic guidelines by which such a benchmark should be developed to ensure its quality, reliability, and reproducibility. We propose How2Bench, which is comprised of a 55- 55-criteria checklist as a set of guidelines to govern the development of code-related benchmarks comprehensively. Using HOW2BENCH, we profiled 274 benchmarks released within the past decade and found concerning issues. Nearly 70% of the benchmarks did not take measures for data quality assurance; over 10% did not even open source or only partially open source. Many highly cited benchmarks have loopholes, including duplicated samples, incorrect reference codes/tests/prompts, and unremoved sensitive/confidential information. Finally, we conducted a human study involving 49 participants, which revealed significant gaps in awareness of the importance of data quality, reproducibility, and transparency.
ICM-Assistant: Instruction-tuning Multimodal Large Language Models for Rule-based Explainable Image Content Moderation
Dec 24, 2024



Controversial contents largely inundate the Internet, infringing various cultural norms and child protection standards. Traditional Image Content Moderation (ICM) models fall short in producing precise moderation decisions for diverse standards, while recent multimodal large language models (MLLMs), when adopted to general rule-based ICM, often produce classification and explanation results that are inconsistent with human moderators. Aiming at flexible, explainable, and accurate ICM, we design a novel rule-based dataset generation pipeline, decomposing concise human-defined rules and leveraging well-designed multi-stage prompts to enrich short explicit image annotations. Our ICM-Instruct dataset includes detailed moderation explanation and moderation Q-A pairs. Built upon it, we create our ICM-Assistant model in the framework of rule-based ICM, making it readily applicable in real practice. Our ICM-Assistant model demonstrates exceptional performance and flexibility. Specifically, it significantly outperforms existing approaches on various sources, improving both the moderation classification (36.8\% on average) and moderation explanation quality (26.6\% on average) consistently over existing MLLMs. Code/Data is available at https://github.com/zhaoyuzhi/ICM-Assistant.
CODECLEANER: Elevating Standards with A Robust Data Contamination Mitigation Toolkit
Nov 16, 2024Data contamination presents a critical barrier preventing widespread industrial adoption of advanced software engineering techniques that leverage code language models (CLMs). This phenomenon occurs when evaluation data inadvertently overlaps with the public code repositories used to train CLMs, severely undermining the credibility of performance evaluations. For software companies considering the integration of CLM-based techniques into their development pipeline, this uncertainty about true performance metrics poses an unacceptable business risk. Code refactoring, which comprises code restructuring and variable renaming, has emerged as a promising measure to mitigate data contamination. It provides a practical alternative to the resource-intensive process of building contamination-free evaluation datasets, which would require companies to collect, clean, and label code created after the CLMs' training cutoff dates. However, the lack of automated code refactoring tools and scientifically validated refactoring techniques has hampered widespread industrial implementation. To bridge the gap, this paper presents the first systematic study to examine the efficacy of code refactoring operators at multiple scales (method-level, class-level, and cross-class level) and in different programming languages. In particular, we develop an open-sourced toolkit, CODECLEANER, which includes 11 operators for Python, with nine method-level, one class-level, and one cross-class-level operator. A drop of 65% overlap ratio is found when applying all operators in CODECLEANER, demonstrating their effectiveness in addressing data contamination. Additionally, we migrate four operators to Java, showing their generalizability to another language. We make CODECLEANER online available to facilitate further studies on mitigating CLM data contamination.
DOMAINEVAL: An Auto-Constructed Benchmark for Multi-Domain Code Generation
Aug 23, 2024



Code benchmarks such as HumanEval are widely adopted to evaluate the capabilities of Large Language Models (LLMs), providing insights into their strengths and weaknesses. However, current benchmarks primarily exercise LLMs' capability on common coding tasks (e.g., bubble sort, greatest common divisor), leaving domain-specific coding tasks (e.g., computation, system, cryptography) unexplored. To fill this gap, we propose a multi-domain code benchmark, DOMAINEVAL, designed to evaluate LLMs' coding capabilities thoroughly. Our pipeline works in a fully automated manner, enabling a push-bottom construction from code repositories into formatted subjects under study. Interesting findings are observed by evaluating 12 representative LLMs against DOMAINEVAL. We notice that LLMs are generally good at computation tasks while falling short on cryptography and system coding tasks. The performance gap can be as much as 68.94% (80.94% - 12.0%) in some LLMs. We also observe that generating more samples can increase the overall performance of LLMs, while the domain bias may even increase. The contributions of this study include a code generation benchmark dataset DOMAINEVAL, encompassing six popular domains, a fully automated pipeline for constructing code benchmarks, and an identification of the limitations of LLMs in code generation tasks based on their performance on DOMAINEVAL, providing directions for future research improvements. The leaderboard is available at https://domaineval.github.io/.
CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding and Execution
Aug 23, 2024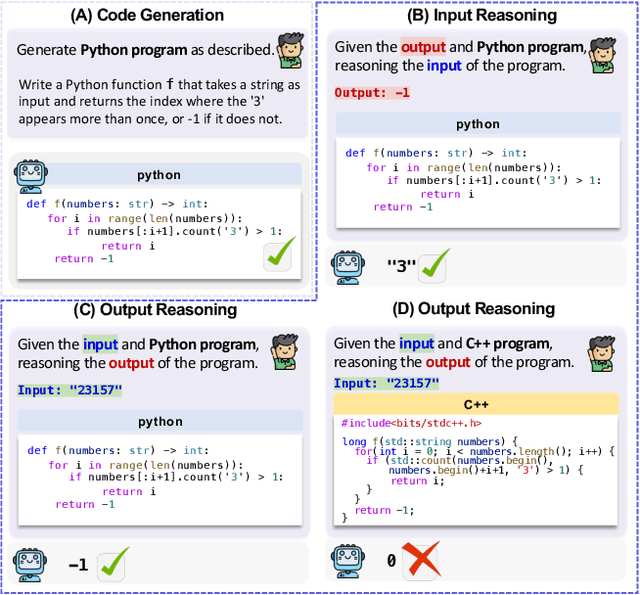
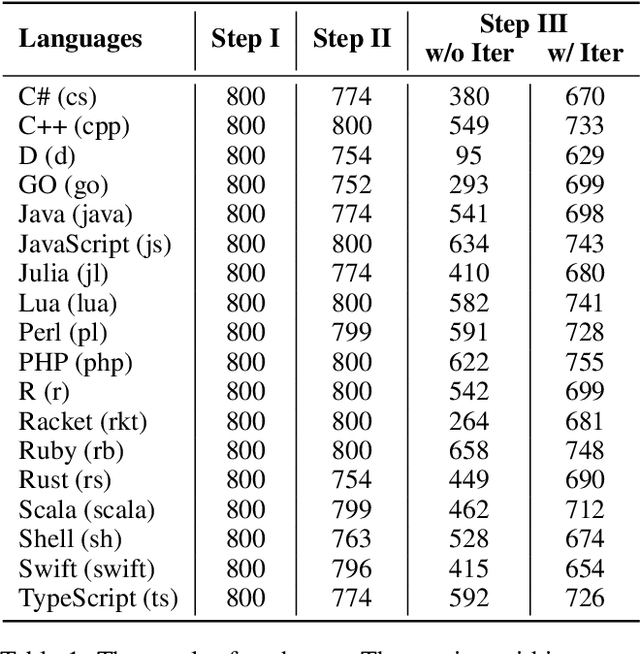
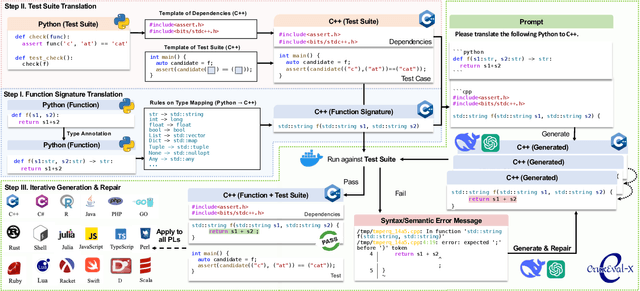

Code benchmarks such as HumanEval are widely adopted to evaluate Large Language Models' (LLMs) coding capabilities. However, there is an unignorable programming language bias in existing code benchmarks -- over 95% code generation benchmarks are dominated by Python, leaving the LLMs' capabilities in other programming languages such as Java and C/C++ unknown. Moreover, coding task bias is also crucial. Most benchmarks focus on code generation capability, while benchmarks for code reasoning (given input, reasoning output; and given output, reasoning input), an essential coding capability, are insufficient. Yet, constructing multi-lingual benchmarks can be expensive and labor-intensive, and codes in contest websites such as Leetcode suffer from data contamination during training. To fill this gap, we propose CRUXEVAL-X, a multi-lingual code reasoning benchmark that contains 19 programming languages. It comprises at least 600 subjects for each language, along with 19K content-consistent tests in total. In particular, the construction pipeline of CRUXEVAL-X works in a fully automated and test-guided manner, which iteratively generates and repairs based on execution feedback. Also, to cross language barriers (e.g., dynamic/static type systems in Python/C++), we formulated various transition rules between language pairs to facilitate translation. Our intensive evaluation of 24 representative LLMs reveals the correlation between language pairs. For example, TypeScript and JavaScript show a significant positive correlation, while Racket has less correlation with other languages. More interestingly, even a model trained solely on Python can achieve at most 34.4% Pass@1 in other languages, revealing the cross-language generalization of LLMs.
DLLens: Testing Deep Learning Libraries via LLM-aided Synthesis
Jun 12, 2024



Testing is a major approach to ensuring the quality of deep learning (DL) libraries. Existing testing techniques commonly adopt differential testing to relieve the need for test oracle construction. However, these techniques are limited in finding implementations that offer the same functionality and generating diverse test inputs for differential testing. This paper introduces DLLens, a novel differential testing technique for DL library testing. Our insight is that APIs in different DL libraries are commonly designed to accomplish various computations for the same set of published DL algorithms. Although the mapping of these APIs is not often one-to-one, we observe that their computations can be mutually simulated after proper composition and adaptation. The use of these simulation counterparts facilitates differential testing for the detection of functional DL library bugs. Leveraging the insight, we propose DLLens as a novel mechanism that utilizes a large language model (LLM) to synthesize valid counterparts of DL library APIs. To generate diverse test inputs, DLLens incorporates a static analysis method aided by LLM to extract path constraints from all execution paths in each API and its counterpart's implementations. These path constraints are then used to guide the generation of diverse test inputs. We evaluate DLLens on two popular DL libraries, TensorFlow and PyTorch. Our evaluation shows that DLLens can synthesize counterparts for more than twice as many APIs found by state-of-the-art techniques on these libraries. Moreover, DLLens can extract 26.7% more constraints and detect 2.5 times as many bugs as state-of-the-art techniques. DLLens has successfully found 56 bugs in recent TensorFlow and PyTorch libraries. Among them, 41 are previously unknown, 39 of which have been confirmed by developers after reporting, and 19 of those confirmed bugs have been fixed by developers.