 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVP-Bench: A Comprehensive Benchmark for Visual Prompting in Multimodal Large Language Models
Nov 14, 2025Multimodal large language models (MLLMs) have enabled a wide range of advanced vision-language applications, including fine-grained object recognition and contextual understanding. When querying specific regions or objects in an image, human users naturally use "visual prompts" (VPs), such as bounding boxes, to provide reference. However, no existing benchmark systematically evaluates the ability of MLLMs to interpret such VPs. This gap leaves it unclear whether current MLLMs can effectively recognize VPs, an intuitive prompting method for humans, and use them to solve problems. To address this limitation, we introduce VP-Bench, a benchmark for assessing MLLMs' capability in VP perception and utilization. VP-Bench employs a two-stage evaluation framework: Stage 1 examines models' ability to perceive VPs in natural scenes, using 30k visualized prompts spanning eight shapes and 355 attribute combinations. Stage 2 investigates the impact of VPs on downstream tasks, measuring their effectiveness in real-world problem-solving scenarios. Using VP-Bench, we evaluate 28 MLLMs, including proprietary systems (e.g., GPT-4o) and open-source models (e.g., InternVL3 and Qwen2.5-VL), and provide a comprehensive analysis of factors that affect VP understanding, such as variations in VP attributes, question arrangement, and model scale. VP-Bench establishes a new reference framework for studying how MLLMs comprehend and resolve grounded referring questions.
From Exploration to Exploitation: A Two-Stage Entropy RLVR Approach for Noise-Tolerant MLLM Training
Nov 11, 2025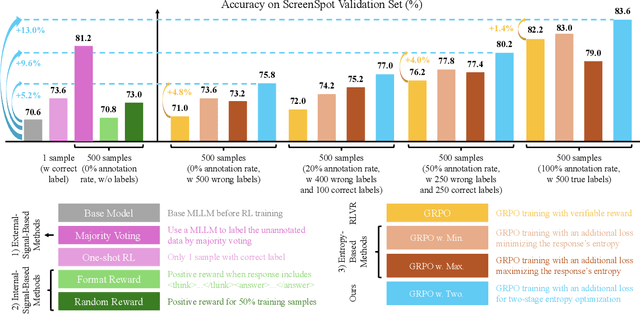



Reinforcement Learning with Verifiable Rewards (RLVR) for Multimodal Large Language Models (MLLMs) is highly dependent on high-quality labeled data, which is often scarce and prone to substantial annotation noise in real-world scenarios. Existing unsupervised RLVR methods, including pure entropy minimization, can overfit to incorrect labels and limit the crucial reward ranking signal for Group-Relative Policy Optimization (GRPO). To address these challenges and enhance noise tolerance, we propose a novel two-stage, token-level entropy optimization method for RLVR. This approach dynamically guides the model from exploration to exploitation during training. In the initial exploration phase, token-level entropy maximization promotes diverse and stochastic output generation, serving as a strong regularizer that prevents premature convergence to noisy labels and ensures sufficient intra-group variation, which enables more reliable reward gradient estimation in GRPO. As training progresses, the method transitions into the exploitation phase, where token-level entropy minimization encourages the model to produce confident and deterministic outputs, thereby consolidating acquired knowledge and refining prediction accuracy. Empirically, across three MLLM backbones - Qwen2-VL-2B, Qwen2-VL-7B, and Qwen2.5-VL-3B - spanning diverse noise settings and multiple tasks, our phased strategy consistently outperforms prior approaches by unifying and enhancing external, internal, and entropy-based methods, delivering robust and superior performance across the board.
ICM-Assistant: Instruction-tuning Multimodal Large Language Models for Rule-based Explainable Image Content Moderation
Dec 24, 2024



Controversial contents largely inundate the Internet, infringing various cultural norms and child protection standards. Traditional Image Content Moderation (ICM) models fall short in producing precise moderation decisions for diverse standards, while recent multimodal large language models (MLLMs), when adopted to general rule-based ICM, often produce classification and explanation results that are inconsistent with human moderators. Aiming at flexible, explainable, and accurate ICM, we design a novel rule-based dataset generation pipeline, decomposing concise human-defined rules and leveraging well-designed multi-stage prompts to enrich short explicit image annotations. Our ICM-Instruct dataset includes detailed moderation explanation and moderation Q-A pairs. Built upon it, we create our ICM-Assistant model in the framework of rule-based ICM, making it readily applicable in real practice. Our ICM-Assistant model demonstrates exceptional performance and flexibility. Specifically, it significantly outperforms existing approaches on various sources, improving both the moderation classification (36.8\% on average) and moderation explanation quality (26.6\% on average) consistently over existing MLLMs. Code/Data is available at https://github.com/zhaoyuzhi/ICM-Assistant.
LLaVA-SpaceSGG: Visual Instruct Tuning for Open-vocabulary Scene Graph Generation with Enhanced Spatial Relations
Dec 09, 2024
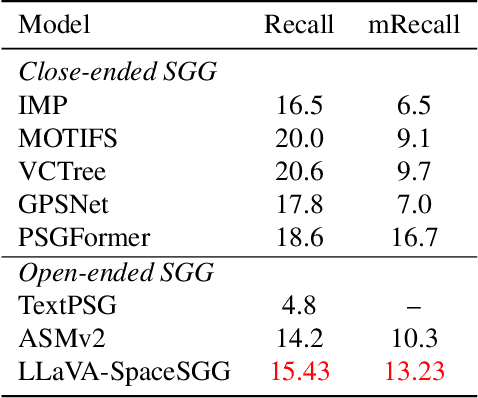

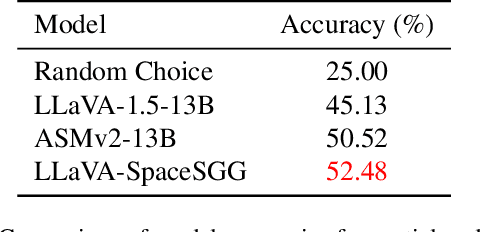
Scene Graph Generation (SGG) converts visual scenes into structured graph representations, providing deeper scene understanding for complex vision tasks. However, existing SGG models often overlook essential spatial relationships and struggle with generalization in open-vocabulary contexts. To address these limitations, we propose LLaVA-SpaceSGG, a multimodal large language model (MLLM) designed for open-vocabulary SGG with enhanced spatial relation modeling. To train it, we collect the SGG instruction-tuning dataset, named SpaceSGG. This dataset is constructed by combining publicly available datasets and synthesizing data using open-source models within our data construction pipeline. It combines object locations, object relations, and depth information, resulting in three data formats: spatial SGG description, question-answering, and conversation. To enhance the transfer of MLLMs' inherent capabilities to the SGG task, we introduce a two-stage training paradigm. Experiments show that LLaVA-SpaceSGG outperforms other open-vocabulary SGG methods, boosting recall by 8.6% and mean recall by 28.4% compared to the baseline. Our codebase, dataset, and trained models are publicly accessible on GitHub at the following URL: https://github.com/Endlinc/LLaVA-SpaceSGG.
Towards Real-World Adverse Weather Image Restoration: Enhancing Clearness and Semantics with Vision-Language Models
Sep 03, 2024



This paper addresses the limitations of adverse weather image restoration approaches trained on synthetic data when applied to real-world scenarios. We formulate a semi-supervised learning framework employing vision-language models to enhance restoration performance across diverse adverse weather conditions in real-world settings. Our approach involves assessing image clearness and providing semantics using vision-language models on real data, serving as supervision signals for training restoration models. For clearness enhancement, we use real-world data, utilizing a dual-step strategy with pseudo-labels assessed by vision-language models and weather prompt learning. For semantic enhancement, we integrate real-world data by adjusting weather conditions in vision-language model descriptions while preserving semantic meaning. Additionally, we introduce an effective training strategy to bootstrap restoration performance. Our approach achieves superior results in real-world adverse weather image restoration, demonstrated through qualitative and quantitative comparisons with state-of-the-art works.
FloorLevel-Net: Recognizing Floor-Level Lines with Height-Attention-Guided Multi-task Learning
Jul 06, 2021
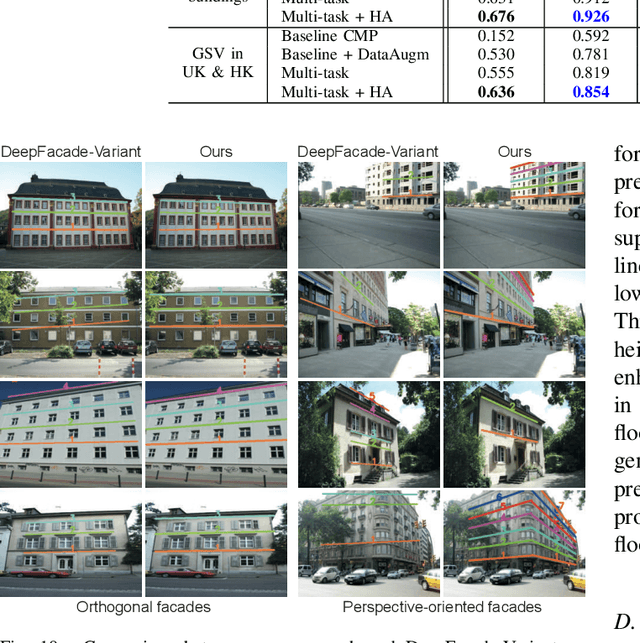


The ability to recognize the position and order of the floor-level lines that divide adjacent building floors can benefit many applications, for example, urban augmented reality (AR). This work tackles the problem of locating floor-level lines in street-view images, using a supervised deep learning approach. Unfortunately, very little data is available for training such a network $-$ current street-view datasets contain either semantic annotations that lack geometric attributes, or rectified facades without perspective priors. To address this issue, we first compile a new dataset and develop a new data augmentation scheme to synthesize training samples by harassing (i) the rich semantics of existing rectified facades and (ii) perspective priors of buildings in diverse street views. Next, we design FloorLevel-Net, a multi-task learning network that associates explicit features of building facades and implicit floor-level lines, along with a height-attention mechanism to help enforce a vertical ordering of floor-level lines. The generated segmentations are then passed to a second-stage geometry post-processing to exploit self-constrained geometric priors for plausible and consistent reconstruction of floor-level lines. Quantitative and qualitative evaluations conducted on assorted facades in existing datasets and street views from Google demonstrate the effectiveness of our approach. Also, we present context-aware image overlay results and show the potentials of our approach in enriching AR-related applications.