 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVP-Bench: A Comprehensive Benchmark for Visual Prompting in Multimodal Large Language Models
Nov 14, 2025Multimodal large language models (MLLMs) have enabled a wide range of advanced vision-language applications, including fine-grained object recognition and contextual understanding. When querying specific regions or objects in an image, human users naturally use "visual prompts" (VPs), such as bounding boxes, to provide reference. However, no existing benchmark systematically evaluates the ability of MLLMs to interpret such VPs. This gap leaves it unclear whether current MLLMs can effectively recognize VPs, an intuitive prompting method for humans, and use them to solve problems. To address this limitation, we introduce VP-Bench, a benchmark for assessing MLLMs' capability in VP perception and utilization. VP-Bench employs a two-stage evaluation framework: Stage 1 examines models' ability to perceive VPs in natural scenes, using 30k visualized prompts spanning eight shapes and 355 attribute combinations. Stage 2 investigates the impact of VPs on downstream tasks, measuring their effectiveness in real-world problem-solving scenarios. Using VP-Bench, we evaluate 28 MLLMs, including proprietary systems (e.g., GPT-4o) and open-source models (e.g., InternVL3 and Qwen2.5-VL), and provide a comprehensive analysis of factors that affect VP understanding, such as variations in VP attributes, question arrangement, and model scale. VP-Bench establishes a new reference framework for studying how MLLMs comprehend and resolve grounded referring questions.
From Exploration to Exploitation: A Two-Stage Entropy RLVR Approach for Noise-Tolerant MLLM Training
Nov 11, 2025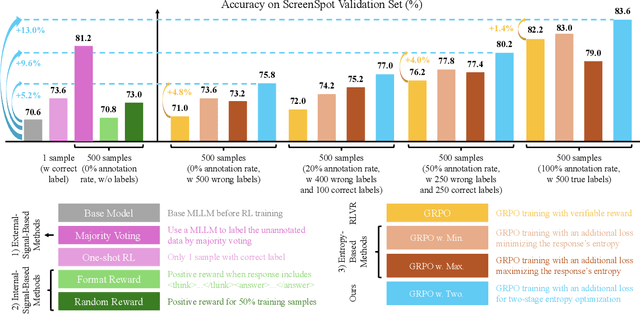



Reinforcement Learning with Verifiable Rewards (RLVR) for Multimodal Large Language Models (MLLMs) is highly dependent on high-quality labeled data, which is often scarce and prone to substantial annotation noise in real-world scenarios. Existing unsupervised RLVR methods, including pure entropy minimization, can overfit to incorrect labels and limit the crucial reward ranking signal for Group-Relative Policy Optimization (GRPO). To address these challenges and enhance noise tolerance, we propose a novel two-stage, token-level entropy optimization method for RLVR. This approach dynamically guides the model from exploration to exploitation during training. In the initial exploration phase, token-level entropy maximization promotes diverse and stochastic output generation, serving as a strong regularizer that prevents premature convergence to noisy labels and ensures sufficient intra-group variation, which enables more reliable reward gradient estimation in GRPO. As training progresses, the method transitions into the exploitation phase, where token-level entropy minimization encourages the model to produce confident and deterministic outputs, thereby consolidating acquired knowledge and refining prediction accuracy. Empirically, across three MLLM backbones - Qwen2-VL-2B, Qwen2-VL-7B, and Qwen2.5-VL-3B - spanning diverse noise settings and multiple tasks, our phased strategy consistently outperforms prior approaches by unifying and enhancing external, internal, and entropy-based methods, delivering robust and superior performance across the board.
LLaVA-SpaceSGG: Visual Instruct Tuning for Open-vocabulary Scene Graph Generation with Enhanced Spatial Relations
Dec 09, 2024
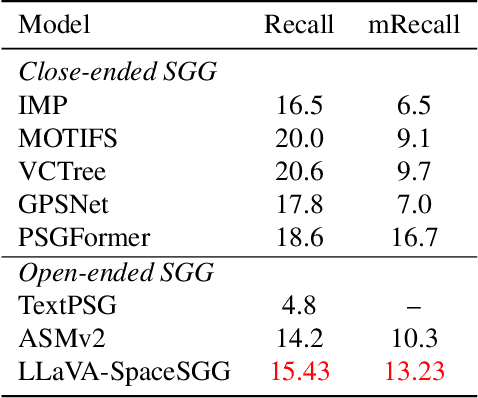

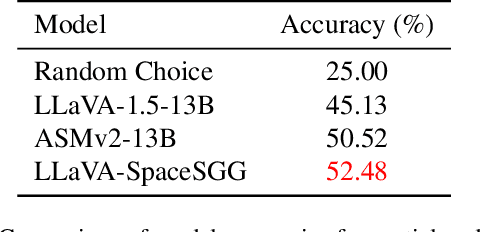
Scene Graph Generation (SGG) converts visual scenes into structured graph representations, providing deeper scene understanding for complex vision tasks. However, existing SGG models often overlook essential spatial relationships and struggle with generalization in open-vocabulary contexts. To address these limitations, we propose LLaVA-SpaceSGG, a multimodal large language model (MLLM) designed for open-vocabulary SGG with enhanced spatial relation modeling. To train it, we collect the SGG instruction-tuning dataset, named SpaceSGG. This dataset is constructed by combining publicly available datasets and synthesizing data using open-source models within our data construction pipeline. It combines object locations, object relations, and depth information, resulting in three data formats: spatial SGG description, question-answering, and conversation. To enhance the transfer of MLLMs' inherent capabilities to the SGG task, we introduce a two-stage training paradigm. Experiments show that LLaVA-SpaceSGG outperforms other open-vocabulary SGG methods, boosting recall by 8.6% and mean recall by 28.4% compared to the baseline. Our codebase, dataset, and trained models are publicly accessible on GitHub at the following URL: https://github.com/Endlinc/LLaVA-SpaceSGG.
ASMR: Activation-sharing Multi-resolution Coordinate Networks For Efficient Inference
May 20, 2024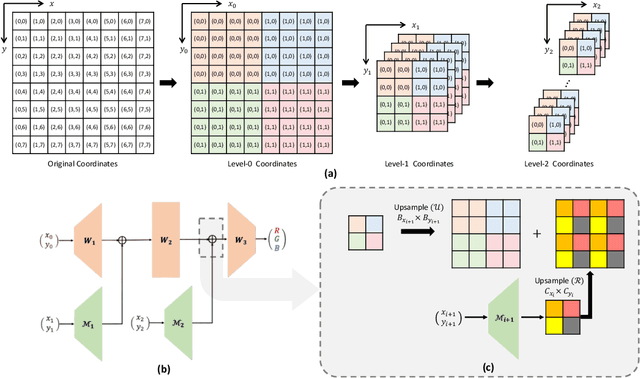
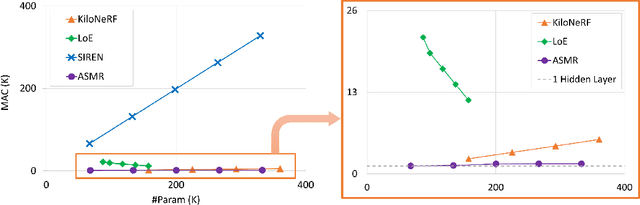
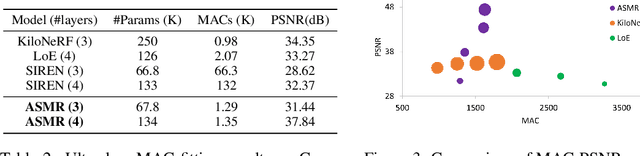
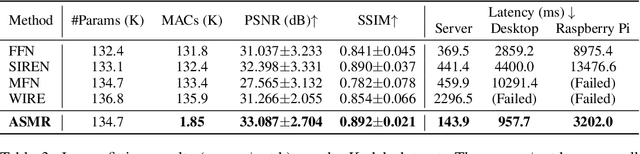
Coordinate network or implicit neural representation (INR) is a fast-emerging method for encoding natural signals (such as images and videos) with the benefits of a compact neural representation. While numerous methods have been proposed to increase the encoding capabilities of an INR, an often overlooked aspect is the inference efficiency, usually measured in multiply-accumulate (MAC) count. This is particularly critical in use cases where inference throughput is greatly limited by hardware constraints. To this end, we propose the Activation-Sharing Multi-Resolution (ASMR) coordinate network that combines multi-resolution coordinate decomposition with hierarchical modulations. Specifically, an ASMR model enables the sharing of activations across grids of the data. This largely decouples its inference cost from its depth which is directly correlated to its reconstruction capability, and renders a near O(1) inference complexity irrespective of the number of layers. Experiments show that ASMR can reduce the MAC of a vanilla SIREN model by up to 500x while achieving an even higher reconstruction quality than its SIREN baseline.
Nonparametric Teaching of Implicit Neural Representations
May 17, 2024We investigate the learning of implicit neural representation (INR) using an overparameterized multilayer perceptron (MLP) via a novel nonparametric teaching perspective. The latter offers an efficient example selection framework for teaching nonparametrically defined (viz. non-closed-form) target functions, such as image functions defined by 2D grids of pixels. To address the costly training of INRs, we propose a paradigm called Implicit Neural Teaching (INT) that treats INR learning as a nonparametric teaching problem, where the given signal being fitted serves as the target function. The teacher then selects signal fragments for iterative training of the MLP to achieve fast convergence. By establishing a connection between MLP evolution through parameter-based gradient descent and that of function evolution through functional gradient descent in nonparametric teaching, we show for the first time that teaching an overparameterized MLP is consistent with teaching a nonparametric learner. This new discovery readily permits a convenient drop-in of nonparametric teaching algorithms to broadly enhance INR training efficiency, demonstrating 30%+ training time savings across various input modalities.
Learning Spatially Collaged Fourier Bases for Implicit Neural Representation
Dec 28, 2023
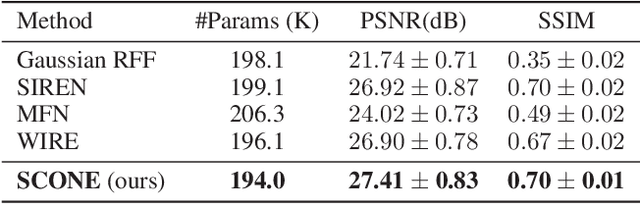
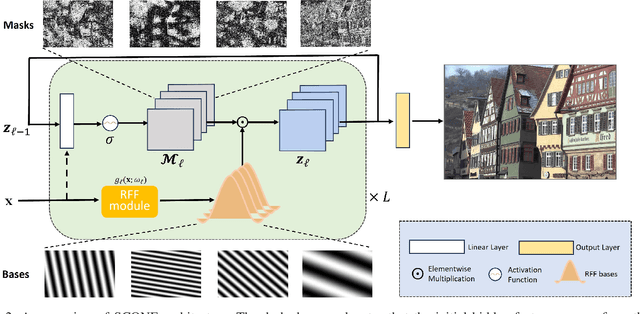
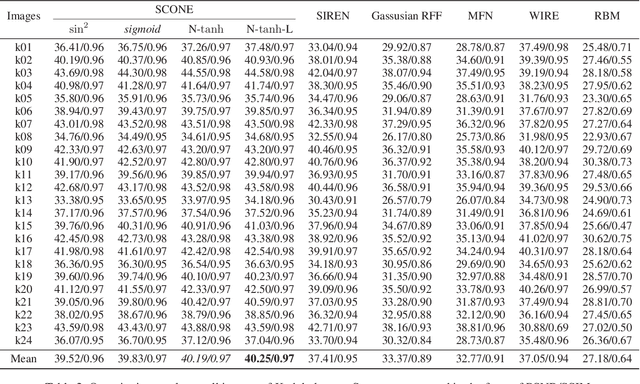
Existing approaches to Implicit Neural Representation (INR) can be interpreted as a global scene representation via a linear combination of Fourier bases of different frequencies. However, such universal basis functions can limit the representation capability in local regions where a specific component is unnecessary, resulting in unpleasant artifacts. To this end, we introduce a learnable spatial mask that effectively dispatches distinct Fourier bases into respective regions. This translates into collaging Fourier patches, thus enabling an accurate representation of complex signals. Comprehensive experiments demonstrate the superior reconstruction quality of the proposed approach over existing baselines across various INR tasks, including image fitting, video representation, and 3D shape representation. Our method outperforms all other baselines, improving the image fitting PSNR by over 3dB and 3D reconstruction to 98.81 IoU and 0.0011 Chamfer Distance.
A Unifying Tensor View for Lightweight CNNs
Dec 15, 2023Despite the decomposition of convolutional kernels for lightweight CNNs being well studied, existing works that rely on tensor network diagrams or hyperdimensional abstraction lack geometry intuition. This work devises a new perspective by linking a 3D-reshaped kernel tensor to its various slice-wise and rank-1 decompositions, permitting a straightforward connection between various tensor approximations and efficient CNN modules. Specifically, it is discovered that a pointwise-depthwise-pointwise (PDP) configuration constitutes a viable construct for lightweight CNNs. Moreover, a novel link to the latest ShiftNet is established, inspiring a first-ever shift layer pruning that achieves nearly 50% compression with < 1% drop in accuracy for ShiftResNet.
Hundred-Kilobyte Lookup Tables for Efficient Single-Image Super-Resolution
Dec 11, 2023Conventional super-resolution (SR) schemes make heavy use of convolutional neural networks (CNNs), which involve intensive multiply-accumulate (MAC) operations, and require specialized hardware such as graphics processing units. This contradicts the regime of edge AI that often runs on devices strained by power, computing, and storage resources. Such a challenge has motivated a series of lookup table (LUT)-based SR schemes that employ simple LUT readout and largely elude CNN computation. Nonetheless, the multi-megabyte LUTs in existing methods still prohibit on-chip storage and necessitate off-chip memory transport. This work tackles this storage hurdle and innovates hundred-kilobyte LUT (HKLUT) models amenable to on-chip cache. Utilizing an asymmetric two-branch multistage network coupled with a suite of specialized kernel patterns, HKLUT demonstrates an uncompromising performance and superior hardware efficiency over existing LUT schemes.
Lite it fly: An All-Deformable-Butterfly Network
Nov 14, 2023

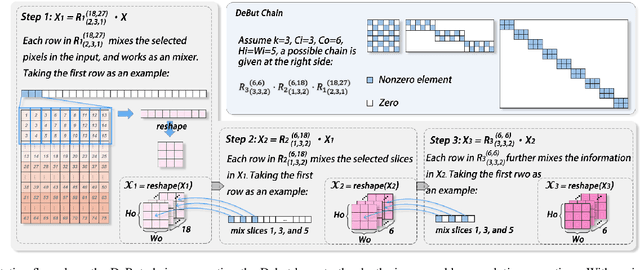

Most deep neural networks (DNNs) consist fundamentally of convolutional and/or fully connected layers, wherein the linear transform can be cast as the product between a filter matrix and a data matrix obtained by arranging feature tensors into columns. The lately proposed deformable butterfly (DeBut) decomposes the filter matrix into generalized, butterflylike factors, thus achieving network compression orthogonal to the traditional ways of pruning or low-rank decomposition. This work reveals an intimate link between DeBut and a systematic hierarchy of depthwise and pointwise convolutions, which explains the empirically good performance of DeBut layers. By developing an automated DeBut chain generator, we show for the first time the viability of homogenizing a DNN into all DeBut layers, thus achieving an extreme sparsity and compression. Various examples and hardware benchmarks verify the advantages of All-DeBut networks. In particular, we show it is possible to compress a PointNet to < 5% parameters with < 5% accuracy drop, a record not achievable by other compression schemes.
PECAN: A Product-Quantized Content Addressable Memory Network
Aug 13, 2022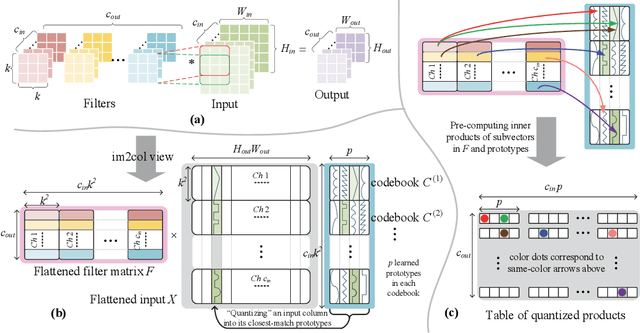

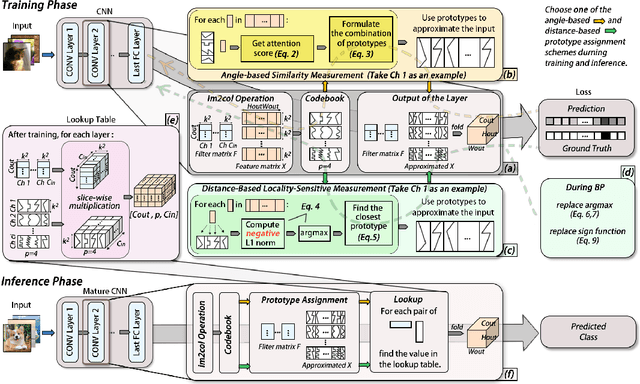
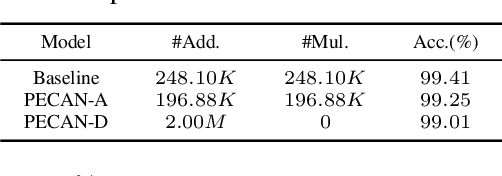
A novel deep neural network (DNN) architecture is proposed wherein the filtering and linear transform are realized solely with product quantization (PQ). This results in a natural implementation via content addressable memory (CAM), which transcends regular DNN layer operations and requires only simple table lookup. Two schemes are developed for the end-to-end PQ prototype training, namely, through angle- and distance-based similarities, which differ in their multiplicative and additive natures with different complexity-accuracy tradeoffs. Even more, the distance-based scheme constitutes a truly multiplier-free DNN solution. Experiments confirm the feasibility of such Product-Quantized Content Addressable Memory Network (PECAN), which has strong implication on hardware-efficient deployments especially for in-memory computing.