 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Perspective To Understanding Multi-resolution Hash Encoding For Neural Fields
May 05, 2025



Instant-NGP has been the state-of-the-art architecture of neural fields in recent years. Its incredible signal-fitting capabilities are generally attributed to its multi-resolution hash grid structure and have been used and improved in numerous following works. However, it is unclear how and why such a hash grid structure improves the capabilities of a neural network by such great margins. A lack of principled understanding of the hash grid also implies that the large set of hyperparameters accompanying Instant-NGP could only be tuned empirically without much heuristics. To provide an intuitive explanation of the working principle of the hash grid, we propose a novel perspective, namely domain manipulation. This perspective provides a ground-up explanation of how the feature grid learns the target signal and increases the expressivity of the neural field by artificially creating multiples of pre-existing linear segments. We conducted numerous experiments on carefully constructed 1-dimensional signals to support our claims empirically and aid our illustrations. While our analysis mainly focuses on 1-dimensional signals, we show that the idea is generalizable to higher dimensions.
ASMR: Activation-sharing Multi-resolution Coordinate Networks For Efficient Inference
May 20, 2024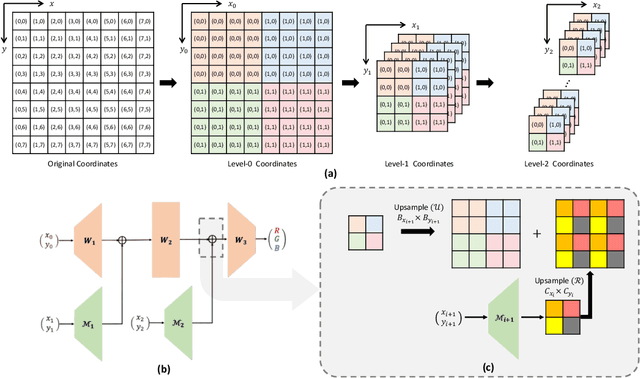
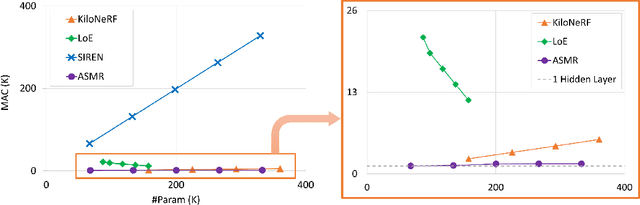
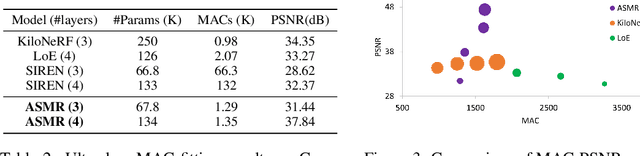
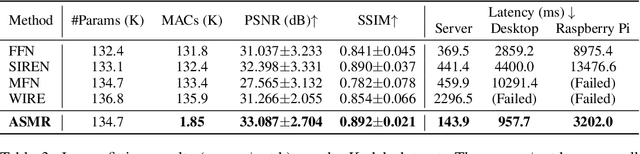
Coordinate network or implicit neural representation (INR) is a fast-emerging method for encoding natural signals (such as images and videos) with the benefits of a compact neural representation. While numerous methods have been proposed to increase the encoding capabilities of an INR, an often overlooked aspect is the inference efficiency, usually measured in multiply-accumulate (MAC) count. This is particularly critical in use cases where inference throughput is greatly limited by hardware constraints. To this end, we propose the Activation-Sharing Multi-Resolution (ASMR) coordinate network that combines multi-resolution coordinate decomposition with hierarchical modulations. Specifically, an ASMR model enables the sharing of activations across grids of the data. This largely decouples its inference cost from its depth which is directly correlated to its reconstruction capability, and renders a near O(1) inference complexity irrespective of the number of layers. Experiments show that ASMR can reduce the MAC of a vanilla SIREN model by up to 500x while achieving an even higher reconstruction quality than its SIREN baseline.
Nonparametric Teaching of Implicit Neural Representations
May 17, 2024We investigate the learning of implicit neural representation (INR) using an overparameterized multilayer perceptron (MLP) via a novel nonparametric teaching perspective. The latter offers an efficient example selection framework for teaching nonparametrically defined (viz. non-closed-form) target functions, such as image functions defined by 2D grids of pixels. To address the costly training of INRs, we propose a paradigm called Implicit Neural Teaching (INT) that treats INR learning as a nonparametric teaching problem, where the given signal being fitted serves as the target function. The teacher then selects signal fragments for iterative training of the MLP to achieve fast convergence. By establishing a connection between MLP evolution through parameter-based gradient descent and that of function evolution through functional gradient descent in nonparametric teaching, we show for the first time that teaching an overparameterized MLP is consistent with teaching a nonparametric learner. This new discovery readily permits a convenient drop-in of nonparametric teaching algorithms to broadly enhance INR training efficiency, demonstrating 30%+ training time savings across various input modalities.