 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJARVIS: An Evidence-Grounded Retrieval System for Interpretable Deceptive Reviews Adjudication
Feb 13, 2026Deceptive reviews, refer to fabricated feedback designed to artificially manipulate the perceived quality of products. Within modern e-commerce ecosystems, these reviews remain a critical governance challenge. Despite advances in review-level and graph-based detection methods, two pivotal limitations remain: inadequate generalization and lack of interpretability. To address these challenges, we propose JARVIS, a framework providing Judgment via Augmented Retrieval and eVIdence graph Structures. Starting from the review to be evaluated, it retrieves semantically similar evidence via hybrid dense-sparse multimodal retrieval, expands relational signals through shared entities, and constructs a heterogeneous evidence graph. Large language model then performs evidence-grounded adjudication to produce interpretable risk assessments. Offline experiments demonstrate that JARVIS enhances performance on our constructed review dataset, achieving a precision increase from 0.953 to 0.988 and a recall boost from 0.830 to 0.901. In the production environment, our framework achieves a 27% increase in the recall volume and reduces manual inspection time by 75%. Furthermore, the adoption rate of the model-generated analysis reaches 96.4%.
VULCAN: Tool-Augmented Multi Agents for Iterative 3D Object Arrangement
Dec 26, 2025Despite the remarkable progress of Multimodal Large Language Models (MLLMs) in 2D vision-language tasks, their application to complex 3D scene manipulation remains underexplored. In this paper, we bridge this critical gap by tackling three key challenges in 3D object arrangement task using MLLMs. First, to address the weak visual grounding of MLLMs, which struggle to link programmatic edits with precise 3D outcomes, we introduce an MCP-based API. This shifts the interaction from brittle raw code manipulation to more robust, function-level updates. Second, we augment the MLLM's 3D scene understanding with a suite of specialized visual tools to analyze scene state, gather spatial information, and validate action outcomes. This perceptual feedback loop is critical for closing the gap between language-based updates and precise 3D-aware manipulation. Third, to manage the iterative, error-prone updates, we propose a collaborative multi-agent framework with designated roles for planning, execution, and verification. This decomposition allows the system to robustly handle multi-step instructions and recover from intermediate errors. We demonstrate the effectiveness of our approach on a diverse set of 25 complex object arrangement tasks, where it significantly outperforms existing baselines. Website: vulcan-3d.github.io
Back to Ear: Perceptually Driven High Fidelity Music Reconstruction
Sep 18, 2025Variational Autoencoders (VAEs) are essential for large-scale audio tasks like diffusion-based generation. However, existing open-source models often neglect auditory perceptual aspects during training, leading to weaknesses in phase accuracy and stereophonic spatial representation. To address these challenges, we propose {\epsilon}ar-VAE, an open-source music signal reconstruction model that rethinks and optimizes the VAE training paradigm. Our contributions are threefold: (i) A K-weighting perceptual filter applied prior to loss calculation to align the objective with auditory perception. (ii) Two novel phase losses: a Correlation Loss for stereo coherence, and a Phase Loss using its derivatives--Instantaneous Frequency and Group Delay--for precision. (iii) A new spectral supervision paradigm where magnitude is supervised by all four Mid/Side/Left/Right components, while phase is supervised only by the LR components. Experiments show {\epsilon}ar-VAE at 44.1kHz substantially outperforms leading open-source models across diverse metrics, showing particular strength in reconstructing high-frequency harmonics and the spatial characteristics.
Towards Understanding the Nature of Attention with Low-Rank Sparse Decomposition
Apr 29, 2025We propose Low-Rank Sparse Attention (Lorsa), a sparse replacement model of Transformer attention layers to disentangle original Multi Head Self Attention (MHSA) into individually comprehensible components. Lorsa is designed to address the challenge of attention superposition to understand attention-mediated interaction between features in different token positions. We show that Lorsa heads find cleaner and finer-grained versions of previously discovered MHSA behaviors like induction heads, successor heads and attention sink behavior (i.e., heavily attending to the first token). Lorsa and Sparse Autoencoder (SAE) are both sparse dictionary learning methods applied to different Transformer components, and lead to consistent findings in many ways. For instance, we discover a comprehensive family of arithmetic-specific Lorsa heads, each corresponding to an atomic operation in Llama-3.1-8B. Automated interpretability analysis indicates that Lorsa achieves parity with SAE in interpretability while Lorsa exhibits superior circuit discovery properties, especially for features computed collectively by multiple MHSA heads. We also conduct extensive experiments on architectural design ablation, Lorsa scaling law and error analysis.
A Unifying Tensor View for Lightweight CNNs
Dec 15, 2023Despite the decomposition of convolutional kernels for lightweight CNNs being well studied, existing works that rely on tensor network diagrams or hyperdimensional abstraction lack geometry intuition. This work devises a new perspective by linking a 3D-reshaped kernel tensor to its various slice-wise and rank-1 decompositions, permitting a straightforward connection between various tensor approximations and efficient CNN modules. Specifically, it is discovered that a pointwise-depthwise-pointwise (PDP) configuration constitutes a viable construct for lightweight CNNs. Moreover, a novel link to the latest ShiftNet is established, inspiring a first-ever shift layer pruning that achieves nearly 50% compression with < 1% drop in accuracy for ShiftResNet.
Lite it fly: An All-Deformable-Butterfly Network
Nov 14, 2023

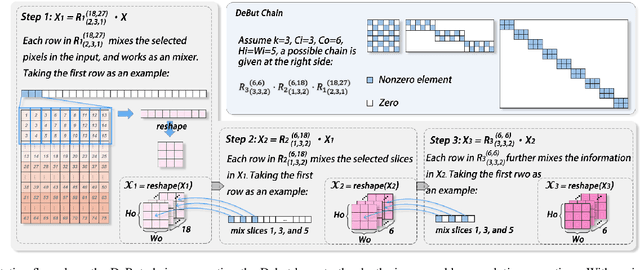

Most deep neural networks (DNNs) consist fundamentally of convolutional and/or fully connected layers, wherein the linear transform can be cast as the product between a filter matrix and a data matrix obtained by arranging feature tensors into columns. The lately proposed deformable butterfly (DeBut) decomposes the filter matrix into generalized, butterflylike factors, thus achieving network compression orthogonal to the traditional ways of pruning or low-rank decomposition. This work reveals an intimate link between DeBut and a systematic hierarchy of depthwise and pointwise convolutions, which explains the empirically good performance of DeBut layers. By developing an automated DeBut chain generator, we show for the first time the viability of homogenizing a DNN into all DeBut layers, thus achieving an extreme sparsity and compression. Various examples and hardware benchmarks verify the advantages of All-DeBut networks. In particular, we show it is possible to compress a PointNet to < 5% parameters with < 5% accuracy drop, a record not achievable by other compression schemes.
Cluster-based Method for Eavesdropping Identification and Localization in Optical Links
Sep 25, 2023



We propose a cluster-based method to detect and locate eavesdropping events in optical line systems characterized by small power losses. Our findings indicate that detecting such subtle losses from eavesdropping can be accomplished solely through optical performance monitoring (OPM) data collected at the receiver. On the other hand, the localization of such events can be effectively achieved by leveraging in-line OPM data.
A Spectral Perspective towards Understanding and Improving Adversarial Robustness
Jun 25, 2023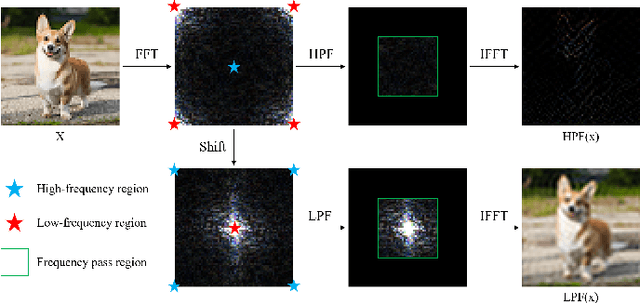
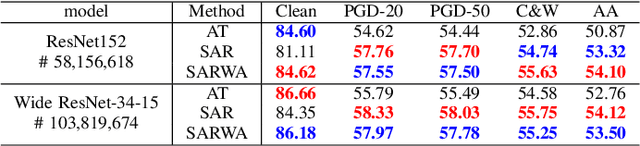


Deep neural networks (DNNs) are incredibly vulnerable to crafted, imperceptible adversarial perturbations. While adversarial training (AT) has proven to be an effective defense approach, the AT mechanism for robustness improvement is not fully understood. This work investigates AT from a spectral perspective, adding new insights to the design of effective defenses. In particular, we show that AT induces the deep model to focus more on the low-frequency region, which retains the shape-biased representations, to gain robustness. Further, we find that the spectrum of a white-box attack is primarily distributed in regions the model focuses on, and the perturbation attacks the spectral bands where the model is vulnerable. Based on this observation, to train a model tolerant to frequency-varying perturbation, we propose a spectral alignment regularization (SAR) such that the spectral output inferred by an attacked adversarial input stays as close as possible to its natural input counterpart. Experiments demonstrate that SAR and its weight averaging (WA) extension could significantly improve the robust accuracy by 1.14% ~ 3.87% relative to the standard AT, across multiple datasets (CIFAR-10, CIFAR-100 and Tiny ImageNet), and various attacks (PGD, C&W and Autoattack), without any extra data.
Frequency Regularization for Improving Adversarial Robustness
Dec 24, 2022



Deep neural networks are incredibly vulnerable to crafted, human-imperceptible adversarial perturbations. Although adversarial training (AT) has proven to be an effective defense approach, we find that the AT-trained models heavily rely on the input low-frequency content for judgment, accounting for the low standard accuracy. To close the large gap between the standard and robust accuracies during AT, we investigate the frequency difference between clean and adversarial inputs, and propose a frequency regularization (FR) to align the output difference in the spectral domain. Besides, we find Stochastic Weight Averaging (SWA), by smoothing the kernels over epochs, further improves the robustness. Among various defense schemes, our method achieves the strongest robustness against attacks by PGD-20, C\&W and Autoattack, on a WideResNet trained on CIFAR-10 without any extra data.
PECAN: A Product-Quantized Content Addressable Memory Network
Aug 13, 2022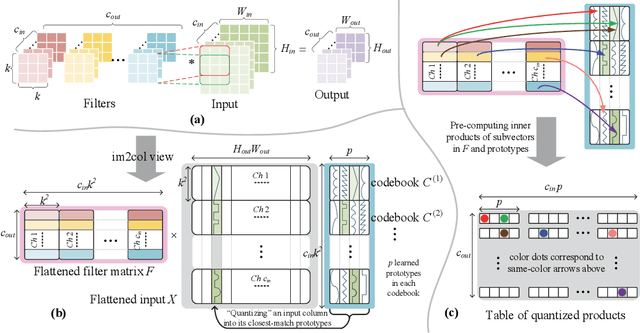

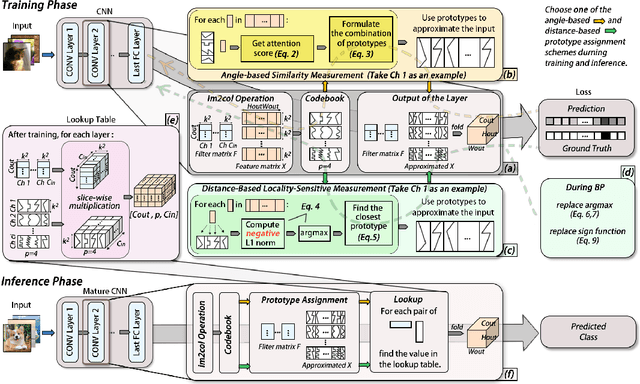
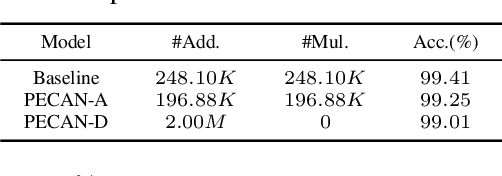
A novel deep neural network (DNN) architecture is proposed wherein the filtering and linear transform are realized solely with product quantization (PQ). This results in a natural implementation via content addressable memory (CAM), which transcends regular DNN layer operations and requires only simple table lookup. Two schemes are developed for the end-to-end PQ prototype training, namely, through angle- and distance-based similarities, which differ in their multiplicative and additive natures with different complexity-accuracy tradeoffs. Even more, the distance-based scheme constitutes a truly multiplier-free DNN solution. Experiments confirm the feasibility of such Product-Quantized Content Addressable Memory Network (PECAN), which has strong implication on hardware-efficient deployments especially for in-memory computing.