 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Layers Add Into Low-Dimensional Residual Subspaces
Aug 23, 2025While transformer models are widely believed to operate in high-dimensional hidden spaces, we show that attention outputs are confined to a surprisingly low-dimensional subspace, where about 60\% of the directions account for 99\% of the variance--a phenomenon that is induced by the attention output projection matrix and consistently observed across diverse model families and datasets. Critically, we find this low-rank structure as a fundamental cause of the prevalent dead feature problem in sparse dictionary learning, where it creates a mismatch between randomly initialized features and the intrinsic geometry of the activation space. Building on this insight, we propose a subspace-constrained training method for sparse autoencoders (SAEs), initializing feature directions into the active subspace of activations. Our approach reduces dead features from 87\% to below 1\% in Attention Output SAEs with 1M features, and can further extend to other sparse dictionary learning methods. Our findings provide both new insights into the geometry of attention and practical tools for improving sparse dictionary learning in large language models.
Towards Understanding the Nature of Attention with Low-Rank Sparse Decomposition
Apr 29, 2025We propose Low-Rank Sparse Attention (Lorsa), a sparse replacement model of Transformer attention layers to disentangle original Multi Head Self Attention (MHSA) into individually comprehensible components. Lorsa is designed to address the challenge of attention superposition to understand attention-mediated interaction between features in different token positions. We show that Lorsa heads find cleaner and finer-grained versions of previously discovered MHSA behaviors like induction heads, successor heads and attention sink behavior (i.e., heavily attending to the first token). Lorsa and Sparse Autoencoder (SAE) are both sparse dictionary learning methods applied to different Transformer components, and lead to consistent findings in many ways. For instance, we discover a comprehensive family of arithmetic-specific Lorsa heads, each corresponding to an atomic operation in Llama-3.1-8B. Automated interpretability analysis indicates that Lorsa achieves parity with SAE in interpretability while Lorsa exhibits superior circuit discovery properties, especially for features computed collectively by multiple MHSA heads. We also conduct extensive experiments on architectural design ablation, Lorsa scaling law and error analysis.
Llama Scope: Extracting Millions of Features from Llama-3.1-8B with Sparse Autoencoders
Oct 27, 2024



Sparse Autoencoders (SAEs) have emerged as a powerful unsupervised method for extracting sparse representations from language models, yet scalable training remains a significant challenge. We introduce a suite of 256 SAEs, trained on each layer and sublayer of the Llama-3.1-8B-Base model, with 32K and 128K features. Modifications to a state-of-the-art SAE variant, Top-K SAEs, are evaluated across multiple dimensions. In particular, we assess the generalizability of SAEs trained on base models to longer contexts and fine-tuned models. Additionally, we analyze the geometry of learned SAE latents, confirming that \emph{feature splitting} enables the discovery of new features. The Llama Scope SAE checkpoints are publicly available at~\url{https://huggingface.co/fnlp/Llama-Scope}, alongside our scalable training, interpretation, and visualization tools at \url{https://github.com/OpenMOSS/Language-Model-SAEs}. These contributions aim to advance the open-source Sparse Autoencoder ecosystem and support mechanistic interpretability research by reducing the need for redundant SAE training.
Towards Universality: Studying Mechanistic Similarity Across Language Model Architectures
Oct 10, 2024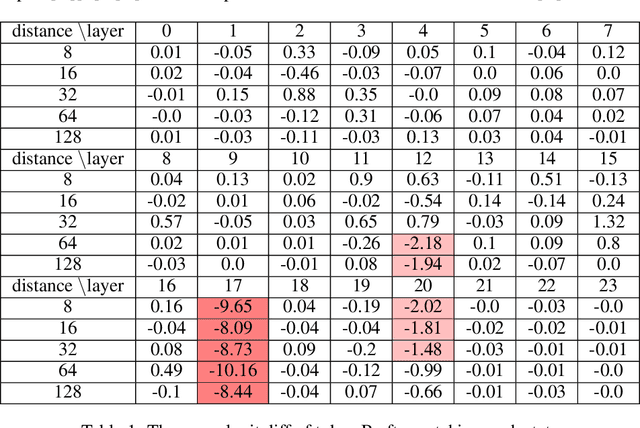
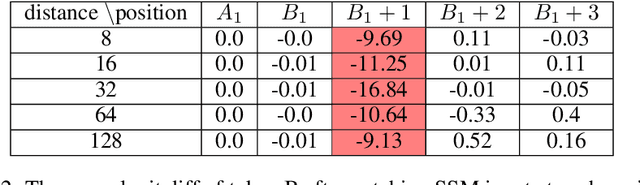

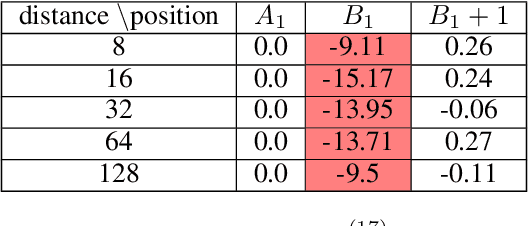
The hypothesis of Universality in interpretability suggests that different neural networks may converge to implement similar algorithms on similar tasks. In this work, we investigate two mainstream architectures for language modeling, namely Transformers and Mambas, to explore the extent of their mechanistic similarity. We propose to use Sparse Autoencoders (SAEs) to isolate interpretable features from these models and show that most features are similar in these two models. We also validate the correlation between feature similarity and Universality. We then delve into the circuit-level analysis of Mamba models and find that the induction circuits in Mamba are structurally analogous to those in Transformers. We also identify a nuanced difference we call \emph{Off-by-One motif}: The information of one token is written into the SSM state in its next position. Whilst interaction between tokens in Transformers does not exhibit such trend.
Automatically Identifying Local and Global Circuits with Linear Computation Graphs
May 22, 2024



Circuit analysis of any certain model behavior is a central task in mechanistic interpretability. We introduce our circuit discovery pipeline with sparse autoencoders (SAEs) and a variant called skip SAEs. With these two modules inserted into the model, the model's computation graph with respect to OV and MLP circuits becomes strictly linear. Our methods do not require linear approximation to compute the causal effect of each node. This fine-grained graph enables identifying both end-to-end and local circuits accounting for either logits or intermediate features. We can scalably apply this pipeline with a technique called Hierarchical Attribution. We analyze three kind of circuits in GPT2-Small, namely bracket, induction and Indirect Object Identification circuits. Our results reveal new findings underlying existing discoveries.
Dictionary Learning Improves Patch-Free Circuit Discovery in Mechanistic Interpretability: A Case Study on Othello-GPT
Feb 19, 2024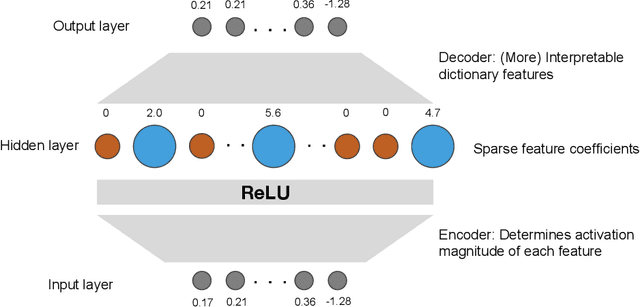

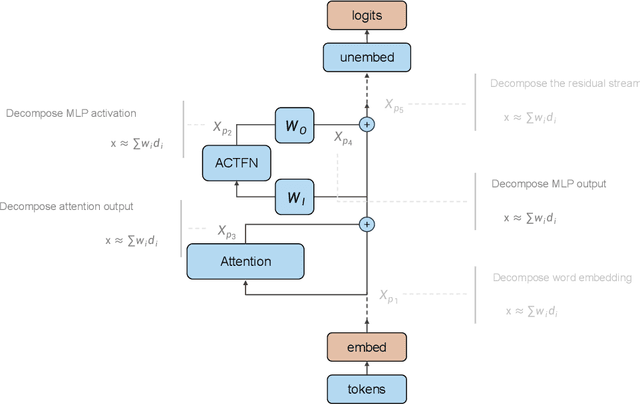
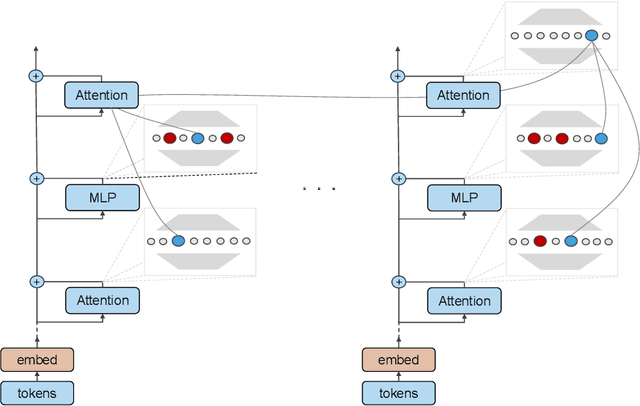
Sparse dictionary learning has been a rapidly growing technique in mechanistic interpretability to attack superposition and extract more human-understandable features from model activations. We ask a further question based on the extracted more monosemantic features: How do we recognize circuits connecting the enormous amount of dictionary features? We propose a circuit discovery framework alternative to activation patching. Our framework suffers less from out-of-distribution and proves to be more efficient in terms of asymptotic complexity. The basic unit in our framework is dictionary features decomposed from all modules writing to the residual stream, including embedding, attention output and MLP output. Starting from any logit, dictionary feature or attention score, we manage to trace down to lower-level dictionary features of all tokens and compute their contribution to these more interpretable and local model behaviors. We dig in a small transformer trained on a synthetic task named Othello and find a number of human-understandable fine-grained circuits inside of it.
Can AI Assistants Know What They Don't Know?
Jan 28, 2024
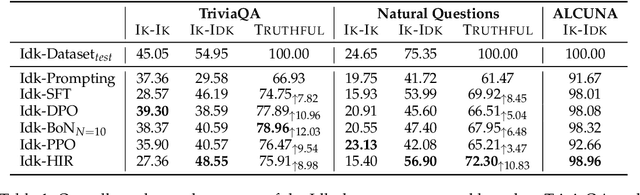

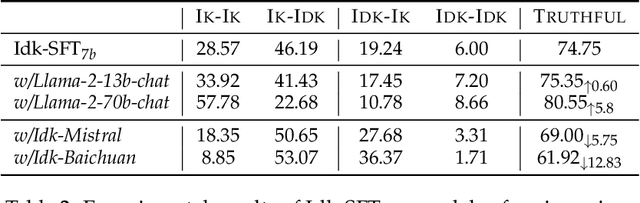
Recently, AI assistants based on large language models (LLMs) show surprising performance in many tasks, such as dialogue, solving math problems, writing code, and using tools. Although LLMs possess intensive world knowledge, they still make factual errors when facing some knowledge intensive tasks, like open-domain question answering. These untruthful responses from the AI assistant may cause significant risks in practical applications. We believe that an AI assistant's refusal to answer questions it does not know is a crucial method for reducing hallucinations and making the assistant truthful. Therefore, in this paper, we ask the question "Can AI assistants know what they don't know and express them through natural language?" To answer this question, we construct a model-specific "I don't know" (Idk) dataset for an assistant, which contains its known and unknown questions, based on existing open-domain question answering datasets. Then we align the assistant with its corresponding Idk dataset and observe whether it can refuse to answer its unknown questions after alignment. Experimental results show that after alignment with Idk datasets, the assistant can refuse to answer most its unknown questions. For questions they attempt to answer, the accuracy is significantly higher than before the alignment.
DiffusionBERT: Improving Generative Masked Language Models with Diffusion Models
Nov 30, 2022We present DiffusionBERT, a new generative masked language model based on discrete diffusion models. Diffusion models and many pre-trained language models have a shared training objective, i.e., denoising, making it possible to combine the two powerful models and enjoy the best of both worlds. On the one hand, diffusion models offer a promising training strategy that helps improve the generation quality. On the other hand, pre-trained denoising language models (e.g., BERT) can be used as a good initialization that accelerates convergence. We explore training BERT to learn the reverse process of a discrete diffusion process with an absorbing state and elucidate several designs to improve it. First, we propose a new noise schedule for the forward diffusion process that controls the degree of noise added at each step based on the information of each token. Second, we investigate several designs of incorporating the time step into BERT. Experiments on unconditional text generation demonstrate that DiffusionBERT achieves significant improvement over existing diffusion models for text (e.g., D3PM and Diffusion-LM) and previous generative masked language models in terms of perplexity and BLEU score.
Multi-Task Pre-Training of Modular Prompt for Few-Shot Learning
Oct 14, 2022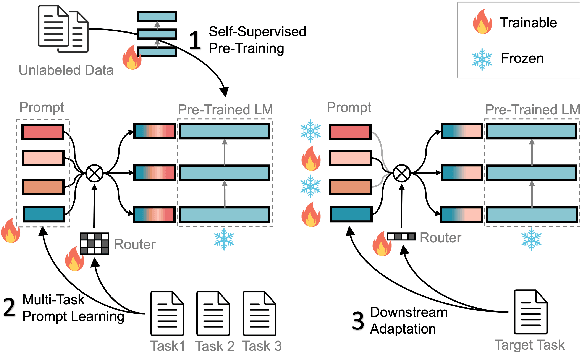
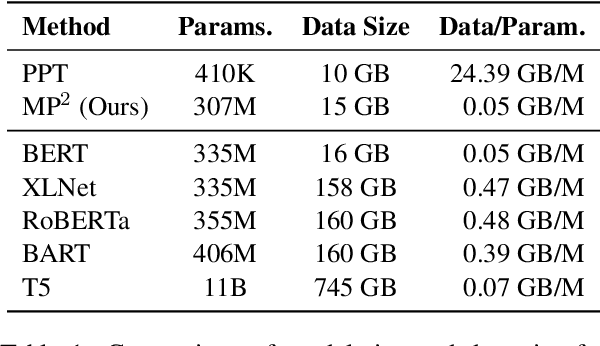
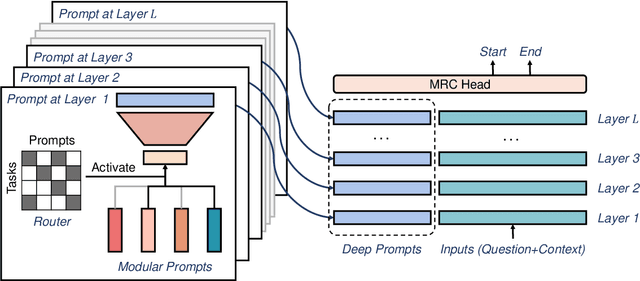
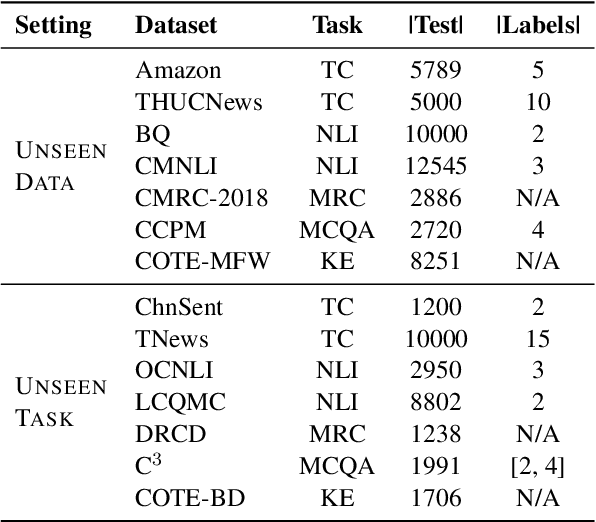
Prompt tuning is a parameter-efficient approach to adapting pre-trained language models to downstream tasks. Although prompt tuning has been shown to match the performance of full model tuning when training data is sufficient, it tends to struggle in few-shot learning settings. In this paper, we present Multi-task Pre-trained Modular Prompt (MP2) to boost prompt tuning for few-shot learning. MP2 is a set of combinable prompts pre-trained on 38 Chinese tasks. On downstream tasks, the pre-trained prompts are selectively activated and combined, leading to strong compositional generalization to unseen tasks. To bridge the gap between pre-training and fine-tuning, we formulate upstream and downstream tasks into a unified machine reading comprehension task. Extensive experiments under two learning paradigms, i.e., gradient descent and black-box tuning, show that MP2 significantly outperforms prompt tuning, full model tuning, and prior prompt pre-training methods in few-shot settings. In addition, we demonstrate that MP2 can achieve surprisingly fast and strong adaptation to downstream tasks by merely learning 8 parameters to combine the pre-trained modular prompts.
BBTv2: Pure Black-Box Optimization Can Be Comparable to Gradient Descent for Few-Shot Learning
May 23, 2022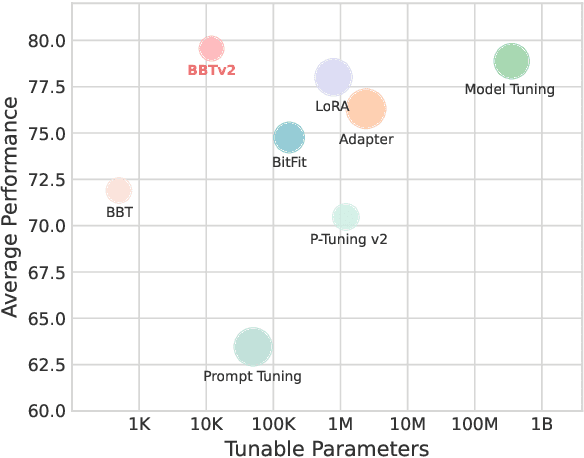
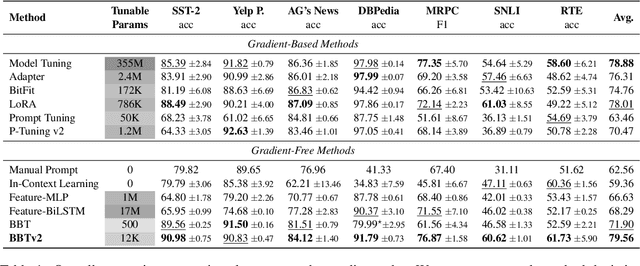
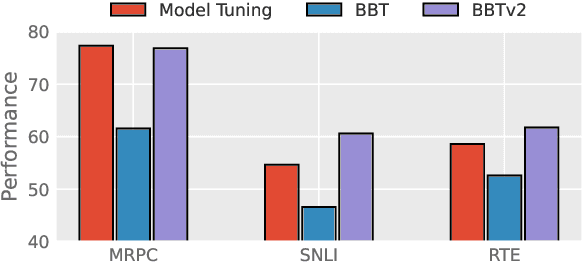
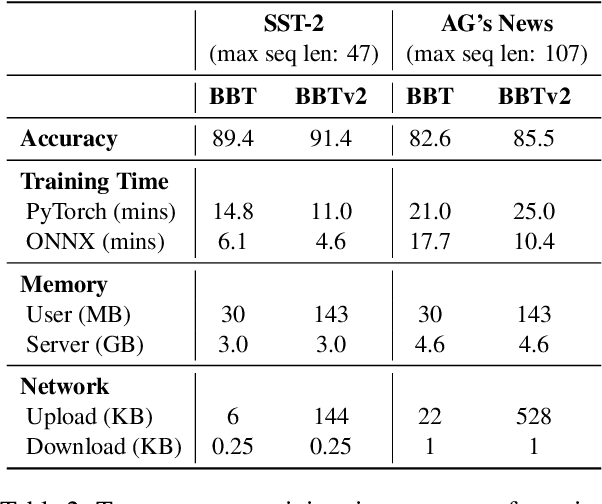
Black-Box Tuning (BBT) is a derivative-free approach to optimize continuous prompt tokens prepended to the input of language models. Although BBT has achieved comparable performance to full model tuning on simple classification tasks under few-shot settings, it requires pre-trained prompt embedding to match model tuning on hard tasks (e.g., entailment tasks), and therefore does not completely get rid of the dependence on gradients. In this paper we present BBTv2, a pure black-box optimization approach that can drive language models to achieve comparable results to gradient-based optimization. In particular, we prepend continuous prompt tokens to every layer of the language model and propose a divide-and-conquer algorithm to alternately optimize the prompt tokens at different layers. For the optimization at each layer, we perform derivative-free optimization in a low-dimensional subspace, which is then randomly projected to the original prompt parameter space. Experimental results show that BBTv2 not only outperforms BBT by a large margin, but also achieves comparable or even better performance than full model tuning and state-of-the-art parameter-efficient methods (e.g., Adapter, LoRA, BitFit, etc.) under few-shot learning settings, while maintaining much fewer tunable parameters.