 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAV-SyncBench: Decoupled Benchmarking of Temporal and Semantic Audio-Visual Synchronization
Jul 01, 2026Audio-visual feature extraction is a fundamental component of multimodal understanding and generation tasks. However, existing evaluation protocols for feature extraction models exhibit dimensional bias, typically focusing on either semantic matching or temporal offset detection. Moreover, their data construction remains coupled, preventing independent assessment of temporal and semantic consistency. We propose AV-SyncBench, the first benchmark to fully separate temporal and semantic evaluation for audio-visual synchronization. Built from in-the-wild videos, it spans Voice, Music, and Sound across 10 scenarios and 5 challenge tasks. Data are automatically filtered and manually verified to ensure on-screen sound sources. The benchmark contains 3,269 videos and 38,390 samples, and we evaluate five representative models to quantify feature quality for alignment and downstream tasks. The code and dataset are available at: https://fgt7t6g.github.io/AV-SyncBench.
FreeSonic: Training-Free Temporal-Aware Decoupled Attention for Precise Audio Editing
Jun 13, 2026Text-to-audio (TTA) generation has made significant strides, yet achieving precise and consistent audio editing remains a major challenge. However, existing methods struggle to balance temporal consistency with background preservation. In this paper, we propose FreeSonic, a training-free framework leveraging the state-of-the-art Rectified Flow-based TangoFlux model. FreeSonic utilizes an optimized inversion-reverse process and joint text-audio attention maps for precise target segment extraction. For content editing, a novel scheduled attention decoupling confines modifications to target regions while preserving original acoustic context. Furthermore, task-oriented noise injection enhances versatility for tasks such as audio removal and non-rigid replacement. Extensive experimental results demonstrate that FreeSonic achieves a superior balance by providing a high-fidelity and efficient solution for precise and consistent audio editing. Project and demos: https://free-sonic.github.io/
X-DiffVLA: X-Embodied Diffusion Action Heads for Vision-Language-Action Models
May 24, 2026Learning universal policies from cross-embodied data remains a fundamental challenge in robotics. Although Vision-Language-Action (VLA) models are pre-trained on large and diverse datasets, they typically rely on embodiment-specific fine-tuning to achieve strong performance in downstream tasks. This requirement severely limits their generalization capability and restricts knowledge transfer across embodiments performing similar tasks. To overcome these limitations, we focus on cross-embodied settings with shared robotic bases and heterogeneous end-effectors, and propose X-DiffVLA, a diffusion-based VLA model featuring a unified cross-embodied action head. X-DiffVLA can leverage the generative strengths of diffusion models to capture both the diversity and latent correlations in cross-embodied datasets. Specifically, we introduce Embodiment Forcing, a classifier-free guidance technique to implicitly steer action generation toward embodiment-specific functional components, capturing fine-grained structural nuances without explicit supervision. In addition, a Morphological Tree Diffusion approach is designed to strengthen behavioral correlations across diverse end-effectors, maximizing the transferability of heterogeneous demonstrations. Experimental results across RoboCasa and Isaac Gym, covering different embodiments from grippers to dexterous hands, show that X-DiffVLA achieves state-of-the-art performance, with improvements of 15.3% and 12.5%, respectively. Real-world evaluations further validate the robustness of the proposed framework and its effectiveness in scalable cross-embodied policy learning.
Real-Time Human Activity Recognition on Edge Microcontrollers: Dynamic Hierarchical Inference with Multi-Spectral Sensor Fusion
Jan 29, 2026The demand for accurate on-device pattern recognition in edge applications is intensifying, yet existing approaches struggle to reconcile accuracy with computational constraints. To address this challenge, a resource-aware hierarchical network based on multi-spectral fusion and interpretable modules, namely the Hierarchical Parallel Pseudo-image Enhancement Fusion Network (HPPI-Net), is proposed for real-time, on-device Human Activity Recognition (HAR). Deployed on an ARM Cortex-M4 microcontroller for low-power real-time inference, HPPI-Net achieves 96.70% accuracy while utilizing only 22.3 KiB of RAM and 439.5 KiB of ROM after optimization. HPPI-Net employs a two-layer architecture. The first layer extracts preliminary features using Fast Fourier Transform (FFT) spectrograms, while the second layer selectively activates either a dedicated module for stationary activity recognition or a parallel LSTM-MobileNet network (PLMN) for dynamic states. PLMN fuses FFT, Wavelet, and Gabor spectrograms through three parallel LSTM encoders and refines the concatenated features using Efficient Channel Attention (ECA) and Depthwise Separable Convolution (DSC), thereby offering channel-level interpretability while substantially reducing multiply-accumulate operations. Compared with MobileNetV3, HPPI-Net improves accuracy by 1.22% and reduces RAM usage by 71.2% and ROM usage by 42.1%. These results demonstrate that HPPI-Net achieves a favorable accuracy-efficiency trade-off and provides explainable predictions, establishing a practical solution for wearable, industrial, and smart home HAR on memory-constrained edge platforms.
Soft Responsive Materials Enhance Humanoid Safety
Jan 06, 2026Humanoid robots are envisioned as general-purpose platforms in human-centered environments, yet their deployment is limited by vulnerability to falls and the risks posed by rigid metal-plastic structures to people and surroundings. We introduce a soft-rigid co-design framework that leverages non-Newtonian fluid-based soft responsive materials to enhance humanoid safety. The material remains compliant during normal interaction but rapidly stiffens under impact, absorbing and dissipating fall-induced forces. Physics-based simulations guide protector placement and thickness and enable learning of active fall policies. Applied to a 42 kg life-size humanoid, the protector markedly reduces peak impact and allows repeated falls without hardware damage, including drops from 3 m and tumbles down long staircases. Across diverse scenarios, the approach improves robot robustness and environmental safety. By uniting responsive materials, structural co-design, and learning-based control, this work advances interact-safe, industry-ready humanoid robots.
Reconstruction as a Bridge for Event-Based Visual Question Answering
Dec 12, 2025Integrating event cameras with Multimodal Large Language Models (MLLMs) promises general scene understanding in challenging visual conditions, yet requires navigating a trade-off between preserving the unique advantages of event data and ensuring compatibility with frame-based models. We address this challenge by using reconstruction as a bridge, proposing a straightforward Frame-based Reconstruction and Tokenization (FRT) method and designing an efficient Adaptive Reconstruction and Tokenization (ART) method that leverages event sparsity. For robust evaluation, we introduce EvQA, the first objective, real-world benchmark for event-based MLLMs, comprising 1,000 event-Q&A pairs from 22 public datasets. Our experiments demonstrate that our methods achieve state-of-the-art performance on EvQA, highlighting the significant potential of MLLMs in event-based vision.
Time-Layer Adaptive Alignment for Speaker Similarity in Flow-Matching Based Zero-Shot TTS
Nov 13, 2025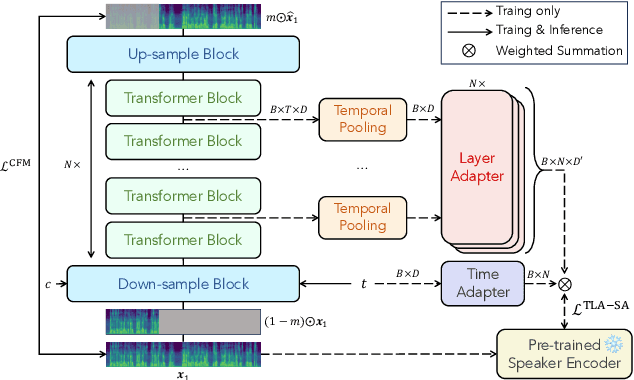

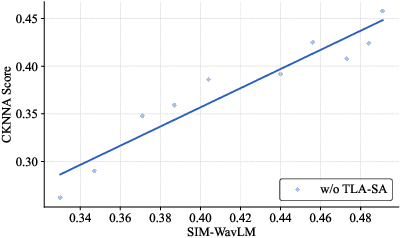

Flow-Matching (FM)-based zero-shot text-to-speech (TTS) systems exhibit high-quality speech synthesis and robust generalization capabilities. However, the speaker representation ability of such systems remains underexplored, primarily due to the lack of explicit speaker-specific supervision in the FM framework. To this end, we conduct an empirical analysis of speaker information distribution and reveal its non-uniform allocation across time steps and network layers, underscoring the need for adaptive speaker alignment. Accordingly, we propose Time-Layer Adaptive Speaker Alignment (TLA-SA), a loss that enhances speaker consistency by jointly leveraging temporal and hierarchical variations in speaker information. Experimental results show that TLA-SA significantly improves speaker similarity compared to baseline systems on both research- and industrial-scale datasets and generalizes effectively across diverse model architectures, including decoder-only language models (LM) and FM-based TTS systems free of LM.
Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Oct 09, 2025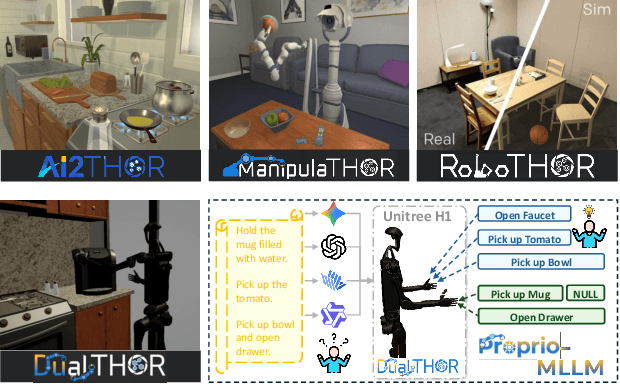


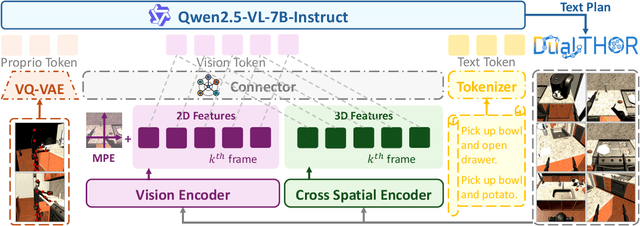
In recent years, Multimodal Large Language Models (MLLMs) have demonstrated the ability to serve as high-level planners, enabling robots to follow complex human instructions. However, their effectiveness, especially in long-horizon tasks involving dual-arm humanoid robots, remains limited. This limitation arises from two main challenges: (i) the absence of simulation platforms that systematically support task evaluation and data collection for humanoid robots, and (ii) the insufficient embodiment awareness of current MLLMs, which hinders reasoning about dual-arm selection logic and body positions during planning. To address these issues, we present DualTHOR, a new dual-arm humanoid simulator, with continuous transition and a contingency mechanism. Building on this platform, we propose Proprio-MLLM, a model that enhances embodiment awareness by incorporating proprioceptive information with motion-based position embedding and a cross-spatial encoder. Experiments show that, while existing MLLMs struggle in this environment, Proprio-MLLM achieves an average improvement of 19.75% in planning performance. Our work provides both an essential simulation platform and an effective model to advance embodied intelligence in humanoid robotics. The code is available at https://anonymous.4open.science/r/DualTHOR-5F3B.
QuadINR: Hardware-Efficient Implicit Neural Representations Through Quadratic Activation
Aug 20, 2025Implicit Neural Representations (INRs) encode discrete signals continuously while addressing spectral bias through activation functions (AFs). Previous approaches mitigate this bias by employing complex AFs, which often incur significant hardware overhead. To tackle this challenge, we introduce QuadINR, a hardware-efficient INR that utilizes piecewise quadratic AFs to achieve superior performance with dramatic reductions in hardware consumption. The quadratic functions encompass rich harmonic content in their Fourier series, delivering enhanced expressivity for high-frequency signals, as verified through Neural Tangent Kernel (NTK) analysis. We develop a unified $N$-stage pipeline framework that facilitates efficient hardware implementation of various AFs in INRs. We demonstrate FPGA implementations on the VCU128 platform and an ASIC implementation in a 28nm process. Experiments across images and videos show that QuadINR achieves up to 2.06dB PSNR improvement over prior work, with an area of only 1914$\mu$m$^2$ and a dynamic power of 6.14mW, reducing resource and power consumption by up to 97\% and improving latency by up to 93\% vs existing baselines.
Petri Net Modeling and Deadlock-Free Scheduling of Attachable Heterogeneous AGV Systems
Aug 01, 2025
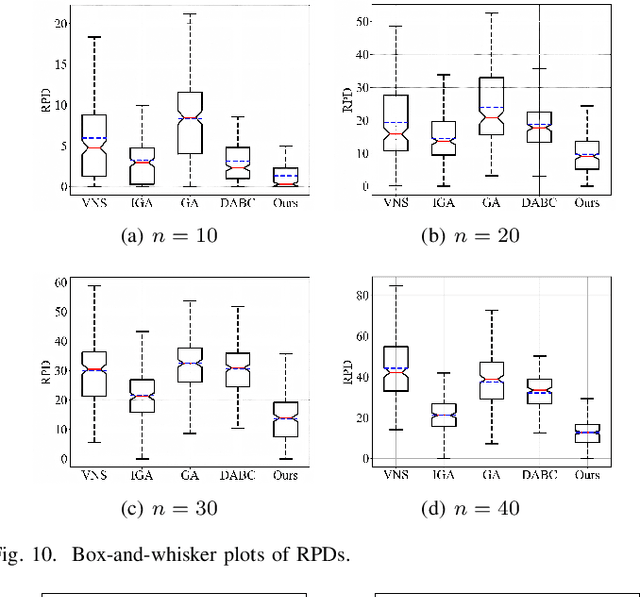
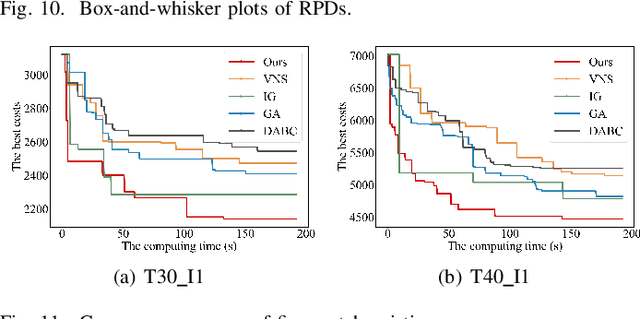
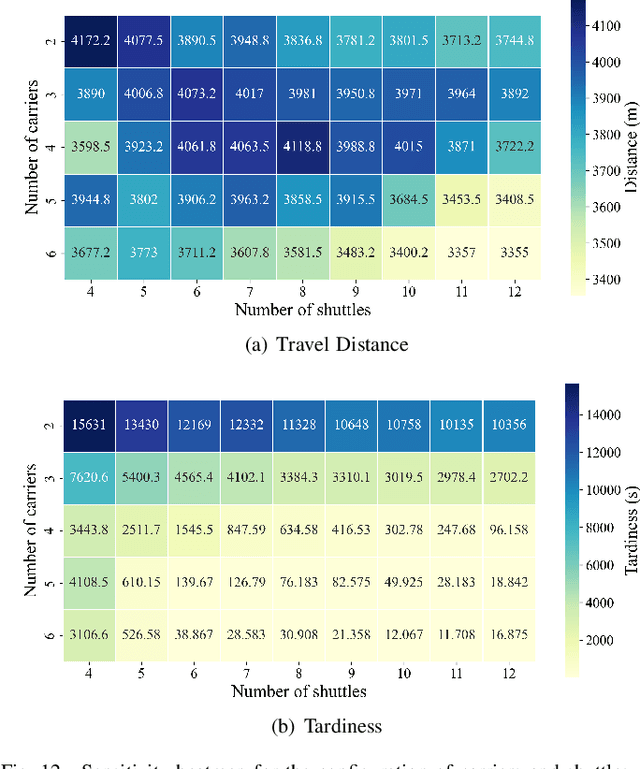
The increasing demand for automation and flexibility drives the widespread adoption of heterogeneous automated guided vehicles (AGVs). This work intends to investigate a new scheduling problem in a material transportation system consisting of attachable heterogeneous AGVs, namely carriers and shuttles. They can flexibly attach to and detach from each other to cooperatively execute complex transportation tasks. While such collaboration enhances operational efficiency, the attachment-induced synchronization and interdependence render the scheduling coupled and susceptible to deadlock. To tackle this challenge, Petri nets are introduced to model AGV schedules, well describing the concurrent and sequential task execution and carrier-shuttle synchronization. Based on Petri net theory, a firing-driven decoding method is proposed, along with deadlock detection and prevention strategies to ensure deadlock-free schedules. Furthermore, a Petri net-based metaheuristic is developed in an adaptive large neighborhood search framework and incorporates an effective acceleration method to enhance computational efficiency. Finally, numerical experiments using real-world industrial data validate the effectiveness of the proposed algorithm against the scheduling policy applied in engineering practice, an exact solver, and four state-of-the-art metaheuristics. A sensitivity analysis is also conducted to provide managerial insights.