 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymplectic Reservoir Representation of Legendre Dynamics
Dec 22, 2025Modern learning systems act on internal representations of data, yet how these representations encode underlying physical or statistical structure is often left implicit. In physics, conservation laws of Hamiltonian systems such as symplecticity guarantee long-term stability, and recent work has begun to hard-wire such constraints into learning models at the loss or output level. Here we ask a different question: what would it mean for the representation itself to obey a symplectic conservation law in the sense of Hamiltonian mechanics? We express this symplectic constraint through Legendre duality: the pairing between primal and dual parameters, which becomes the structure that the representation must preserve. We formalize Legendre dynamics as stochastic processes whose trajectories remain on Legendre graphs, so that the evolving primal-dual parameters stay Legendre dual. We show that this class includes linear time-invariant Gaussian process regression and Ornstein-Uhlenbeck dynamics. Geometrically, we prove that the maps that preserve all Legendre graphs are exactly symplectomorphisms of cotangent bundles of the form "cotangent lift of a base diffeomorphism followed by an exact fibre translation". Dynamically, this characterization leads to the design of a Symplectic Reservoir (SR), a reservoir-computing architecture that is a special case of recurrent neural network and whose recurrent core is generated by Hamiltonian systems that are at most linear in the momentum. Our main theorem shows that every SR update has this normal form and therefore transports Legendre graphs to Legendre graphs, preserving Legendre duality at each time step. Overall, SR implements a geometrically constrained, Legendre-preserving representation map, injecting symplectic geometry and Hamiltonian mechanics directly at the representational level.
Structuring Multiple Simple Cycle Reservoirs with Particle Swarm Optimization
Apr 06, 2025Reservoir Computing (RC) is a time-efficient computational paradigm derived from Recurrent Neural Networks (RNNs). The Simple Cycle Reservoir (SCR) is an RC model that stands out for its minimalistic design, offering extremely low construction complexity and proven capability of universally approximating time-invariant causal fading memory filters, even in the linear dynamics regime. This paper introduces Multiple Simple Cycle Reservoirs (MSCRs), a multi-reservoir framework that extends Echo State Networks (ESNs) by replacing a single large reservoir with multiple interconnected SCRs. We demonstrate that optimizing MSCR using Particle Swarm Optimization (PSO) outperforms existing multi-reservoir models, achieving competitive predictive performance with a lower-dimensional state space. By modeling interconnections as a weighted Directed Acyclic Graph (DAG), our approach enables flexible, task-specific network topology adaptation. Numerical simulations on three benchmark time-series prediction tasks confirm these advantages over rival algorithms. These findings highlight the potential of MSCR-PSO as a promising framework for optimizing multi-reservoir systems, providing a foundation for further advancements and applications of interconnected SCRs for developing efficient AI devices.
Linear Simple Cycle Reservoirs at the edge of stability perform Fourier decomposition of the input driving signals
Nov 30, 2024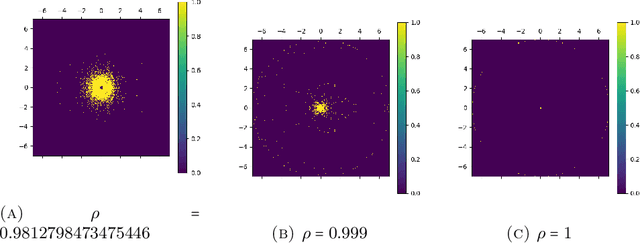
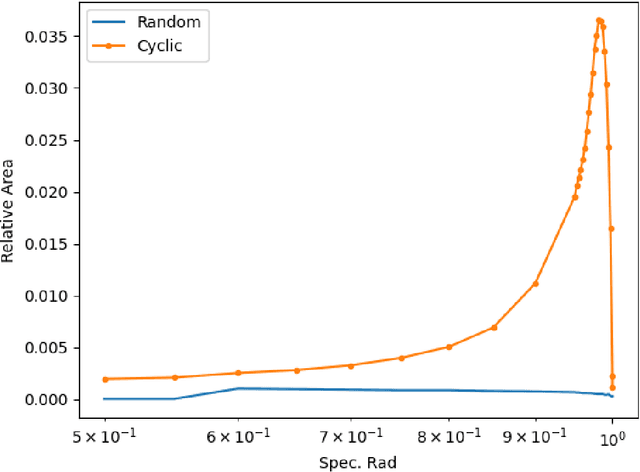
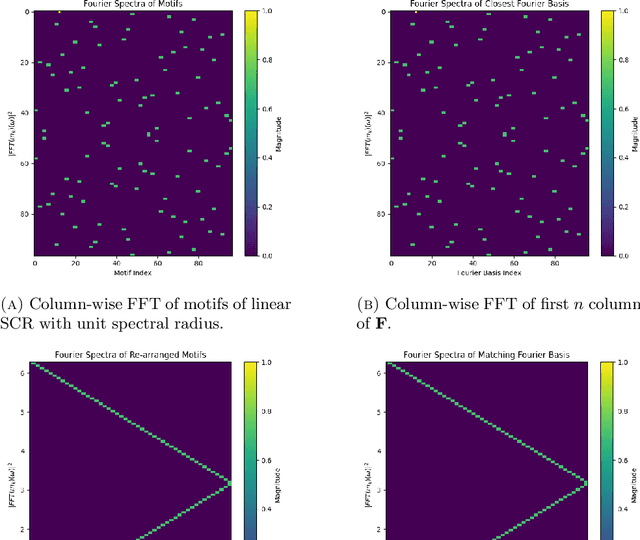
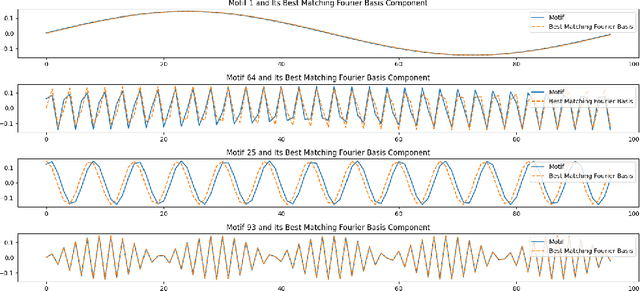
This paper explores the representational structure of linear Simple Cycle Reservoirs (SCR) operating at the edge of stability. We view SCR as providing in their state space feature representations of the input-driving time series. By endowing the state space with the canonical dot-product, we ``reverse engineer" the corresponding kernel (inner product) operating in the original time series space. The action of this time-series kernel is fully characterized by the eigenspace of the corresponding metric tensor. We demonstrate that when linear SCRs are constructed at the edge of stability, the eigenvectors of the time-series kernel align with the Fourier basis. This theoretical insight is supported by numerical experiments.
Universality of Real Minimal Complexity Reservoir
Aug 15, 2024


Reservoir Computing (RC) models, a subclass of recurrent neural networks, are distinguished by their fixed, non-trainable input layer and dynamically coupled reservoir, with only the static readout layer being trained. This design circumvents the issues associated with backpropagating error signals through time, thereby enhancing both stability and training efficiency. RC models have been successfully applied across a broad range of application domains. Crucially, they have been demonstrated to be universal approximators of time-invariant dynamic filters with fading memory, under various settings of approximation norms and input driving sources. Simple Cycle Reservoirs (SCR) represent a specialized class of RC models with a highly constrained reservoir architecture, characterized by uniform ring connectivity and binary input-to-reservoir weights with an aperiodic sign pattern. For linear reservoirs, given the reservoir size, the reservoir construction has only one degree of freedom -- the reservoir cycle weight. Such architectures are particularly amenable to hardware implementations without significant performance degradation in many practical tasks. In this study we endow these observations with solid theoretical foundations by proving that SCRs operating in real domain are universal approximators of time-invariant dynamic filters with fading memory. Our results supplement recent research showing that SCRs in the complex domain can approximate, to arbitrary precision, any unrestricted linear reservoir with a non-linear readout. We furthermore introduce a novel method to drastically reduce the number of SCR units, making such highly constrained architectures natural candidates for low-complexity hardware implementations. Our findings are supported by empirical studies on real-world time series datasets.
Predictive Modeling in the Reservoir Kernel Motif Space
May 11, 2024



This work proposes a time series prediction method based on the kernel view of linear reservoirs. In particular, the time series motifs of the reservoir kernel are used as representational basis on which general readouts are constructed. We provide a geometric interpretation of our approach shedding light on how our approach is related to the core reservoir models and in what way the two approaches differ. Empirical experiments then compare predictive performances of our suggested model with those of recent state-of-art transformer based models, as well as the established recurrent network model - LSTM. The experiments are performed on both univariate and multivariate time series and with a variety of prediction horizons. Rather surprisingly we show that even when linear readout is employed, our method has the capacity to outperform transformer models on univariate time series and attain competitive results on multivariate benchmark datasets. We conclude that simple models with easily controllable capacity but capturing enough memory and subsequence structure can outperform potentially over-complicated deep learning models. This does not mean that reservoir motif based models are preferable to other more complex alternatives - rather, when introducing a new complex time series model one should employ as a sanity check simple, but potentially powerful alternatives/baselines such as reservoir models or the models introduced here.
Simple Cycle Reservoirs are Universal
Aug 21, 2023

Reservoir computation models form a subclass of recurrent neural networks with fixed non-trainable input and dynamic coupling weights. Only the static readout from the state space (reservoir) is trainable, thus avoiding the known problems with propagation of gradient information backwards through time. Reservoir models have been successfully applied in a variety of tasks and were shown to be universal approximators of time-invariant fading memory dynamic filters under various settings. Simple cycle reservoirs (SCR) have been suggested as severely restricted reservoir architecture, with equal weight ring connectivity of the reservoir units and input-to-reservoir weights of binary nature with the same absolute value. Such architectures are well suited for hardware implementations without performance degradation in many practical tasks. In this contribution, we rigorously study the expressive power of SCR in the complex domain and show that they are capable of universal approximation of any unrestricted linear reservoir system (with continuous readout) and hence any time-invariant fading memory filter over uniformly bounded input streams.