 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymplectic Reservoir Representation of Legendre Dynamics
Dec 22, 2025Modern learning systems act on internal representations of data, yet how these representations encode underlying physical or statistical structure is often left implicit. In physics, conservation laws of Hamiltonian systems such as symplecticity guarantee long-term stability, and recent work has begun to hard-wire such constraints into learning models at the loss or output level. Here we ask a different question: what would it mean for the representation itself to obey a symplectic conservation law in the sense of Hamiltonian mechanics? We express this symplectic constraint through Legendre duality: the pairing between primal and dual parameters, which becomes the structure that the representation must preserve. We formalize Legendre dynamics as stochastic processes whose trajectories remain on Legendre graphs, so that the evolving primal-dual parameters stay Legendre dual. We show that this class includes linear time-invariant Gaussian process regression and Ornstein-Uhlenbeck dynamics. Geometrically, we prove that the maps that preserve all Legendre graphs are exactly symplectomorphisms of cotangent bundles of the form "cotangent lift of a base diffeomorphism followed by an exact fibre translation". Dynamically, this characterization leads to the design of a Symplectic Reservoir (SR), a reservoir-computing architecture that is a special case of recurrent neural network and whose recurrent core is generated by Hamiltonian systems that are at most linear in the momentum. Our main theorem shows that every SR update has this normal form and therefore transports Legendre graphs to Legendre graphs, preserving Legendre duality at each time step. Overall, SR implements a geometrically constrained, Legendre-preserving representation map, injecting symplectic geometry and Hamiltonian mechanics directly at the representational level.
Enhancing Time-Series Anomaly Detection by Integrating Spectral-Residual Bottom-Up Attention with Reservoir Computing
Oct 16, 2025Reservoir computing (RC) establishes the basis for the processing of time-series data by exploiting the high-dimensional spatiotemporal response of a recurrent neural network to an input signal. In particular, RC trains only the output layer weights. This simplicity has drawn attention especially in Edge Artificial Intelligence (AI) applications. Edge AI enables time-series anomaly detection in real time, which is important because detection delays can lead to serious incidents. However, achieving adequate anomaly-detection performance with RC alone may require an unacceptably large reservoir on resource-constrained edge devices. Without enlarging the reservoir, attention mechanisms can improve accuracy, although they may require substantial computation and undermine the learning efficiency of RC. In this study, to improve the anomaly detection performance of RC without sacrificing learning efficiency, we propose a spectral residual RC (SR-RC) that integrates the spectral residual (SR) method - a learning-free, bottom-up attention mechanism - with RC. We demonstrated that SR-RC outperformed conventional RC and logistic-regression models based on values extracted by the SR method across benchmark tasks and real-world time-series datasets. Moreover, because the SR method, similarly to RC, is well suited for hardware implementation, SR-RC suggests a practical direction for deploying RC as Edge AI for time-series anomaly detection.
Attractor-merging Crises and Intermittency in Reservoir Computing
Apr 17, 2025Reservoir computing can embed attractors into random neural networks (RNNs), generating a ``mirror'' of a target attractor because of its inherent symmetrical constraints. In these RNNs, we report that an attractor-merging crisis accompanied by intermittency emerges simply by adjusting the global parameter. We further reveal its underlying mechanism through a detailed analysis of the phase-space structure and demonstrate that this bifurcation scenario is intrinsic to a general class of RNNs, independent of training data.
Structuring Multiple Simple Cycle Reservoirs with Particle Swarm Optimization
Apr 06, 2025Reservoir Computing (RC) is a time-efficient computational paradigm derived from Recurrent Neural Networks (RNNs). The Simple Cycle Reservoir (SCR) is an RC model that stands out for its minimalistic design, offering extremely low construction complexity and proven capability of universally approximating time-invariant causal fading memory filters, even in the linear dynamics regime. This paper introduces Multiple Simple Cycle Reservoirs (MSCRs), a multi-reservoir framework that extends Echo State Networks (ESNs) by replacing a single large reservoir with multiple interconnected SCRs. We demonstrate that optimizing MSCR using Particle Swarm Optimization (PSO) outperforms existing multi-reservoir models, achieving competitive predictive performance with a lower-dimensional state space. By modeling interconnections as a weighted Directed Acyclic Graph (DAG), our approach enables flexible, task-specific network topology adaptation. Numerical simulations on three benchmark time-series prediction tasks confirm these advantages over rival algorithms. These findings highlight the potential of MSCR-PSO as a promising framework for optimizing multi-reservoir systems, providing a foundation for further advancements and applications of interconnected SCRs for developing efficient AI devices.
Brain-inspired Chaotic Graph Backpropagation for Large-scale Combinatorial Optimization
Dec 13, 2024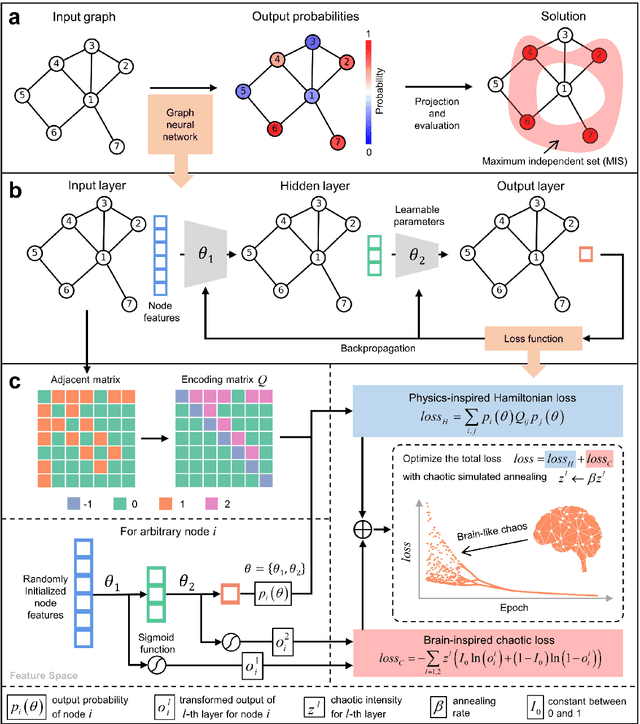
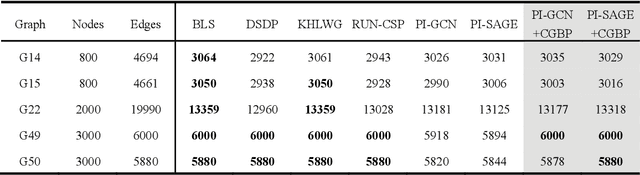
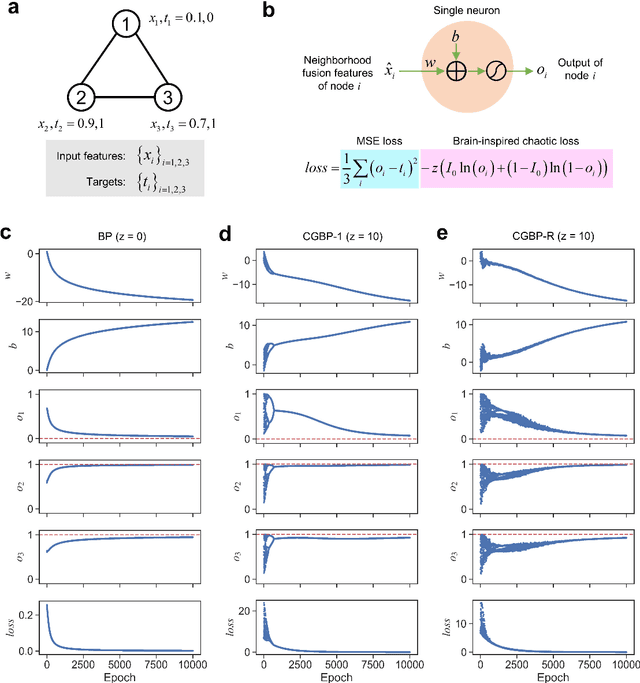
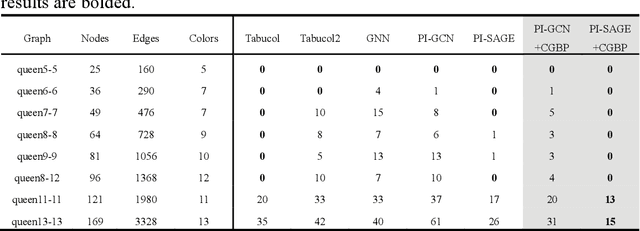
Graph neural networks (GNNs) with unsupervised learning can solve large-scale combinatorial optimization problems (COPs) with efficient time complexity, making them versatile for various applications. However, since this method maps the combinatorial optimization problem to the training process of a graph neural network, and the current mainstream backpropagation-based training algorithms are prone to fall into local minima, the optimization performance is still inferior to the current state-of-the-art (SOTA) COP methods. To address this issue, inspired by possibly chaotic dynamics of real brain learning, we introduce a chaotic training algorithm, i.e. chaotic graph backpropagation (CGBP), which introduces a local loss function in GNN that makes the training process not only chaotic but also highly efficient. Different from existing methods, we show that the global ergodicity and pseudo-randomness of such chaotic dynamics enable CGBP to learn each optimal GNN effectively and globally, thus solving the COP efficiently. We have applied CGBP to solve various COPs, such as the maximum independent set, maximum cut, and graph coloring. Results on several large-scale benchmark datasets showcase that CGBP can outperform not only existing GNN algorithms but also SOTA methods. In addition to solving large-scale COPs, CGBP as a universal learning algorithm for GNNs, i.e. as a plug-in unit, can be easily integrated into any existing method for improving the performance.
Training Physical Neural Networks for Analog In-Memory Computing
Dec 12, 2024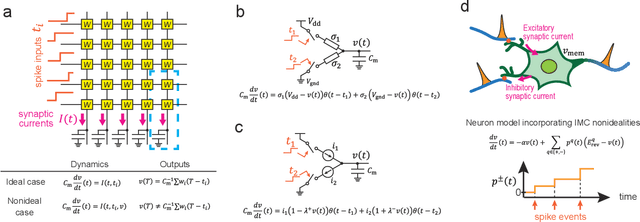
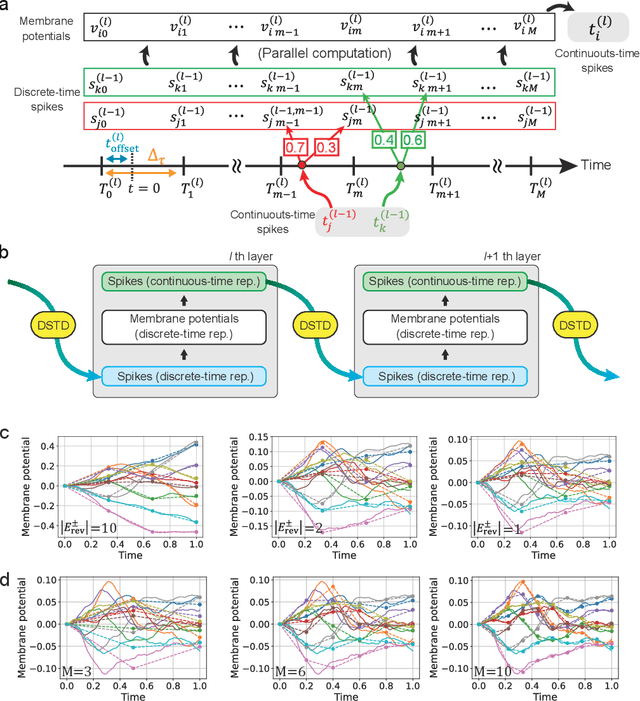
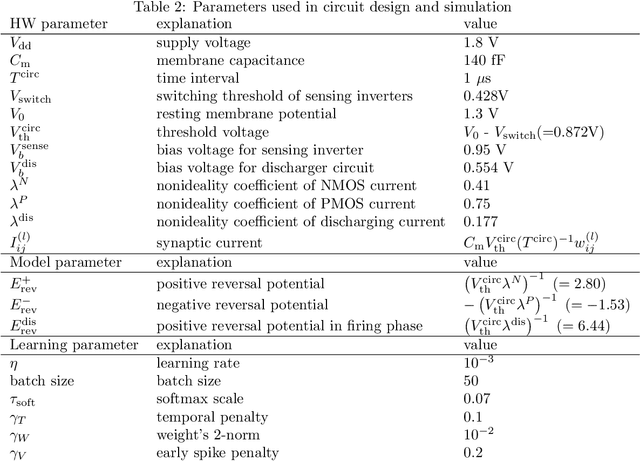
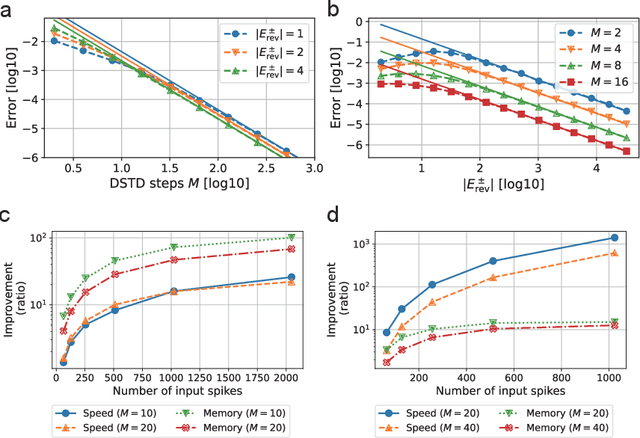
In-memory computing (IMC) architectures mitigate the von Neumann bottleneck encountered in traditional deep learning accelerators. Its energy efficiency can realize deep learning-based edge applications. However, because IMC is implemented using analog circuits, inherent non-idealities in the hardware pose significant challenges. This paper presents physical neural networks (PNNs) for constructing physical models of IMC. PNNs can address the synaptic current's dependence on membrane potential, a challenge in charge-domain IMC systems. The proposed model is mathematically equivalent to spiking neural networks with reversal potentials. With a novel technique called differentiable spike-time discretization, the PNNs are efficiently trained. We show that hardware non-idealities traditionally viewed as detrimental can enhance the model's learning performance. This bottom-up methodology was validated by designing an IMC circuit with non-ideal characteristics using the sky130 process. When employing this bottom-up approach, the modeling error reduced by an order of magnitude compared to conventional top-down methods in post-layout simulations.
Deciphering interventional dynamical causality from non-intervention systems
Jun 29, 2024
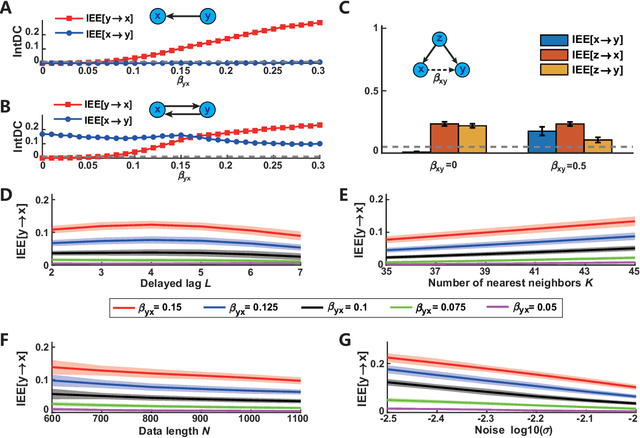
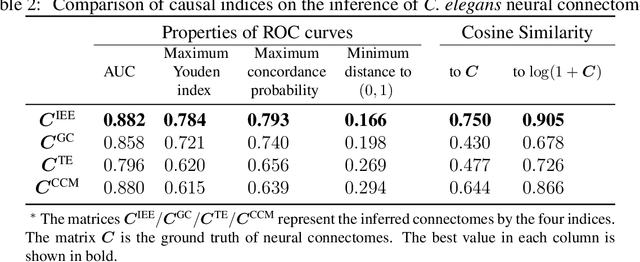
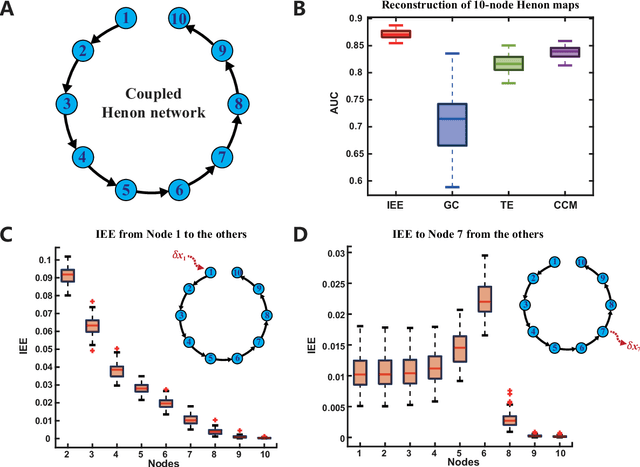
Detecting and quantifying causality is a focal topic in the fields of science, engineering, and interdisciplinary studies. However, causal studies on non-intervention systems attract much attention but remain extremely challenging. To address this challenge, we propose a framework named Interventional Dynamical Causality (IntDC) for such non-intervention systems, along with its computational criterion, Interventional Embedding Entropy (IEE), to quantify causality. The IEE criterion theoretically and numerically enables the deciphering of IntDC solely from observational (non-interventional) time-series data, without requiring any knowledge of dynamical models or real interventions in the considered system. Demonstrations of performance showed the accuracy and robustness of IEE on benchmark simulated systems as well as real-world systems, including the neural connectomes of C. elegans, COVID-19 transmission networks in Japan, and regulatory networks surrounding key circadian genes.
Predicting unobserved climate time series data at distant areas via spatial correlation using reservoir computing
Jun 05, 2024Collecting time series data spatially distributed in many locations is often important for analyzing climate change and its impacts on ecosystems. However, comprehensive spatial data collection is not always feasible, requiring us to predict climate variables at some locations. This study focuses on a prediction of climatic elements, specifically near-surface temperature and pressure, at a target location apart from a data observation point. Our approach uses two prediction methods: reservoir computing (RC), known as a machine learning framework with low computational requirements, and vector autoregression models (VAR), recognized as a statistical method for analyzing time series data. Our results show that the accuracy of the predictions degrades with the distance between the observation and target locations. We quantitatively estimate the distance in which effective predictions are possible. We also find that in the context of climate data, a geographical distance is associated with data correlation, and a strong data correlation significantly improves the prediction accuracy with RC. In particular, RC outperforms VAR in predicting highly correlated data within the predictive range. These findings suggest that machine learning-based methods can be used more effectively to predict climatic elements in remote locations by assessing the distance to them from the data observation point in advance. Our study on low-cost and accurate prediction of climate variables has significant value for climate change strategies.
Chaos-based reinforcement learning with TD3
May 15, 2024Chaos-based reinforcement learning (CBRL) is a method in which the agent's internal chaotic dynamics drives exploration. This approach offers a model for considering how the biological brain can create variability in its behavior and learn in an exploratory manner. At the same time, it is a learning model that has the ability to automatically switch between exploration and exploitation modes and the potential to realize higher explorations that reflect what it has learned so far. However, the learning algorithms in CBRL have not been well-established in previous studies and have yet to incorporate recent advances in reinforcement learning. This study introduced Twin Delayed Deep Deterministic Policy Gradients (TD3), which is one of the state-of-the-art deep reinforcement learning algorithms that can treat deterministic and continuous action spaces, to CBRL. The validation results provide several insights. First, TD3 works as a learning algorithm for CBRL in a simple goal-reaching task. Second, CBRL agents with TD3 can autonomously suppress their exploratory behavior as learning progresses and resume exploration when the environment changes. Finally, examining the effect of the agent's chaoticity on learning shows that extremely strong chaos negatively impacts the flexible switching between exploration and exploitation.
Trained Latent Space Navigation to Prevent Lack of Photorealism in Generated Images on Style-based Models
Oct 02, 2023



Recent studies on StyleGAN variants show promising performances for various generation tasks. In these models, latent codes have traditionally been manipulated and searched for the desired images. However, this approach sometimes suffers from a lack of photorealism in generated images due to a lack of knowledge about the geometry of the trained latent space. In this paper, we show a simple unsupervised method that provides well-trained local latent subspace, enabling latent code navigation while preserving the photorealism of the generated images. Specifically, the method identifies densely mapped latent spaces and restricts latent manipulations within the local latent subspace. Experimental results demonstrate that images generated within the local latent subspace maintain photorealism even when the latent codes are significantly and repeatedly manipulated. Moreover, experiments show that the method can be applied to latent code optimization for various types of style-based models. Our empirical evidence of the method will benefit applications in style-based models.