 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Time-Series Anomaly Detection by Integrating Spectral-Residual Bottom-Up Attention with Reservoir Computing
Oct 16, 2025Reservoir computing (RC) establishes the basis for the processing of time-series data by exploiting the high-dimensional spatiotemporal response of a recurrent neural network to an input signal. In particular, RC trains only the output layer weights. This simplicity has drawn attention especially in Edge Artificial Intelligence (AI) applications. Edge AI enables time-series anomaly detection in real time, which is important because detection delays can lead to serious incidents. However, achieving adequate anomaly-detection performance with RC alone may require an unacceptably large reservoir on resource-constrained edge devices. Without enlarging the reservoir, attention mechanisms can improve accuracy, although they may require substantial computation and undermine the learning efficiency of RC. In this study, to improve the anomaly detection performance of RC without sacrificing learning efficiency, we propose a spectral residual RC (SR-RC) that integrates the spectral residual (SR) method - a learning-free, bottom-up attention mechanism - with RC. We demonstrated that SR-RC outperformed conventional RC and logistic-regression models based on values extracted by the SR method across benchmark tasks and real-world time-series datasets. Moreover, because the SR method, similarly to RC, is well suited for hardware implementation, SR-RC suggests a practical direction for deploying RC as Edge AI for time-series anomaly detection.
Learning the Simplest Neural ODE
May 04, 2025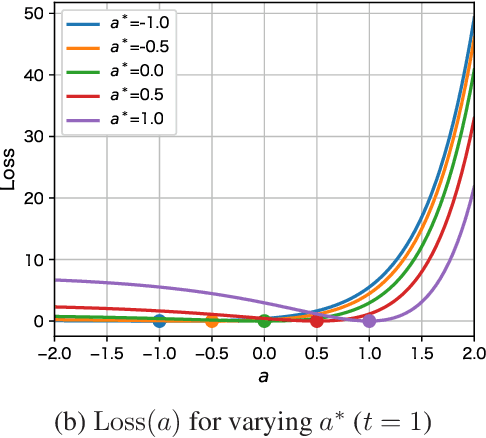
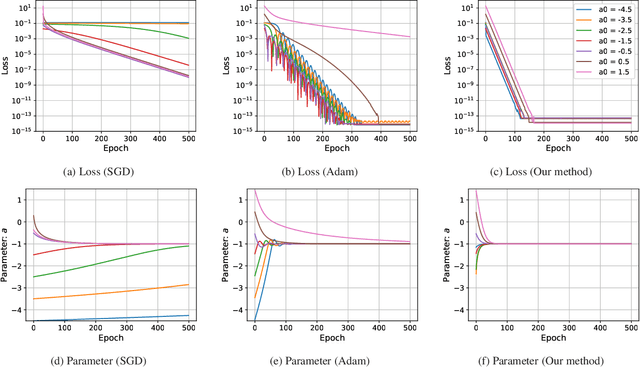
Since the advent of the ``Neural Ordinary Differential Equation (Neural ODE)'' paper, learning ODEs with deep learning has been applied to system identification, time-series forecasting, and related areas. Exploiting the diffeomorphic nature of ODE solution maps, neural ODEs has also enabled their use in generative modeling. Despite the rich potential to incorporate various kinds of physical information, training Neural ODEs remains challenging in practice. This study demonstrates, through the simplest one-dimensional linear model, why training Neural ODEs is difficult. We then propose a new stabilization method and provide an analytical convergence analysis. The insights and techniques presented here serve as a concise tutorial for researchers beginning work on Neural ODEs.
Training Physical Neural Networks for Analog In-Memory Computing
Dec 12, 2024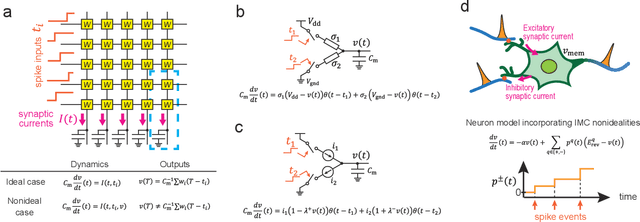
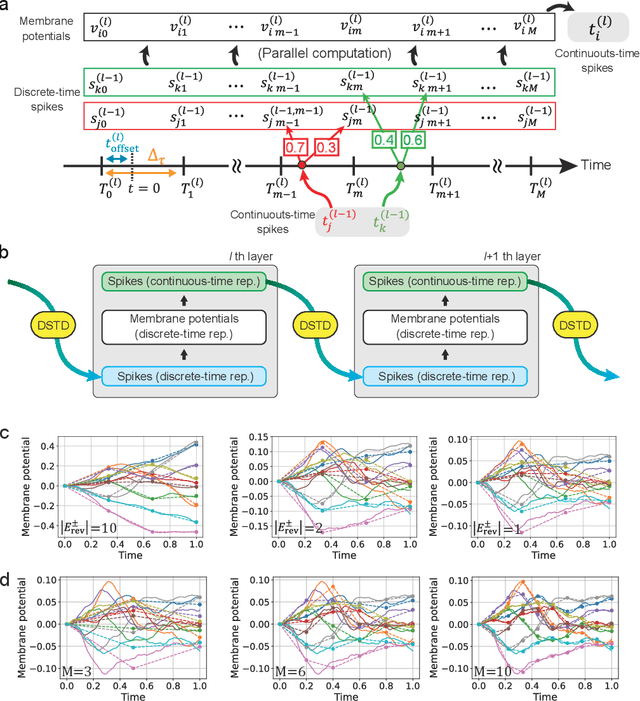
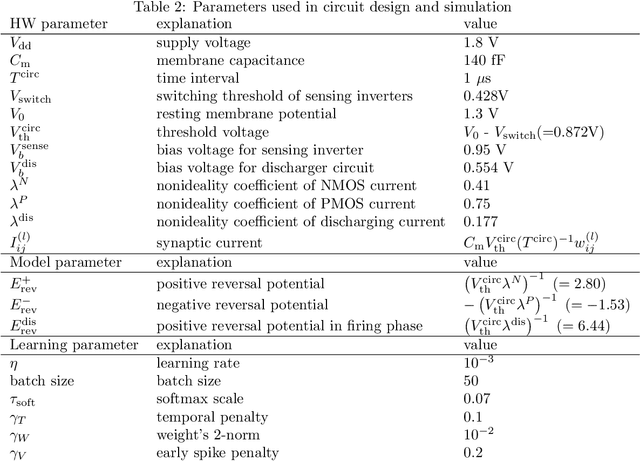
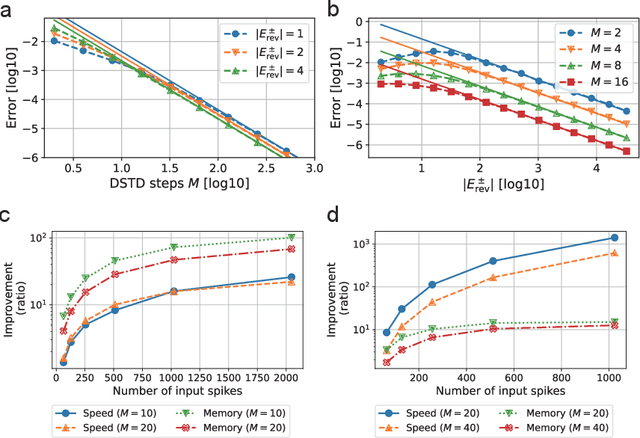
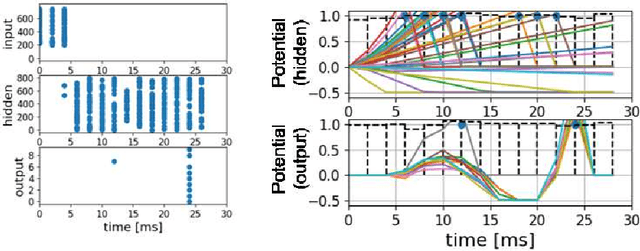
In-memory computing (IMC) architectures mitigate the von Neumann bottleneck encountered in traditional deep learning accelerators. Its energy efficiency can realize deep learning-based edge applications. However, because IMC is implemented using analog circuits, inherent non-idealities in the hardware pose significant challenges. This paper presents physical neural networks (PNNs) for constructing physical models of IMC. PNNs can address the synaptic current's dependence on membrane potential, a challenge in charge-domain IMC systems. The proposed model is mathematically equivalent to spiking neural networks with reversal potentials. With a novel technique called differentiable spike-time discretization, the PNNs are efficiently trained. We show that hardware non-idealities traditionally viewed as detrimental can enhance the model's learning performance. This bottom-up methodology was validated by designing an IMC circuit with non-ideal characteristics using the sky130 process. When employing this bottom-up approach, the modeling error reduced by an order of magnitude compared to conventional top-down methods in post-layout simulations.
Chaos-based reinforcement learning with TD3
May 15, 2024Chaos-based reinforcement learning (CBRL) is a method in which the agent's internal chaotic dynamics drives exploration. This approach offers a model for considering how the biological brain can create variability in its behavior and learn in an exploratory manner. At the same time, it is a learning model that has the ability to automatically switch between exploration and exploitation modes and the potential to realize higher explorations that reflect what it has learned so far. However, the learning algorithms in CBRL have not been well-established in previous studies and have yet to incorporate recent advances in reinforcement learning. This study introduced Twin Delayed Deep Deterministic Policy Gradients (TD3), which is one of the state-of-the-art deep reinforcement learning algorithms that can treat deterministic and continuous action spaces, to CBRL. The validation results provide several insights. First, TD3 works as a learning algorithm for CBRL in a simple goal-reaching task. Second, CBRL agents with TD3 can autonomously suppress their exploratory behavior as learning progresses and resume exploration when the environment changes. Finally, examining the effect of the agent's chaoticity on learning shows that extremely strong chaos negatively impacts the flexible switching between exploration and exploitation.
Sparse-firing regularization methods for spiking neural networks with time-to-first spike coding
Jul 24, 2023The training of multilayer spiking neural networks (SNNs) using the error backpropagation algorithm has made significant progress in recent years. Among the various training schemes, the error backpropagation method that directly uses the firing time of neurons has attracted considerable attention because it can realize ideal temporal coding. This method uses time-to-first spike (TTFS) coding, in which each neuron fires at most once, and this restriction on the number of firings enables information to be processed at a very low firing frequency. This low firing frequency increases the energy efficiency of information processing in SNNs, which is important not only because of its similarity with information processing in the brain, but also from an engineering point of view. However, only an upper limit has been provided for TTFS-coded SNNs, and the information-processing capability of SNNs at lower firing frequencies has not been fully investigated. In this paper, we propose two spike timing-based sparse-firing (SSR) regularization methods to further reduce the firing frequency of TTFS-coded SNNs. The first is the membrane potential-aware SSR (M-SSR) method, which has been derived as an extreme form of the loss function of the membrane potential value. The second is the firing condition-aware SSR (F-SSR) method, which is a regularization function obtained from the firing conditions. Both methods are characterized by the fact that they only require information about the firing timing and associated weights. The effects of these regularization methods were investigated on the MNIST, Fashion-MNIST, and CIFAR-10 datasets using multilayer perceptron networks and convolutional neural network structures.
Learning Reservoir Dynamics with Temporal Self-Modulation
Jan 23, 2023



Reservoir computing (RC) can efficiently process time-series data by transferring the input signal to randomly connected recurrent neural networks (RNNs), which are referred to as a reservoir. The high-dimensional representation of time-series data in the reservoir significantly simplifies subsequent learning tasks. Although this simple architecture allows fast learning and facile physical implementation, the learning performance is inferior to that of other state-of-the-art RNN models. In this paper, to improve the learning ability of RC, we propose self-modulated RC (SM-RC), which extends RC by adding a self-modulation mechanism. The self-modulation mechanism is realized with two gating variables: an input gate and a reservoir gate. The input gate modulates the input signal, and the reservoir gate modulates the dynamical properties of the reservoir. We demonstrated that SM-RC can perform attention tasks where input information is retained or discarded depending on the input signal. We also found that a chaotic state emerged as a result of learning in SM-RC. This indicates that self-modulation mechanisms provide RC with qualitatively different information-processing capabilities. Furthermore, SM-RC outperformed RC in NARMA and Lorentz model tasks. In particular, SM-RC achieved a higher prediction accuracy than RC with a reservoir 10 times larger in the Lorentz model tasks. Because the SM-RC architecture only requires two additional gates, it is physically implementable as RC, providing a new direction for realizing edge AI.
Timing-Based Backpropagation in Spiking Neural Networks Without Single-Spike Restrictions
Nov 29, 2022



We propose a novel backpropagation algorithm for training spiking neural networks (SNNs) that encodes information in the relative multiple spike timing of individual neurons without single-spike restrictions. The proposed algorithm inherits the advantages of conventional timing-based methods in that it computes accurate gradients with respect to spike timing, which promotes ideal temporal coding. Unlike conventional methods where each neuron fires at most once, the proposed algorithm allows each neuron to fire multiple times. This extension naturally improves the computational capacity of SNNs. Our SNN model outperformed comparable SNN models and achieved as high accuracy as non-convolutional artificial neural networks. The spike count property of our networks was altered depending on the time constant of the postsynaptic current and the membrane potential. Moreover, we found that there existed the optimal time constant with the maximum test accuracy. That was not seen in conventional SNNs with single-spike restrictions on time-to-fast-spike (TTFS) coding. This result demonstrates the computational properties of SNNs that biologically encode information into the multi-spike timing of individual neurons. Our code would be publicly available.
Effects of VLSI Circuit Constraints on Temporal-Coding Multilayer Spiking Neural Networks
Jun 25, 2021
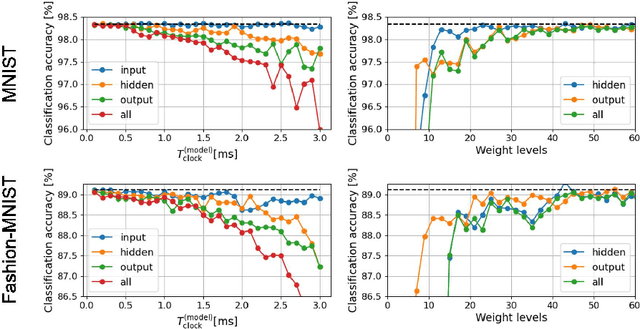
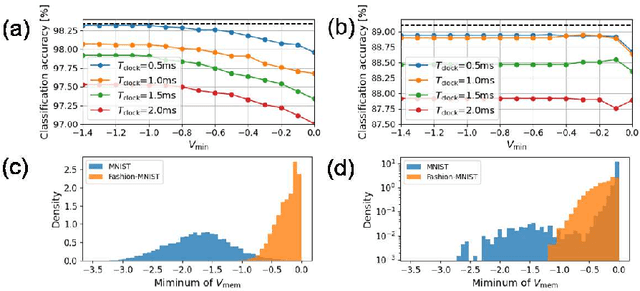
The spiking neural network (SNN) has been attracting considerable attention not only as a mathematical model for the brain, but also as an energy-efficient information processing model for real-world applications. In particular, SNNs based on temporal coding are expected to be much more efficient than those based on rate coding, because the former requires substantially fewer spikes to carry out tasks. As SNNs are continuous-state and continuous-time models, it is favorable to implement them with analog VLSI circuits. However, the construction of the entire system with continuous-time analog circuits would be infeasible when the system size is very large. Therefore, mixed-signal circuits must be employed, and the time discretization and quantization of the synaptic weights are necessary. Moreover, the analog VLSI implementation of SNNs exhibits non-idealities, such as the effects of noise and device mismatches, as well as other constraints arising from the analog circuit operation. In this study, we investigated the effects of the time discretization and/or weight quantization on the performance of SNNs. Furthermore, we elucidated the effects the lower bound of the membrane potentials and the temporal fluctuation of the firing threshold. Finally, we propose an optimal approach for the mapping of mathematical SNN models to analog circuits with discretized time.
Model-Size Reduction for Reservoir Computing by Concatenating Internal States Through Time
Jun 11, 2020
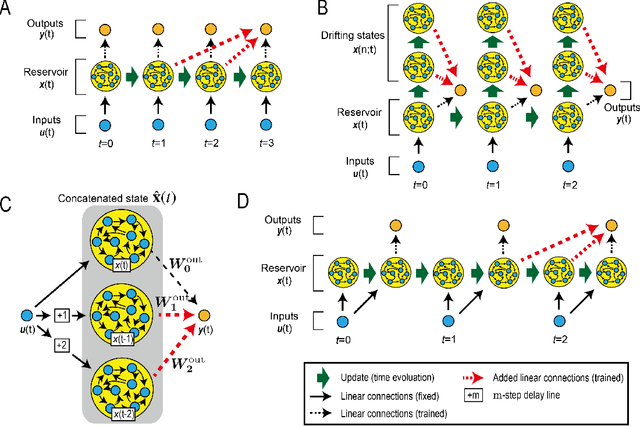
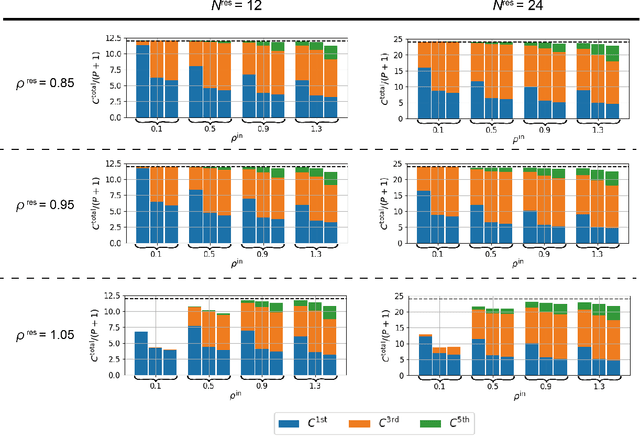
Reservoir computing (RC) is a machine learning algorithm that can learn complex time series from data very rapidly based on the use of high-dimensional dynamical systems, such as random networks of neurons, called "reservoirs." To implement RC in edge computing, it is highly important to reduce the amount of computational resources that RC requires. In this study, we propose methods that reduce the size of the reservoir by inputting the past or drifting states of the reservoir to the output layer at the current time step. These proposed methods are analyzed based on information processing capacity, which is a performance measure of RC proposed by Dambre et al. (2012). In addition, we evaluate the effectiveness of the proposed methods on time-series prediction tasks: the generalized Henon-map and NARMA. On these tasks, we found that the proposed methods were able to reduce the size of the reservoir up to one tenth without a substantial increase in regression error. Because the applications of the proposed methods are not limited to a specific network structure of the reservoir, the proposed methods could further improve the energy efficiency of RC-based systems, such as FPGAs and photonic systems.
A Supervised Learning Algorithm for Multilayer Spiking Neural Networks Based on Temporal Coding Toward Energy-Efficient VLSI Processor Design
Jan 08, 2020
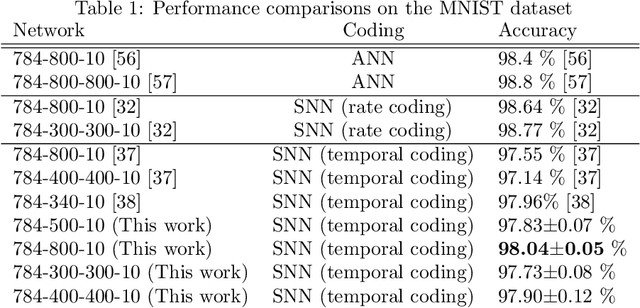

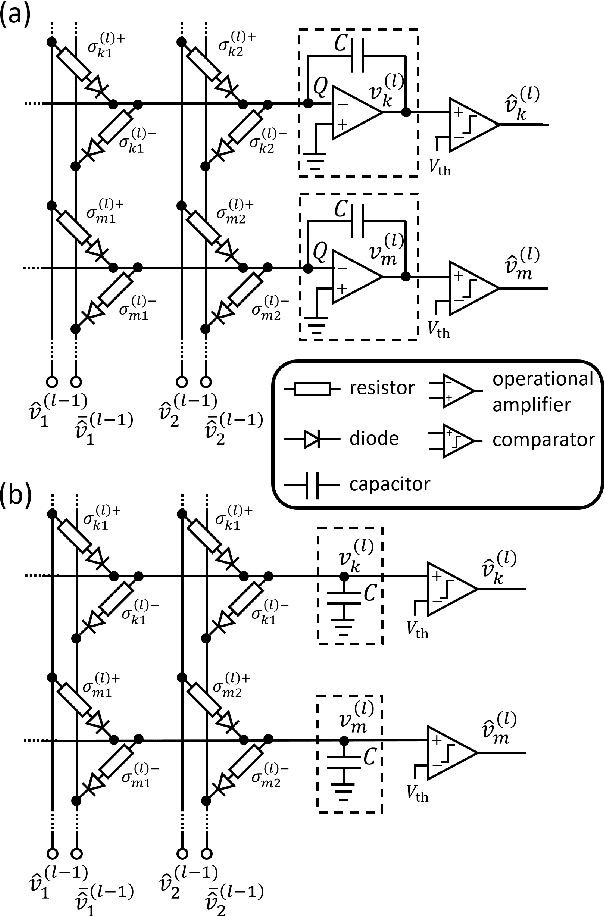
Spiking neural networks (SNNs) are brain-inspired mathematical models with the ability to process information in the form of spikes. SNNs are expected to provide not only new machine-learning algorithms, but also energy-efficient computational models when implemented in VLSI circuits. In this paper, we propose a novel supervised learning algorithm for SNNs based on temporal coding. A spiking neuron in this algorithm is designed to facilitate analog VLSI implementations with analog resistive memory, by which ultra-high energy efficiency can be achieved. We also propose several techniques to improve the performance on a recognition task, and show that the classification accuracy of the proposed algorithm is as high as that of the state-of-the-art temporal coding SNN algorithms on the MNIST dataset. Finally, we discuss the robustness of the proposed SNNs against variations that arise from the device manufacturing process and are unavoidable in analog VLSI implementation. We also propose a technique to suppress the effects of variations in the manufacturing process on the recognition performance.