 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Time-Series Anomaly Detection by Integrating Spectral-Residual Bottom-Up Attention with Reservoir Computing
Oct 16, 2025Reservoir computing (RC) establishes the basis for the processing of time-series data by exploiting the high-dimensional spatiotemporal response of a recurrent neural network to an input signal. In particular, RC trains only the output layer weights. This simplicity has drawn attention especially in Edge Artificial Intelligence (AI) applications. Edge AI enables time-series anomaly detection in real time, which is important because detection delays can lead to serious incidents. However, achieving adequate anomaly-detection performance with RC alone may require an unacceptably large reservoir on resource-constrained edge devices. Without enlarging the reservoir, attention mechanisms can improve accuracy, although they may require substantial computation and undermine the learning efficiency of RC. In this study, to improve the anomaly detection performance of RC without sacrificing learning efficiency, we propose a spectral residual RC (SR-RC) that integrates the spectral residual (SR) method - a learning-free, bottom-up attention mechanism - with RC. We demonstrated that SR-RC outperformed conventional RC and logistic-regression models based on values extracted by the SR method across benchmark tasks and real-world time-series datasets. Moreover, because the SR method, similarly to RC, is well suited for hardware implementation, SR-RC suggests a practical direction for deploying RC as Edge AI for time-series anomaly detection.
Training Physical Neural Networks for Analog In-Memory Computing
Dec 12, 2024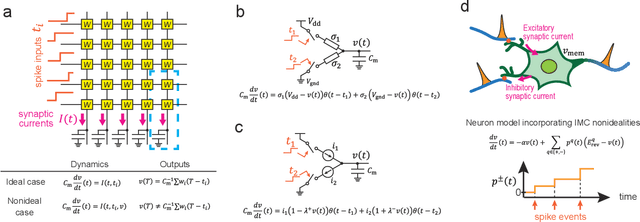
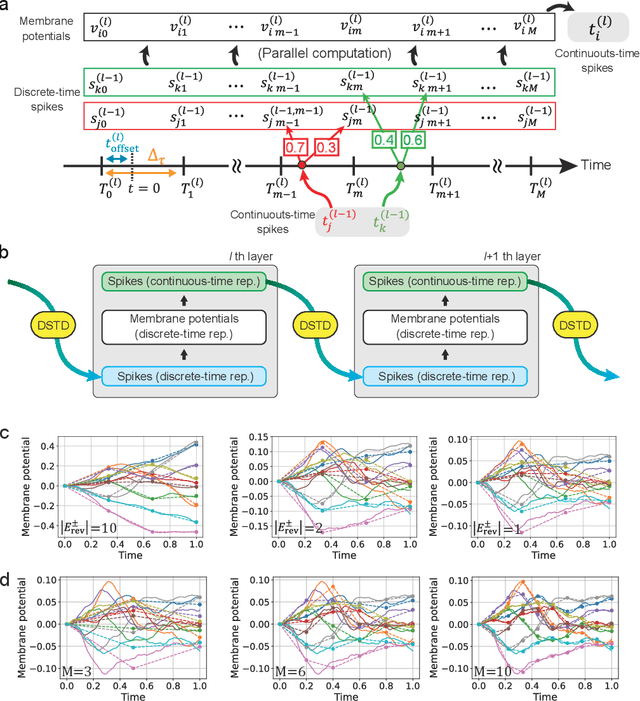
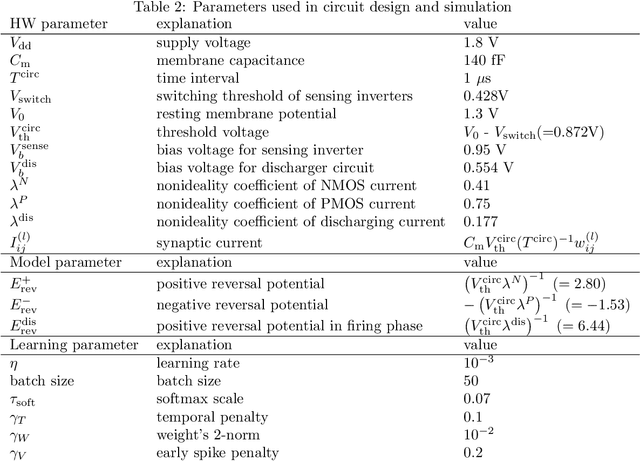
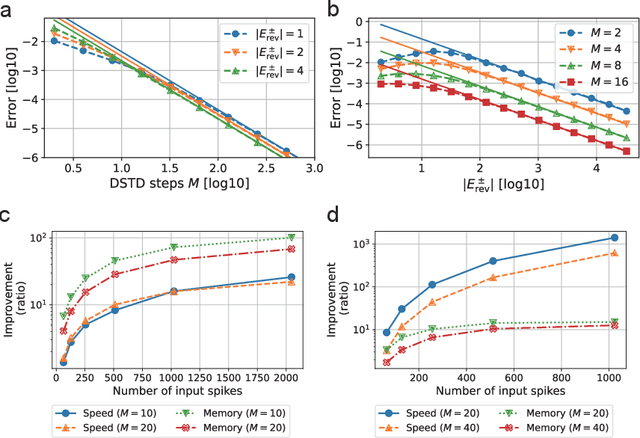
In-memory computing (IMC) architectures mitigate the von Neumann bottleneck encountered in traditional deep learning accelerators. Its energy efficiency can realize deep learning-based edge applications. However, because IMC is implemented using analog circuits, inherent non-idealities in the hardware pose significant challenges. This paper presents physical neural networks (PNNs) for constructing physical models of IMC. PNNs can address the synaptic current's dependence on membrane potential, a challenge in charge-domain IMC systems. The proposed model is mathematically equivalent to spiking neural networks with reversal potentials. With a novel technique called differentiable spike-time discretization, the PNNs are efficiently trained. We show that hardware non-idealities traditionally viewed as detrimental can enhance the model's learning performance. This bottom-up methodology was validated by designing an IMC circuit with non-ideal characteristics using the sky130 process. When employing this bottom-up approach, the modeling error reduced by an order of magnitude compared to conventional top-down methods in post-layout simulations.
Learning Reservoir Dynamics with Temporal Self-Modulation
Jan 23, 2023



Reservoir computing (RC) can efficiently process time-series data by transferring the input signal to randomly connected recurrent neural networks (RNNs), which are referred to as a reservoir. The high-dimensional representation of time-series data in the reservoir significantly simplifies subsequent learning tasks. Although this simple architecture allows fast learning and facile physical implementation, the learning performance is inferior to that of other state-of-the-art RNN models. In this paper, to improve the learning ability of RC, we propose self-modulated RC (SM-RC), which extends RC by adding a self-modulation mechanism. The self-modulation mechanism is realized with two gating variables: an input gate and a reservoir gate. The input gate modulates the input signal, and the reservoir gate modulates the dynamical properties of the reservoir. We demonstrated that SM-RC can perform attention tasks where input information is retained or discarded depending on the input signal. We also found that a chaotic state emerged as a result of learning in SM-RC. This indicates that self-modulation mechanisms provide RC with qualitatively different information-processing capabilities. Furthermore, SM-RC outperformed RC in NARMA and Lorentz model tasks. In particular, SM-RC achieved a higher prediction accuracy than RC with a reservoir 10 times larger in the Lorentz model tasks. Because the SM-RC architecture only requires two additional gates, it is physically implementable as RC, providing a new direction for realizing edge AI.