 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Latent Phase Structures and Branching Logic in Locomotion Policies: A Case Study on HalfCheetah
Mar 18, 2026In locomotion control tasks, Deep Reinforcement Learning (DRL) has demonstrated high performance; however, the decision-making process of the learned policy remains a black box, making it difficult for humans to understand. On the other hand, in periodic motions such as walking, it is well known that implicit motion phases exist, such as the stance phase and the swing phase. Focusing on this point, this study hypothesizes that a policy trained for locomotion control may also represent a phase structure that is interpretable by humans. To examine this hypothesis in a controlled setting, we consider a locomotion task that is amenable to observing whether a policy autonomously acquires temporally structured phases through interaction with the environment. To verify this hypothesis, in the MuJoCo locomotion benchmark HalfCheetah-v5, the state transition sequences acquired by a policy trained for walking control through interaction with the environment were aggregated into semantic phases based on state similarity and consistency of subsequent transitions. As a result, we demonstrated that the state sequences generated by the trained policy exhibit periodic phase transition structures as well as phase branching. Furthermore, by approximating the states and actions corresponding to each semantic phase using Explainable Boosting Machines (EBMs), we analyzed phase-dependent decision making-namely, which state features the policy function attends to and how it controls action outputs in each phase. These results suggest that neural network-based policies, which are often regarded as black boxes, can autonomously acquire interpretable phase structures and logical branching mechanisms.
Accuracy-Preserving CNN Pruning Method under Limited Data Availability
Nov 13, 2025Convolutional Neural Networks (CNNs) are widely used in image recognition and have succeeded in various domains. CNN models have become larger-scale to improve accuracy and generalization performance. Research has been conducted on compressing pre-trained models for specific target applications in environments with limited computing resources. Among model compression techniques, methods using Layer-wise Relevance Propagation (LRP), an explainable AI technique, have shown promise by achieving high pruning rates while preserving accuracy, even without fine-tuning. Because these methods do not require fine-tuning, they are suited to scenarios with limited data. However, existing LRP-based pruning approaches still suffer from significant accuracy degradation, limiting their practical usability. This study proposes a pruning method that achieves a higher pruning rate while preserving better model accuracy. Our approach to pruning with a small amount of data has achieved pruning that preserves accuracy better than existing methods.
Chaos-based reinforcement learning with TD3
May 15, 2024Chaos-based reinforcement learning (CBRL) is a method in which the agent's internal chaotic dynamics drives exploration. This approach offers a model for considering how the biological brain can create variability in its behavior and learn in an exploratory manner. At the same time, it is a learning model that has the ability to automatically switch between exploration and exploitation modes and the potential to realize higher explorations that reflect what it has learned so far. However, the learning algorithms in CBRL have not been well-established in previous studies and have yet to incorporate recent advances in reinforcement learning. This study introduced Twin Delayed Deep Deterministic Policy Gradients (TD3), which is one of the state-of-the-art deep reinforcement learning algorithms that can treat deterministic and continuous action spaces, to CBRL. The validation results provide several insights. First, TD3 works as a learning algorithm for CBRL in a simple goal-reaching task. Second, CBRL agents with TD3 can autonomously suppress their exploratory behavior as learning progresses and resume exploration when the environment changes. Finally, examining the effect of the agent's chaoticity on learning shows that extremely strong chaos negatively impacts the flexible switching between exploration and exploitation.
Learning Reservoir Dynamics with Temporal Self-Modulation
Jan 23, 2023



Reservoir computing (RC) can efficiently process time-series data by transferring the input signal to randomly connected recurrent neural networks (RNNs), which are referred to as a reservoir. The high-dimensional representation of time-series data in the reservoir significantly simplifies subsequent learning tasks. Although this simple architecture allows fast learning and facile physical implementation, the learning performance is inferior to that of other state-of-the-art RNN models. In this paper, to improve the learning ability of RC, we propose self-modulated RC (SM-RC), which extends RC by adding a self-modulation mechanism. The self-modulation mechanism is realized with two gating variables: an input gate and a reservoir gate. The input gate modulates the input signal, and the reservoir gate modulates the dynamical properties of the reservoir. We demonstrated that SM-RC can perform attention tasks where input information is retained or discarded depending on the input signal. We also found that a chaotic state emerged as a result of learning in SM-RC. This indicates that self-modulation mechanisms provide RC with qualitatively different information-processing capabilities. Furthermore, SM-RC outperformed RC in NARMA and Lorentz model tasks. In particular, SM-RC achieved a higher prediction accuracy than RC with a reservoir 10 times larger in the Lorentz model tasks. Because the SM-RC architecture only requires two additional gates, it is physically implementable as RC, providing a new direction for realizing edge AI.
Deep Q-network using reservoir computing with multi-layered readout
Mar 03, 2022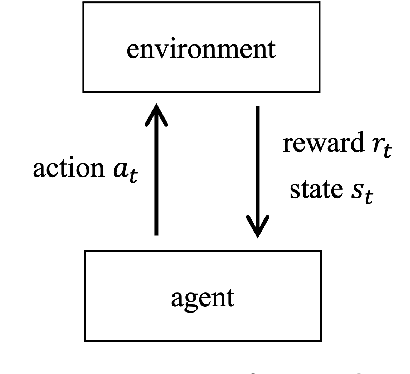
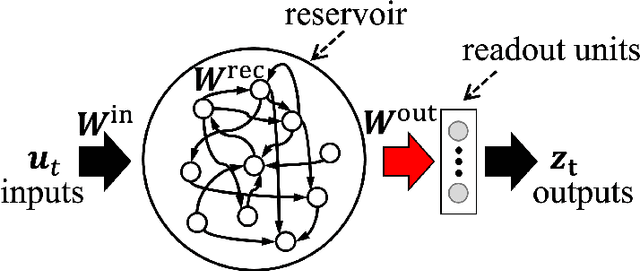
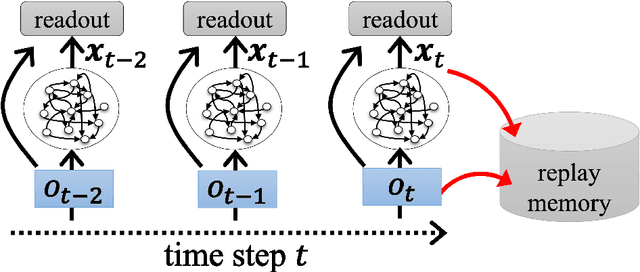
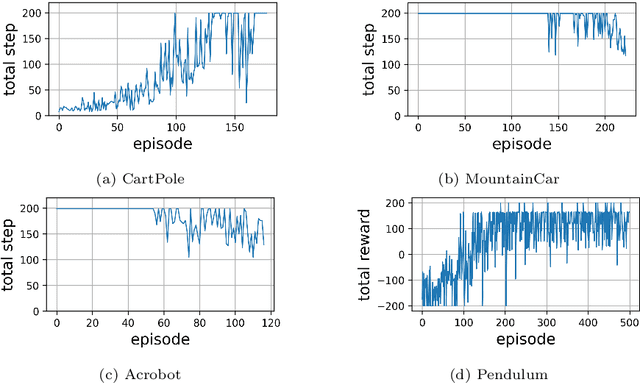
Recurrent neural network (RNN) based reinforcement learning (RL) is used for learning context-dependent tasks and has also attracted attention as a method with remarkable learning performance in recent research. However, RNN-based RL has some issues that the learning procedures tend to be more computationally expensive, and training with backpropagation through time (BPTT) is unstable because of vanishing/exploding gradients problem. An approach with replay memory introducing reservoir computing has been proposed, which trains an agent without BPTT and avoids these issues. The basic idea of this approach is that observations from the environment are input to the reservoir network, and both the observation and the reservoir output are stored in the memory. This paper shows that the performance of this method improves by using a multi-layered neural network for the readout layer, which regularly consists of a single linear layer. The experimental results show that using multi-layered readout improves the learning performance of four classical control tasks that require time-series processing.
Sensitivity -- Local Index to Control Chaoticity or Gradient Globally
Dec 24, 2020
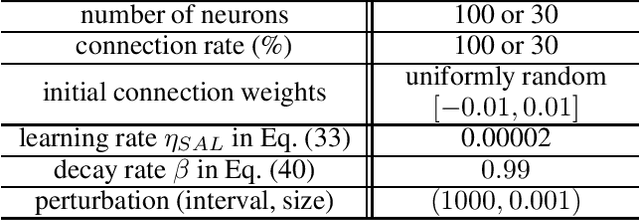
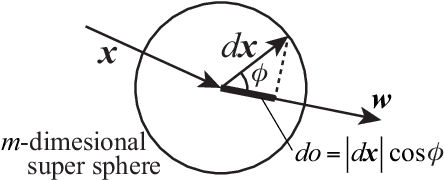
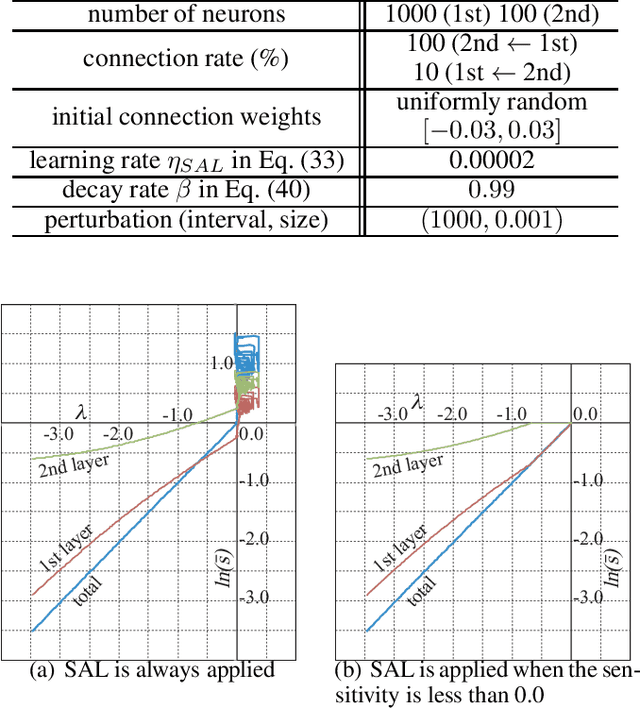
In this paper, we propose a fully local index named "sensitivity" for each neuron to control chaoticity or gradient globally in a neural network (NN), and also propose a learning method to adjust it named "sensitivity adjustment learning (SAL)". The index is the gradient magnitude of its output with respect to its inputs. By adjusting it around 1.0, information transmission in the neuron changes to moderate without shrinking or expanding for both forward and backward computations, and the information transmission through a layer of neurons also moderate when the weights and inputs are random. Therefore, it can be used in a recurrent NN (RNN) to control chaoticity of its global network dynamics, and also can be used to solve the vanishing gradient problem in error back propagation (BP) learning in a deep feedforward NN (DFNN) or an RNN with long-term dependency. We demonstrated that when SAL is applied to an RNN with small random weights, the sum of log-sensitivities is almost equivalent to the maximum Lyapunov exponent until it reaches 0.0 regardless of the network architecture. We also show that SAL works with BP or BPTT to avoid the vanishing gradient problem in a 300-layer DFNN or an RNN solving a problem with 300-step lag between the first input and the output. Compared with the fine manual tuning of the spectral radius of weight matrix before learning, the learning performance was quite better due to the continuous nonlinear learning nature of SAL, which prevented the loss of sensitivity.