 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity -- Local Index to Control Chaoticity or Gradient Globally
Dec 24, 2020
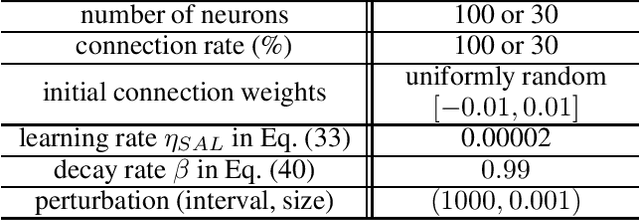
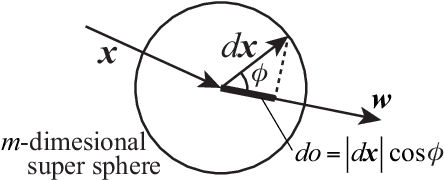
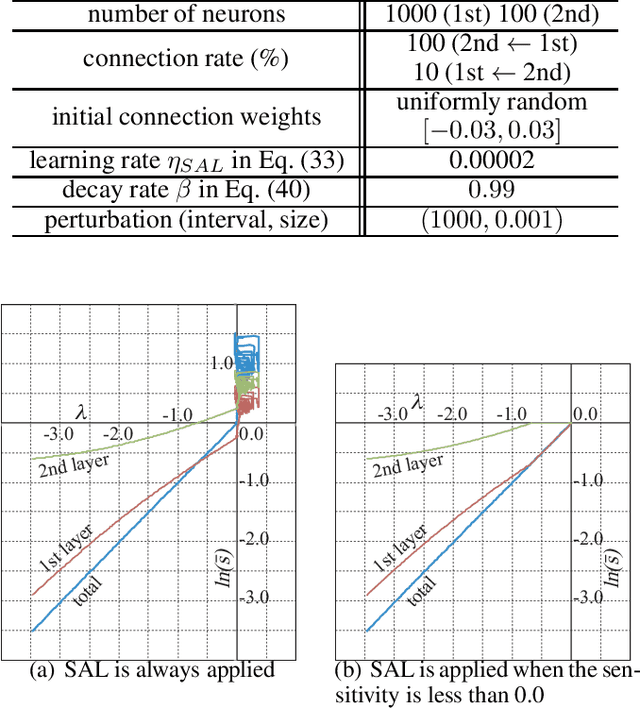
In this paper, we propose a fully local index named "sensitivity" for each neuron to control chaoticity or gradient globally in a neural network (NN), and also propose a learning method to adjust it named "sensitivity adjustment learning (SAL)". The index is the gradient magnitude of its output with respect to its inputs. By adjusting it around 1.0, information transmission in the neuron changes to moderate without shrinking or expanding for both forward and backward computations, and the information transmission through a layer of neurons also moderate when the weights and inputs are random. Therefore, it can be used in a recurrent NN (RNN) to control chaoticity of its global network dynamics, and also can be used to solve the vanishing gradient problem in error back propagation (BP) learning in a deep feedforward NN (DFNN) or an RNN with long-term dependency. We demonstrated that when SAL is applied to an RNN with small random weights, the sum of log-sensitivities is almost equivalent to the maximum Lyapunov exponent until it reaches 0.0 regardless of the network architecture. We also show that SAL works with BP or BPTT to avoid the vanishing gradient problem in a 300-layer DFNN or an RNN solving a problem with 300-step lag between the first input and the output. Compared with the fine manual tuning of the spectral radius of weight matrix before learning, the learning performance was quite better due to the continuous nonlinear learning nature of SAL, which prevented the loss of sensitivity.