 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity -- Local Index to Control Chaoticity or Gradient Globally
Dec 24, 2020
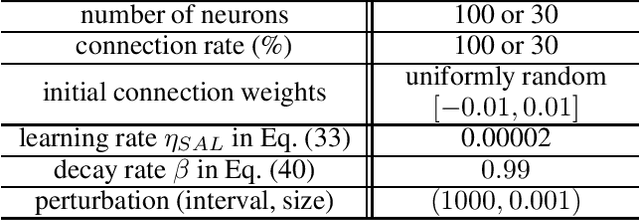
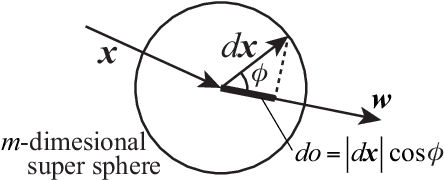
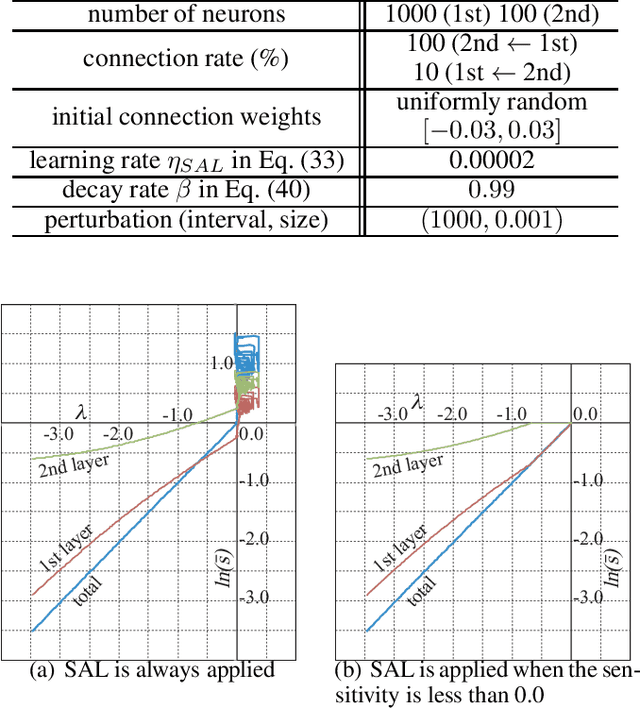
In this paper, we propose a fully local index named "sensitivity" for each neuron to control chaoticity or gradient globally in a neural network (NN), and also propose a learning method to adjust it named "sensitivity adjustment learning (SAL)". The index is the gradient magnitude of its output with respect to its inputs. By adjusting it around 1.0, information transmission in the neuron changes to moderate without shrinking or expanding for both forward and backward computations, and the information transmission through a layer of neurons also moderate when the weights and inputs are random. Therefore, it can be used in a recurrent NN (RNN) to control chaoticity of its global network dynamics, and also can be used to solve the vanishing gradient problem in error back propagation (BP) learning in a deep feedforward NN (DFNN) or an RNN with long-term dependency. We demonstrated that when SAL is applied to an RNN with small random weights, the sum of log-sensitivities is almost equivalent to the maximum Lyapunov exponent until it reaches 0.0 regardless of the network architecture. We also show that SAL works with BP or BPTT to avoid the vanishing gradient problem in a 300-layer DFNN or an RNN solving a problem with 300-step lag between the first input and the output. Compared with the fine manual tuning of the spectral radius of weight matrix before learning, the learning performance was quite better due to the continuous nonlinear learning nature of SAL, which prevented the loss of sensitivity.
Communications that Emerge through Reinforcement Learning Using a (Recurrent) Neural Network
May 16, 2017



Communication is not only an action of choosing a signal, but needs to consider the context and sensor signals. It also needs to decide what information is communicated and how it is represented in or understood from signals. Therefore, communication should be realized comprehensively together with its purpose and other functions. The recent successful results in end-to-end reinforcement learning (RL) show the importance of comprehensive learning and the usefulness of end-to-end RL. Although little is known, we have shown that a variety of communications emerge through RL using a (recurrent) neural network (NN). Here, three of them are introduced. In the 1st one, negotiation to avoid conflicts among 4 randomly-picked agents was learned. Each agent generates a binary signal from the output of its recurrent NN (RNN), and receives 4 signals from the agents three times. After learning, each agent made an appropriate final decision after negotiation for any combination of 4 agents. Differentiation of individuality among the agents also could be seen. The 2nd one focused on discretization of communication signal. A sender agent perceives the receiver's location and generates a continuous signal twice by its RNN. A receiver agent receives them sequentially, and moves according to its RNN's output to reach the sender's location. When noises were added to the signal, it was binarized through learning and 2-bit communication was established. The 3rd one focused on end-to-end comprehensive communication. A sender receives 1,785-pixel real camera image on which a real robot can be seen, and sends two sounds whose frequencies are computed by its NN. A receiver receives them, and two motion commands for the robot are generated by its NN. After learning, though some preliminary learning was necessary for the sender, the robot could reach the goal from any initial location.
Functions that Emerge through End-to-End Reinforcement Learning - The Direction for Artificial General Intelligence -
May 16, 2017



Recently, triggered by the impressive results in TV-games or game of Go by Google DeepMind, end-to-end reinforcement learning (RL) is collecting attentions. Although little is known, the author's group has propounded this framework for around 20 years and already has shown various functions that emerge in a neural network (NN) through RL. In this paper, they are introduced again at this timing. "Function Modularization" approach is deeply penetrated subconsciously. The inputs and outputs for a learning system can be raw sensor signals and motor commands. "State space" or "action space" generally used in RL show the existence of functional modules. That has limited reinforcement learning to learning only for the action-planning module. In order to extend reinforcement learning to learning of the entire function on a huge degree of freedom of a massively parallel learning system and to explain or develop human-like intelligence, the author has believed that end-to-end RL from sensors to motors using a recurrent NN (RNN) becomes an essential key. Especially in the higher functions, this approach is very effective by being free from the need to decide their inputs and outputs. The functions that emerge, we have confirmed, through RL using a NN cover a broad range from real robot learning with raw camera pixel inputs to acquisition of dynamic functions in a RNN. Those are (1)image recognition, (2)color constancy (optical illusion), (3)sensor motion (active recognition), (4)hand-eye coordination and hand reaching movement, (5)explanation of brain activities, (6)communication, (7)knowledge transfer, (8)memory, (9)selective attention, (10)prediction, (11)exploration. The end-to-end RL enables the emergence of very flexible comprehensive functions that consider many things in parallel although it is difficult to give the boundary of each function clearly.
New Reinforcement Learning Using a Chaotic Neural Network for Emergence of "Thinking" - "Exploration" Grows into "Thinking" through Learning -
May 16, 2017



Expectation for the emergence of higher functions is getting larger in the framework of end-to-end reinforcement learning using a recurrent neural network. However, the emergence of "thinking" that is a typical higher function is difficult to realize because "thinking" needs non fixed-point, flow-type attractors with both convergence and transition dynamics. Furthermore, in order to introduce "inspiration" or "discovery" in "thinking", not completely random but unexpected transition should be also required. By analogy to "chaotic itinerancy", we have hypothesized that "exploration" grows into "thinking" through learning by forming flow-type attractors on chaotic random-like dynamics. It is expected that if rational dynamics are learned in a chaotic neural network (ChNN), coexistence of rational state transition, inspiration-like state transition and also random-like exploration for unknown situation can be realized. Based on the above idea, we have proposed new reinforcement learning using a ChNN as an actor. The positioning of exploration is completely different from the conventional one. The chaotic dynamics inside the ChNN produces exploration factors by itself. Since external random numbers for stochastic action selection are not used, exploration factors cannot be isolated from the output. Therefore, the learning method is also completely different from the conventional one. At each non-feedback connection, one variable named causality trace takes in and maintains the input through the connection according to the change in its output. Using the trace and TD error, the weight is updated. In this paper, as the result of a recent simple task to see whether the new learning works or not, it is shown that a robot with two wheels and two visual sensors reaches a target while avoiding an obstacle after learning though there are still many rooms for improvement.