 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAWEMixer: Adaptive Wavelet-Enhanced Mixer Network for Long-Term Time Series Forecasting
Nov 06, 2025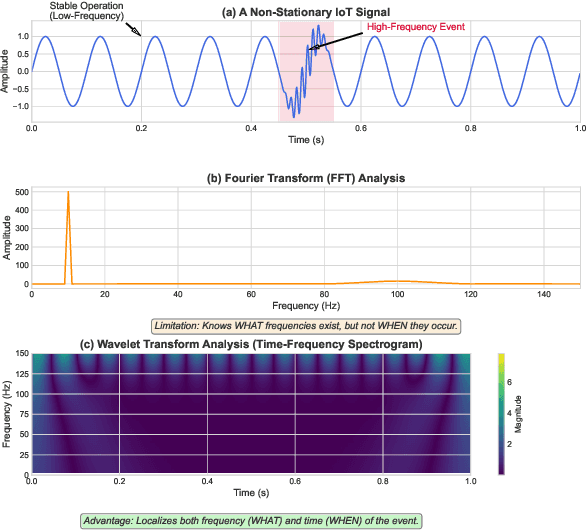
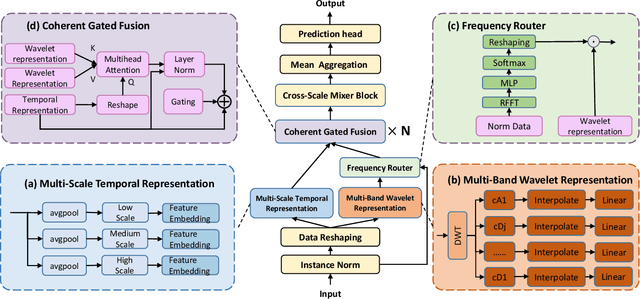
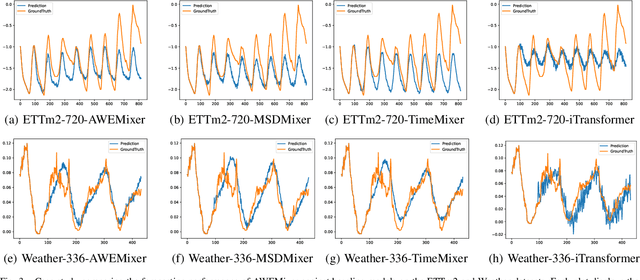
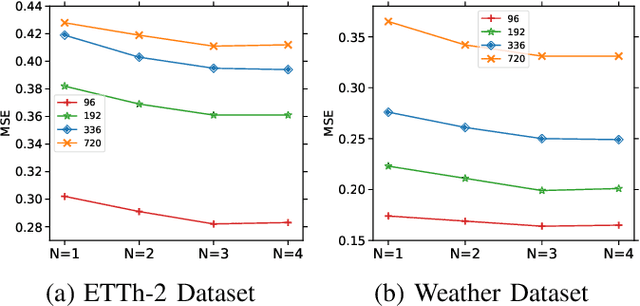
Forecasting long-term time series in IoT environments remains a significant challenge due to the non-stationary and multi-scale characteristics of sensor signals. Furthermore, error accumulation causes a decrease in forecast quality when predicting further into the future. Traditional methods are restricted to operate in time-domain, while the global frequency information achieved by Fourier transform would be regarded as stationary signals leading to blur the temporal patterns of transient events. We propose AWEMixer, an Adaptive Wavelet-Enhanced Mixer Network including two innovative components: 1) a Frequency Router designs to utilize the global periodicity pattern achieved by Fast Fourier Transform to adaptively weight localized wavelet subband, and 2) a Coherent Gated Fusion Block to achieve selective integration of prominent frequency features with multi-scale temporal representation through cross-attention and gating mechanism, which realizes accurate time-frequency localization while remaining robust to noise. Seven public benchmarks validate that our model is more effective than recent state-of-the-art models. Specifically, our model consistently achieves performance improvement compared with transformer-based and MLP-based state-of-the-art models in long-sequence time series forecasting. Code is available at https://github.com/hit636/AWEMixer
Delayformer: spatiotemporal transformation for predicting high-dimensional dynamics
Jun 13, 2025Predicting time-series is of great importance in various scientific and engineering fields. However, in the context of limited and noisy data, accurately predicting dynamics of all variables in a high-dimensional system is a challenging task due to their nonlinearity and also complex interactions. Current methods including deep learning approaches often perform poorly for real-world systems under such circumstances. This study introduces the Delayformer framework for simultaneously predicting dynamics of all variables, by developing a novel multivariate spatiotemporal information (mvSTI) transformation that makes each observed variable into a delay-embedded state (vector) and further cross-learns those states from different variables. From dynamical systems viewpoint, Delayformer predicts system states rather than individual variables, thus theoretically and computationally overcoming such nonlinearity and cross-interaction problems. Specifically, it first utilizes a single shared Visual Transformer (ViT) encoder to cross-represent dynamical states from observed variables in a delay embedded form and then employs distinct linear decoders for predicting next states, i.e. equivalently predicting all original variables parallelly. By leveraging the theoretical foundations of delay embedding theory and the representational capabilities of Transformers, Delayformer outperforms current state-of-the-art methods in forecasting tasks on both synthetic and real-world datasets. Furthermore, the potential of Delayformer as a foundational time-series model is demonstrated through cross-domain forecasting tasks, highlighting its broad applicability across various scenarios.
Brain-inspired Chaotic Graph Backpropagation for Large-scale Combinatorial Optimization
Dec 13, 2024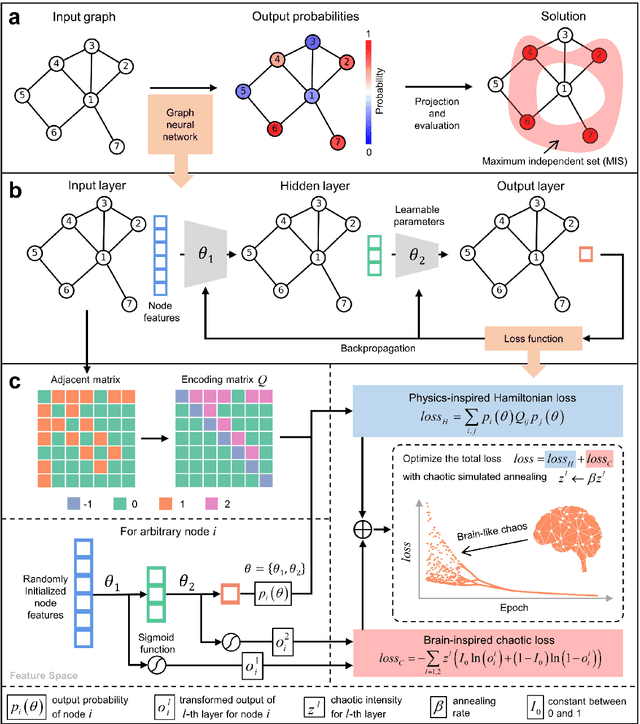
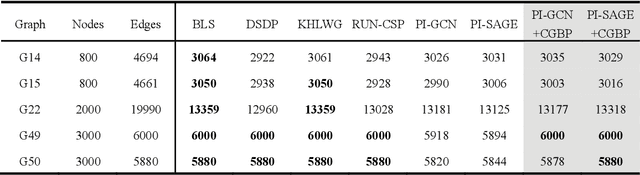
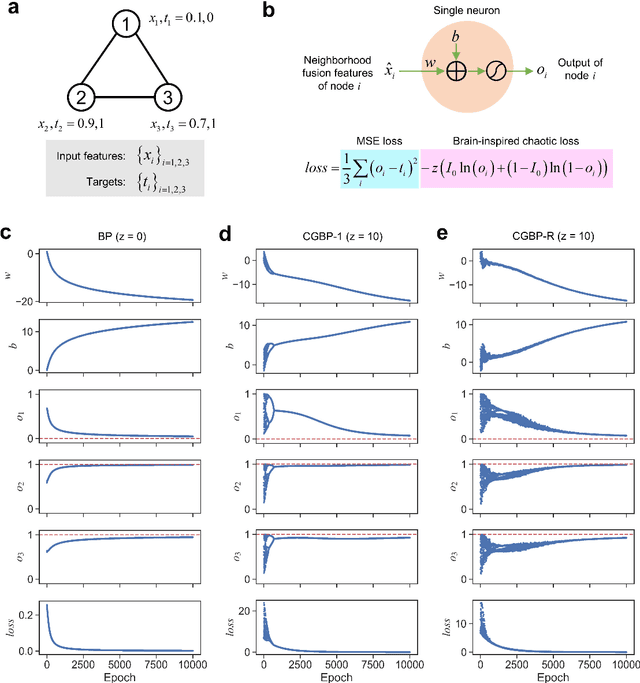
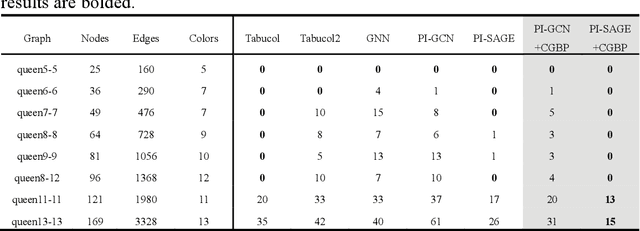
Graph neural networks (GNNs) with unsupervised learning can solve large-scale combinatorial optimization problems (COPs) with efficient time complexity, making them versatile for various applications. However, since this method maps the combinatorial optimization problem to the training process of a graph neural network, and the current mainstream backpropagation-based training algorithms are prone to fall into local minima, the optimization performance is still inferior to the current state-of-the-art (SOTA) COP methods. To address this issue, inspired by possibly chaotic dynamics of real brain learning, we introduce a chaotic training algorithm, i.e. chaotic graph backpropagation (CGBP), which introduces a local loss function in GNN that makes the training process not only chaotic but also highly efficient. Different from existing methods, we show that the global ergodicity and pseudo-randomness of such chaotic dynamics enable CGBP to learn each optimal GNN effectively and globally, thus solving the COP efficiently. We have applied CGBP to solve various COPs, such as the maximum independent set, maximum cut, and graph coloring. Results on several large-scale benchmark datasets showcase that CGBP can outperform not only existing GNN algorithms but also SOTA methods. In addition to solving large-scale COPs, CGBP as a universal learning algorithm for GNNs, i.e. as a plug-in unit, can be easily integrated into any existing method for improving the performance.
Time Series Prediction by Multi-task GPR with Spatiotemporal Information Transformation
Apr 26, 2022
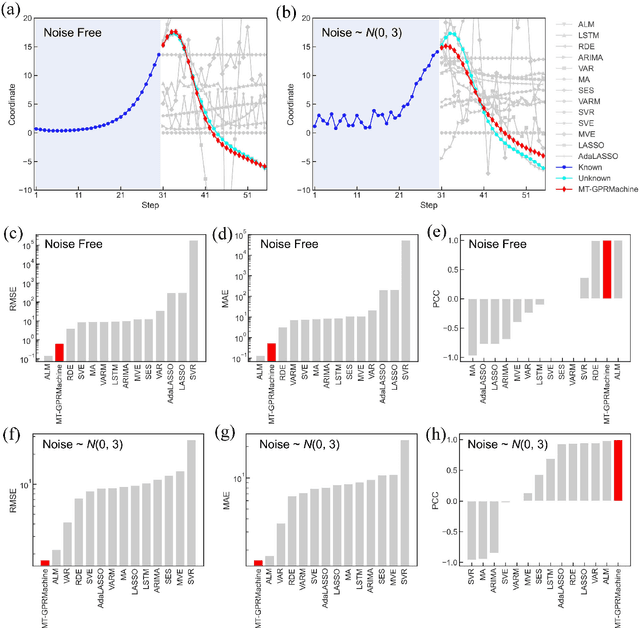
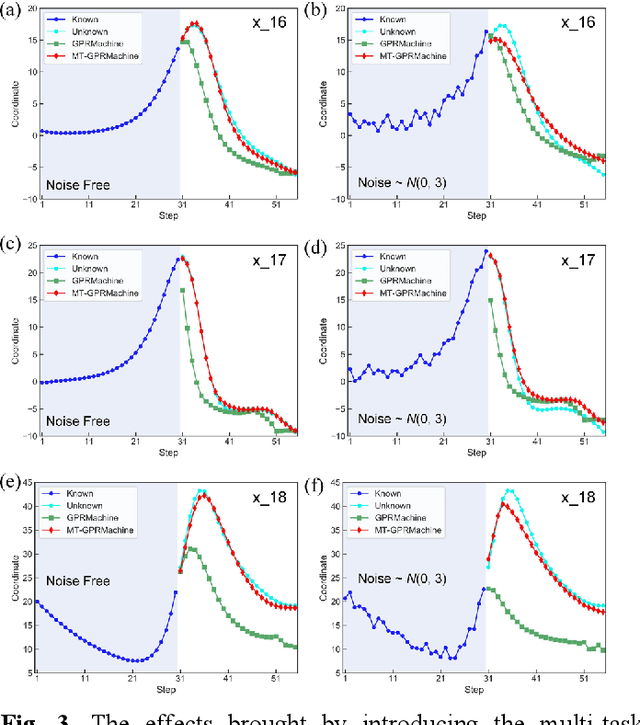
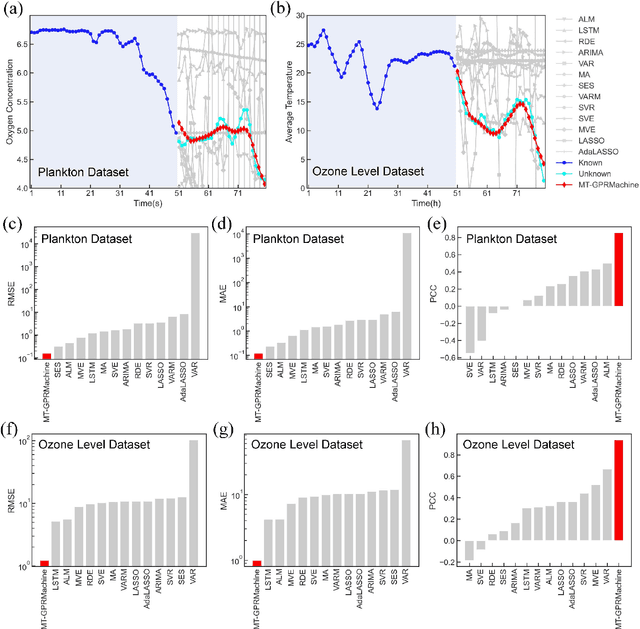
Making an accurate prediction of an unknown system only from a short-term time series is difficult due to the lack of sufficient information, especially in a multi-step-ahead manner. However, a high-dimensional short-term time series contains rich dynamical information, and also becomes increasingly available in many fields. In this work, by exploiting spatiotemporal information (STI) transformation scheme that transforms such high-dimensional/spatial information to temporal information, we developed a new method called MT-GPRMachine to achieve accurate prediction from a short-term time series. Specifically, we first construct a specific multi-task GPR which is multiple linked STI mappings to transform high dimensional/spatial information into temporal/dynamical information of any given target variable, and then makes multi step-ahead prediction of the target variable by solving those STI mappings. The multi-step-ahead prediction results on various synthetic and real-world datasets clearly validated that MT-GPRMachine outperformed other existing approaches.
Accurate ADMET Prediction with XGBoost
Apr 15, 2022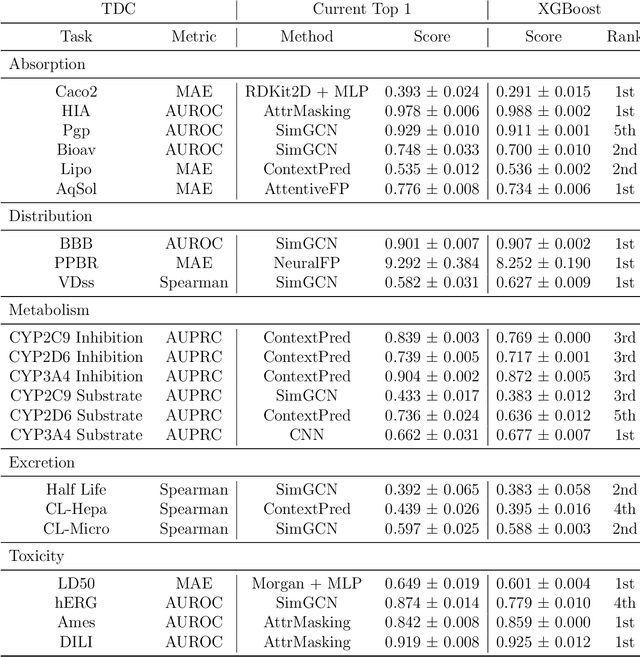
The absorption, distribution, metabolism, excretion, and toxicity (ADMET) properties are important in drug discovery as they define efficacy and safety. Here, we apply an ensemble of features, including fingerprints and descriptors, and a tree-based machine learning model, extreme gradient boosting, for accurate ADMET prediction. Our model performs well in the Therapeutics Data Commons ADMET benchmark group. For 22 tasks, our model is ranked first in 10 tasks and top 3 in 18 tasks.
Residual-Recursion Autoencoder for Shape Illustration Images
Feb 06, 2020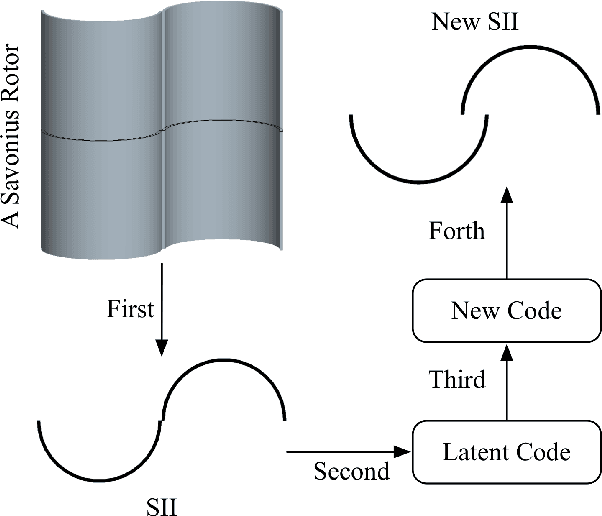
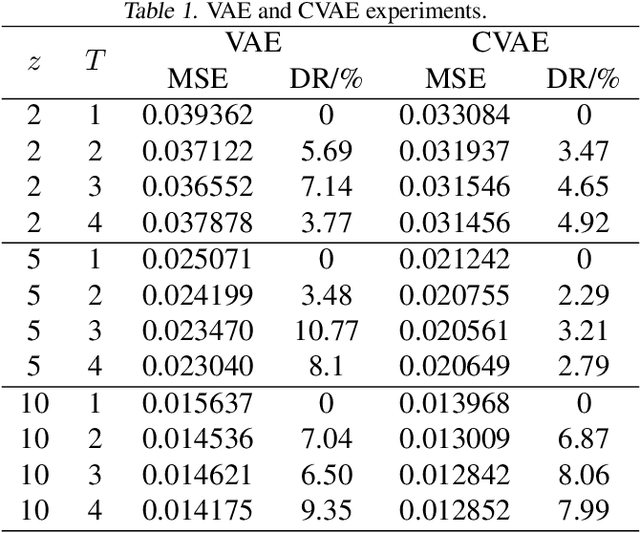
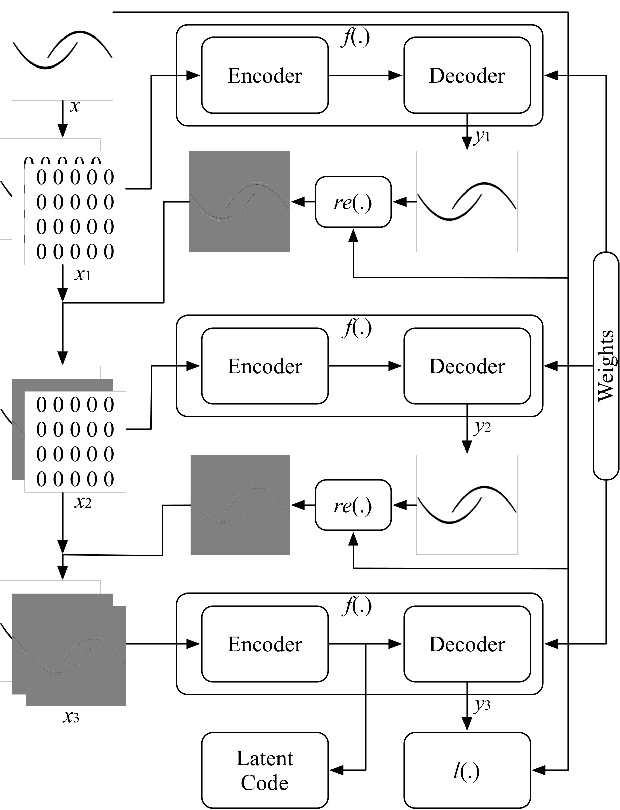
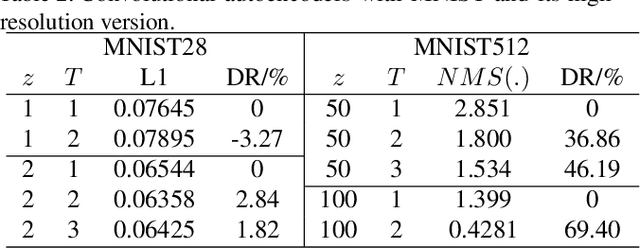
Shape illustration images (SIIs) are common and important in describing the cross-sections of industrial products. Same as MNIST, the handwritten digit images, SIIs are gray or binary and containing shapes that are surrounded by large areas of blanks. In this work, Residual-Recursion Autoencoder (RRAE) has been proposed to extract low-dimensional features from SIIs while maintaining reconstruction accuracy as high as possible. RRAE will try to reconstruct the original image several times and recursively fill the latest residual image to the reserved channel of the encoder's input before the next trial of reconstruction. As a kind of neural network training framework, RRAE can wrap over other autoencoders and increase their performance. From experiment results, the reconstruction loss is decreased by 86.47% for convolutional autoencoder with high-resolution SIIs, 10.77% for variational autoencoder and 8.06% for conditional variational autoencoder with MNIST.