 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple-Phase Sequential Fusion Network for Hepatobiliary Phase Liver MRI Synthesis
Apr 24, 2026Gadoxetate disodium-enhanced MRI is essential for the detection and characterization of hepatocellular carcinoma. However, acquisition of the hepatobiliary phase (HBP) requires a prolonged post-contrast delay, which reduces workflow efficiency and increases the risk of motion artifacts. In this study, we propose a Triple-Phase Sequential Fusion Network (TriPF-Net) to synthesize HBP images by leveraging the sequential information from pre-HBP sequences: while T1-weighted imaging serves as the indispensable baseline, the model adaptively integrates arterial-phase (AP) and venous-phase (VP) features when available. By modeling the tissue-specific contrast uptake and excretion dynamics across these three phases, TriPF-Net ensures robust HBP synthesis even under the stochastic absence of one or both dynamic contrast-enhanced sequences. The framework comprises an Enhanced Region-Guided Encoder and a Dynamic Feature Unification Module, optimized with a Region-Guided Sequential Fusion Loss to maintain physiological consistency. In addition, clinical variables, including age, sex, total bilirubin, and albumin, are incorporated to enhance physiological consistency. Compared with conventional methods, TriPF-Net achieved superior performance on datasets from two centers. On the internal dataset, the model achieved an MAE of 10.65, a PSNR of 23.27, and an SSIM of 0.76. On the external validation dataset, the corresponding values were 12.41, 23.11, and 0.78, respectively. This flexible solution enhances clinical workflow and lesion depiction, potentially eliminating the need for delayed HBP acquisition in HCC imaging.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Jan 09, 2026We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary language models: their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window. PaCoRe departs from the traditional sequential paradigm by driving TTC through massive parallel exploration coordinated via a message-passing architecture in multiple rounds. Each round launches many parallel reasoning trajectories, compacts their findings into context-bounded messages, and synthesizes these messages to guide the next round and ultimately produce the final answer. Trained end-to-end with large-scale, outcome-based reinforcement learning, the model masters the synthesis abilities required by PaCoRe and scales to multi-million-token effective TTC without exceeding context limits. The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5's 93.2% by scaling effective TTC to roughly two million tokens. We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work.
ZTree: A Subgroup Identification Based Decision Tree Learning Framework
Sep 16, 2025Decision trees are a commonly used class of machine learning models valued for their interpretability and versatility, capable of both classification and regression. We propose ZTree, a novel decision tree learning framework that replaces CART's traditional purity based splitting with statistically principled subgroup identification. At each node, ZTree applies hypothesis testing (e.g., z-tests, t-tests, Mann-Whitney U, log-rank) to assess whether a candidate subgroup differs meaningfully from the complement. To adjust for the complication of multiple testing, we employ a cross-validation-based approach to determine if further node splitting is needed. This robust stopping criterion eliminates the need for post-pruning and makes the test threshold (z-threshold) the only parameter for controlling tree complexity. Because of the simplicity of the tree growing procedure, once a detailed tree is learned using the most lenient z-threshold, all simpler trees can be derived by simply removing nodes that do not meet the larger z-thresholds. This makes parameter tuning intuitive and efficient. Furthermore, this z-threshold is essentially a p-value, allowing users to easily plug in appropriate statistical tests into our framework without adjusting the range of parameter search. Empirical evaluation on five large-scale UCI datasets demonstrates that ZTree consistently delivers strong performance, especially at low data regimes. Compared to CART, ZTree also tends to grow simpler trees without sacrificing performance. ZTree introduces a statistically grounded alternative to traditional decision tree splitting by leveraging hypothesis testing and a cross-validation approach to multiple testing correction, resulting in an efficient and flexible framework.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
HAMF: A Hybrid Attention-Mamba Framework for Joint Scene Context Understanding and Future Motion Representation Learning
May 21, 2025



Motion forecasting represents a critical challenge in autonomous driving systems, requiring accurate prediction of surrounding agents' future trajectories. While existing approaches predict future motion states with the extracted scene context feature from historical agent trajectories and road layouts, they suffer from the information degradation during the scene feature encoding. To address the limitation, we propose HAMF, a novel motion forecasting framework that learns future motion representations with the scene context encoding jointly, to coherently combine the scene understanding and future motion state prediction. We first embed the observed agent states and map information into 1D token sequences, together with the target multi-modal future motion features as a set of learnable tokens. Then we design a unified Attention-based encoder, which synergistically combines self-attention and cross-attention mechanisms to model the scene context information and aggregate future motion features jointly. Complementing the encoder, we implement the Mamba module in the decoding stage to further preserve the consistency and correlations among the learned future motion representations, to generate the accurate and diverse final trajectories. Extensive experiments on Argoverse 2 benchmark demonstrate that our hybrid Attention-Mamba model achieves state-of-the-art motion forecasting performance with the simple and lightweight architecture.
Stop Summation: Min-Form Credit Assignment Is All Process Reward Model Needs for Reasoning
Apr 21, 2025



Process reward models (PRMs) have proven effective for test-time scaling of Large Language Models (LLMs) on challenging reasoning tasks. However, reward hacking issues with PRMs limit their successful application in reinforcement fine-tuning. In this paper, we identify the main cause of PRM-induced reward hacking: the canonical summation-form credit assignment in reinforcement learning (RL), which defines the value as cumulative gamma-decayed future rewards, easily induces LLMs to hack steps with high rewards. To address this, we propose PURE: Process sUpervised Reinforcement lEarning. The key innovation of PURE is a min-form credit assignment that formulates the value function as the minimum of future rewards. This method significantly alleviates reward hacking by limiting the value function range and distributing advantages more reasonably. Through extensive experiments on 3 base models, we show that PRM-based approaches enabling min-form credit assignment achieve comparable reasoning performance to verifiable reward-based methods within only 30% steps. In contrast, the canonical sum-form credit assignment collapses training even at the beginning! Additionally, when we supplement PRM-based fine-tuning with just 10% verifiable rewards, we further alleviate reward hacking and produce the best fine-tuned model based on Qwen2.5-Math-7B in our experiments, achieving 82.5% accuracy on AMC23 and 53.3% average accuracy across 5 benchmarks. Moreover, we summarize the observed reward hacking cases and analyze the causes of training collapse. Code and models are available at https://github.com/CJReinforce/PURE.
ElimPCL: Eliminating Noise Accumulation with Progressive Curriculum Labeling for Source-Free Domain Adaptation
Mar 31, 2025Source-Free Domain Adaptation (SFDA) aims to train a target model without source data, and the key is to generate pseudo-labels using a pre-trained source model. However, we observe that the source model often produces highly uncertain pseudo-labels for hard samples, particularly those heavily affected by domain shifts, leading to these noisy pseudo-labels being introduced even before adaptation and further reinforced through parameter updates. Additionally, they continuously influence neighbor samples through propagation in the feature space.To eliminate the issue of noise accumulation, we propose a novel Progressive Curriculum Labeling (ElimPCL) method, which iteratively filters trustworthy pseudo-labeled samples based on prototype consistency to exclude high-noise samples from training. Furthermore, a Dual MixUP technique is designed in the feature space to enhance the separability of hard samples, thereby mitigating the interference of noisy samples on their neighbors.Extensive experiments validate the effectiveness of ElimPCL, achieving up to a 3.4% improvement on challenging tasks compared to state-of-the-art methods.
Offline Reinforcement Learning with Discrete Diffusion Skills
Mar 26, 2025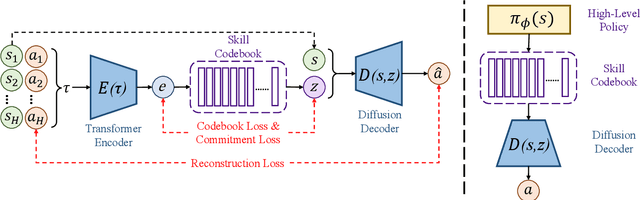
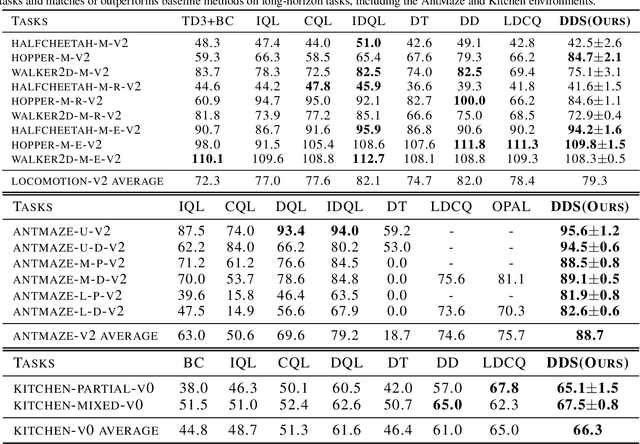
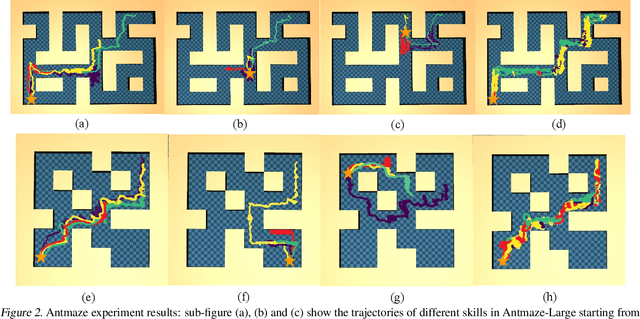
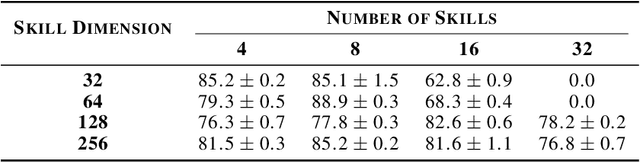
Skills have been introduced to offline reinforcement learning (RL) as temporal abstractions to tackle complex, long-horizon tasks, promoting consistent behavior and enabling meaningful exploration. While skills in offline RL are predominantly modeled within a continuous latent space, the potential of discrete skill spaces remains largely underexplored. In this paper, we propose a compact discrete skill space for offline RL tasks supported by state-of-the-art transformer-based encoder and diffusion-based decoder. Coupled with a high-level policy trained via offline RL techniques, our method establishes a hierarchical RL framework where the trained diffusion decoder plays a pivotal role. Empirical evaluations show that the proposed algorithm, Discrete Diffusion Skill (DDS), is a powerful offline RL method. DDS performs competitively on Locomotion and Kitchen tasks and excels on long-horizon tasks, achieving at least a 12 percent improvement on AntMaze-v2 benchmarks compared to existing offline RL approaches. Furthermore, DDS offers improved interpretability, training stability, and online exploration compared to previous skill-based methods.