 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Reinforcement Learning with Discrete Diffusion Skills
Paper and Code
Mar 26, 2025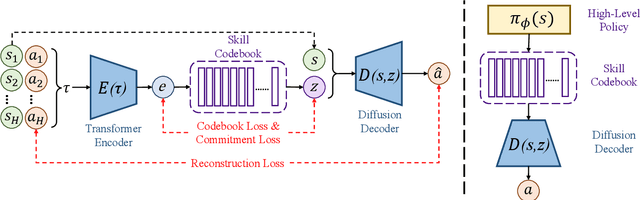
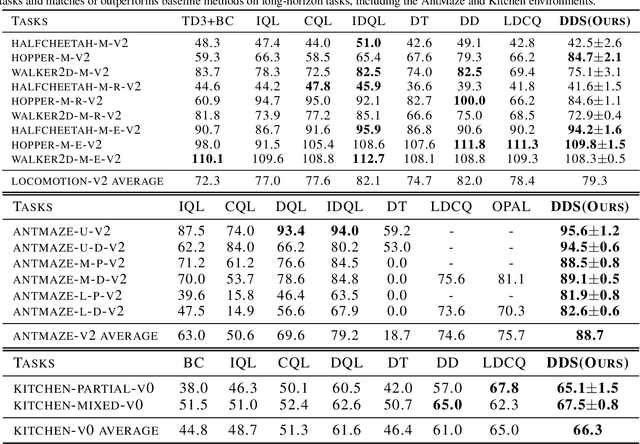
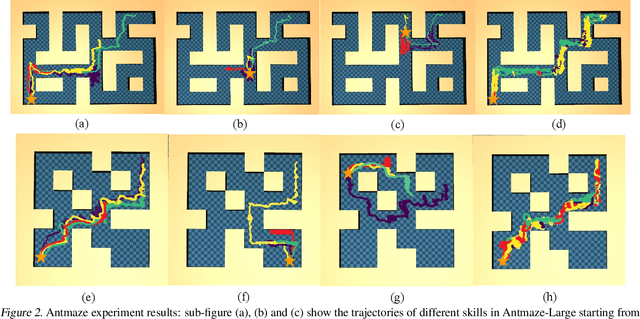
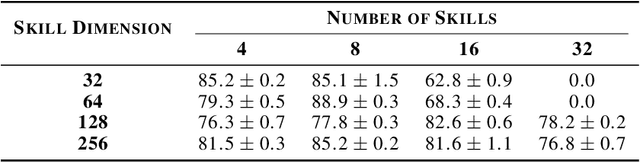
Skills have been introduced to offline reinforcement learning (RL) as temporal abstractions to tackle complex, long-horizon tasks, promoting consistent behavior and enabling meaningful exploration. While skills in offline RL are predominantly modeled within a continuous latent space, the potential of discrete skill spaces remains largely underexplored. In this paper, we propose a compact discrete skill space for offline RL tasks supported by state-of-the-art transformer-based encoder and diffusion-based decoder. Coupled with a high-level policy trained via offline RL techniques, our method establishes a hierarchical RL framework where the trained diffusion decoder plays a pivotal role. Empirical evaluations show that the proposed algorithm, Discrete Diffusion Skill (DDS), is a powerful offline RL method. DDS performs competitively on Locomotion and Kitchen tasks and excels on long-horizon tasks, achieving at least a 12 percent improvement on AntMaze-v2 benchmarks compared to existing offline RL approaches. Furthermore, DDS offers improved interpretability, training stability, and online exploration compared to previous skill-based methods.