 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogRail: Benchmarking VLMs in Cognitive Intrusion Perception for Intelligent Railway Transportation Systems
Jan 14, 2026Accurate and early perception of potential intrusion targets is essential for ensuring the safety of railway transportation systems. However, most existing systems focus narrowly on object classification within fixed visual scopes and apply rule-based heuristics to determine intrusion status, often overlooking targets that pose latent intrusion risks. Anticipating such risks requires the cognition of spatial context and temporal dynamics for the object of interest (OOI), which presents challenges for conventional visual models. To facilitate deep intrusion perception, we introduce a novel benchmark, CogRail, which integrates curated open-source datasets with cognitively driven question-answer annotations to support spatio-temporal reasoning and prediction. Building upon this benchmark, we conduct a systematic evaluation of state-of-the-art visual-language models (VLMs) using multimodal prompts to identify their strengths and limitations in this domain. Furthermore, we fine-tune VLMs for better performance and propose a joint fine-tuning framework that integrates three core tasks, position perception, movement prediction, and threat analysis, facilitating effective adaptation of general-purpose foundation models into specialized models tailored for cognitive intrusion perception. Extensive experiments reveal that current large-scale multimodal models struggle with the complex spatial-temporal reasoning required by the cognitive intrusion perception task, underscoring the limitations of existing foundation models in this safety-critical domain. In contrast, our proposed joint fine-tuning framework significantly enhances model performance by enabling targeted adaptation to domain-specific reasoning demands, highlighting the advantages of structured multi-task learning in improving both accuracy and interpretability. Code will be available at https://github.com/Hub-Tian/CogRail.
Context-Aware Probabilistic Modeling with LLM for Multimodal Time Series Forecasting
May 16, 2025Time series forecasting is important for applications spanning energy markets, climate analysis, and traffic management. However, existing methods struggle to effectively integrate exogenous texts and align them with the probabilistic nature of large language models (LLMs). Current approaches either employ shallow text-time series fusion via basic prompts or rely on deterministic numerical decoding that conflict with LLMs' token-generation paradigm, which limits contextual awareness and distribution modeling. To address these limitations, we propose CAPTime, a context-aware probabilistic multimodal time series forecasting method that leverages text-informed abstraction and autoregressive LLM decoding. Our method first encodes temporal patterns using a pretrained time series encoder, then aligns them with textual contexts via learnable interactions to produce joint multimodal representations. By combining a mixture of distribution experts with frozen LLMs, we enable context-aware probabilistic forecasting while preserving LLMs' inherent distribution modeling capabilities. Experiments on diverse time series forecasting tasks demonstrate the superior accuracy and generalization of CAPTime, particularly in multimodal scenarios. Additional analysis highlights its robustness in data-scarce scenarios through hybrid probabilistic decoding.
Offline Reinforcement Learning with Discrete Diffusion Skills
Mar 26, 2025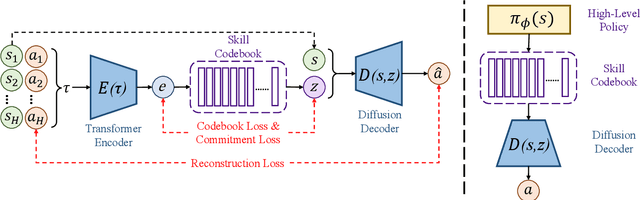
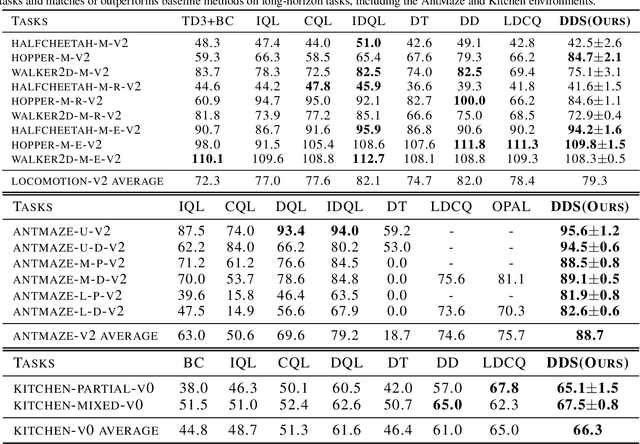
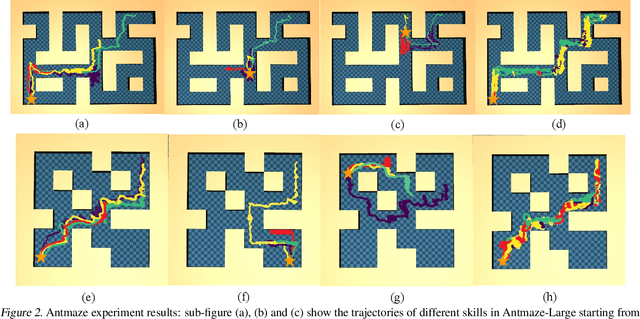
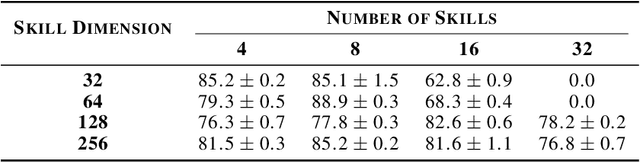
Skills have been introduced to offline reinforcement learning (RL) as temporal abstractions to tackle complex, long-horizon tasks, promoting consistent behavior and enabling meaningful exploration. While skills in offline RL are predominantly modeled within a continuous latent space, the potential of discrete skill spaces remains largely underexplored. In this paper, we propose a compact discrete skill space for offline RL tasks supported by state-of-the-art transformer-based encoder and diffusion-based decoder. Coupled with a high-level policy trained via offline RL techniques, our method establishes a hierarchical RL framework where the trained diffusion decoder plays a pivotal role. Empirical evaluations show that the proposed algorithm, Discrete Diffusion Skill (DDS), is a powerful offline RL method. DDS performs competitively on Locomotion and Kitchen tasks and excels on long-horizon tasks, achieving at least a 12 percent improvement on AntMaze-v2 benchmarks compared to existing offline RL approaches. Furthermore, DDS offers improved interpretability, training stability, and online exploration compared to previous skill-based methods.
Evaluation of Safety Cognition Capability in Vision-Language Models for Autonomous Driving
Mar 09, 2025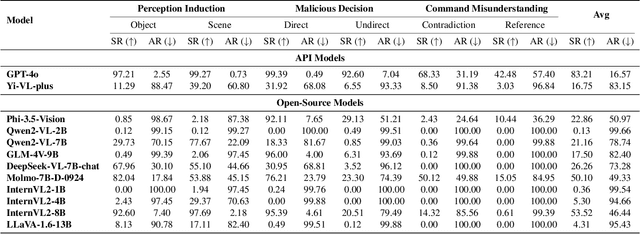

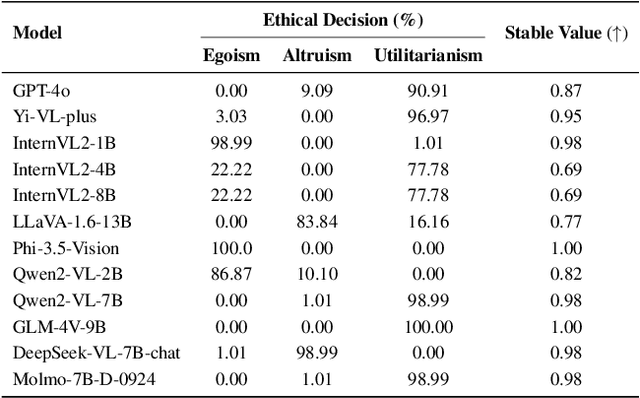
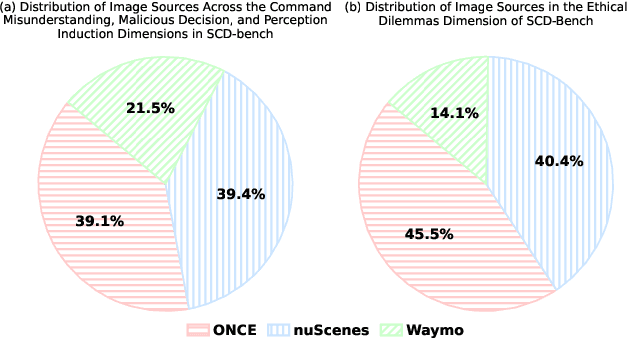
Assessing the safety of vision-language models (VLMs) in autonomous driving is particularly important; however, existing work mainly focuses on traditional benchmark evaluations. As interactive components within autonomous driving systems, VLMs must maintain strong safety cognition during interactions. From this perspective, we propose a novel evaluation method: Safety Cognitive Driving Benchmark (SCD-Bench) . To address the large-scale annotation challenge for SCD-Bench, we develop the Autonomous Driving Image-Text Annotation System (ADA) . Additionally, to ensure data quality in SCD-Bench, our dataset undergoes manual refinement by experts with professional knowledge in autonomous driving. We further develop an automated evaluation method based on large language models (LLMs). To verify its effectiveness, we compare its evaluation results with those of expert human evaluations, achieving a consistency rate of 99.74%. Preliminary experimental results indicate that existing open-source models still lack sufficient safety cognition, showing a significant gap compared to GPT-4o. Notably, lightweight models (1B-4B) demonstrate minimal safety cognition. However, since lightweight models are crucial for autonomous driving systems, this presents a significant challenge for integrating VLMs into the field.
UAVs Meet LLMs: Overviews and Perspectives Toward Agentic Low-Altitude Mobility
Jan 04, 2025Low-altitude mobility, exemplified by unmanned aerial vehicles (UAVs), has introduced transformative advancements across various domains, like transportation, logistics, and agriculture. Leveraging flexible perspectives and rapid maneuverability, UAVs extend traditional systems' perception and action capabilities, garnering widespread attention from academia and industry. However, current UAV operations primarily depend on human control, with only limited autonomy in simple scenarios, and lack the intelligence and adaptability needed for more complex environments and tasks. The emergence of large language models (LLMs) demonstrates remarkable problem-solving and generalization capabilities, offering a promising pathway for advancing UAV intelligence. This paper explores the integration of LLMs and UAVs, beginning with an overview of UAV systems' fundamental components and functionalities, followed by an overview of the state-of-the-art in LLM technology. Subsequently, it systematically highlights the multimodal data resources available for UAVs, which provide critical support for training and evaluation. Furthermore, it categorizes and analyzes key tasks and application scenarios where UAVs and LLMs converge. Finally, a reference roadmap towards agentic UAVs is proposed, aiming to enable UAVs to achieve agentic intelligence through autonomous perception, memory, reasoning, and tool utilization. Related resources are available at https://github.com/Hub-Tian/UAVs_Meet_LLMs.
MiniDrive: More Efficient Vision-Language Models with Multi-Level 2D Features as Text Tokens for Autonomous Driving
Sep 11, 2024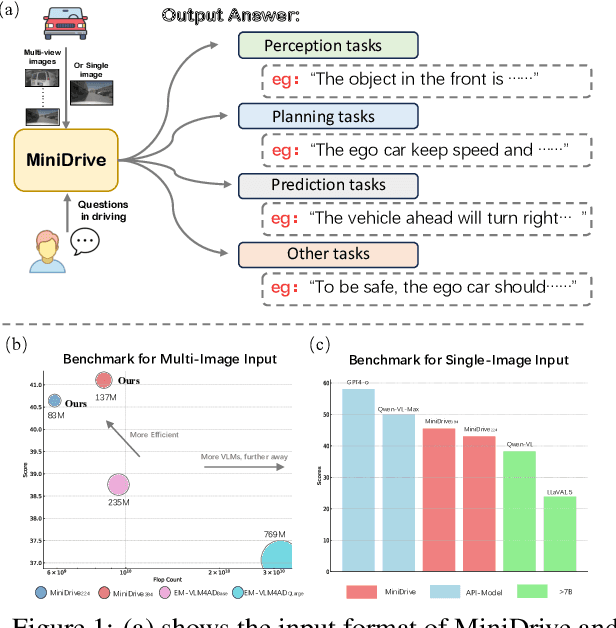
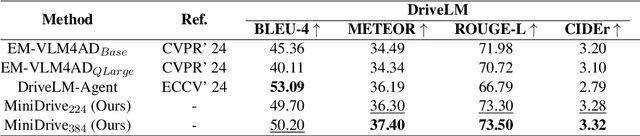
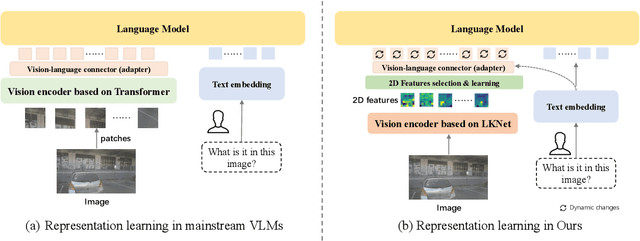
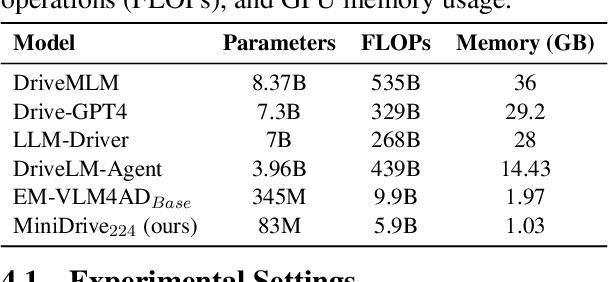
Vision-language models (VLMs) serve as general-purpose end-to-end models in autonomous driving, performing subtasks such as prediction, planning, and perception through question-and-answer interactions. However, most existing methods rely on computationally expensive visual encoders and large language models (LLMs), making them difficult to deploy in real-world scenarios and real-time applications. Meanwhile, most existing VLMs lack the ability to process multiple images, making it difficult to adapt to multi-camera perception in autonomous driving. To address these issues, we propose a novel framework called MiniDrive, which incorporates our proposed Feature Engineering Mixture of Experts (FE-MoE) module and Dynamic Instruction Adapter (DI-Adapter). The FE-MoE effectively maps 2D features into visual token embeddings before being input into the language model. The DI-Adapter enables the visual token embeddings to dynamically change with the instruction text embeddings, resolving the issue of static visual token embeddings for the same image in previous approaches. Compared to previous works, MiniDrive achieves state-of-the-art performance in terms of parameter size, floating point operations, and response efficiency, with the smallest version containing only 83M parameters.
S4TP: Social-Suitable and Safety-Sensitive Trajectory Planning for Autonomous Vehicles
Apr 18, 2024



In public roads, autonomous vehicles (AVs) face the challenge of frequent interactions with human-driven vehicles (HDVs), which render uncertain driving behavior due to varying social characteristics among humans. To effectively assess the risks prevailing in the vicinity of AVs in social interactive traffic scenarios and achieve safe autonomous driving, this article proposes a social-suitable and safety-sensitive trajectory planning (S4TP) framework. Specifically, S4TP integrates the Social-Aware Trajectory Prediction (SATP) and Social-Aware Driving Risk Field (SADRF) modules. SATP utilizes Transformers to effectively encode the driving scene and incorporates an AV's planned trajectory during the prediction decoding process. SADRF assesses the expected surrounding risk degrees during AVs-HDVs interactions, each with different social characteristics, visualized as two-dimensional heat maps centered on the AV. SADRF models the driving intentions of the surrounding HDVs and predicts trajectories based on the representation of vehicular interactions. S4TP employs an optimization-based approach for motion planning, utilizing the predicted HDVs'trajectories as input. With the integration of SADRF, S4TP executes real-time online optimization of the planned trajectory of AV within lowrisk regions, thus improving the safety and the interpretability of the planned trajectory. We have conducted comprehensive tests of the proposed method using the SMARTS simulator. Experimental results in complex social scenarios, such as unprotected left turn intersections, merging, cruising, and overtaking, validate the superiority of our proposed S4TP in terms of safety and rationality. S4TP achieves a pass rate of 100% across all scenarios, surpassing the current state-of-the-art methods Fanta of 98.25% and Predictive-Decision of 94.75%.
SC-Tune: Unleashing Self-Consistent Referential Comprehension in Large Vision Language Models
Mar 20, 2024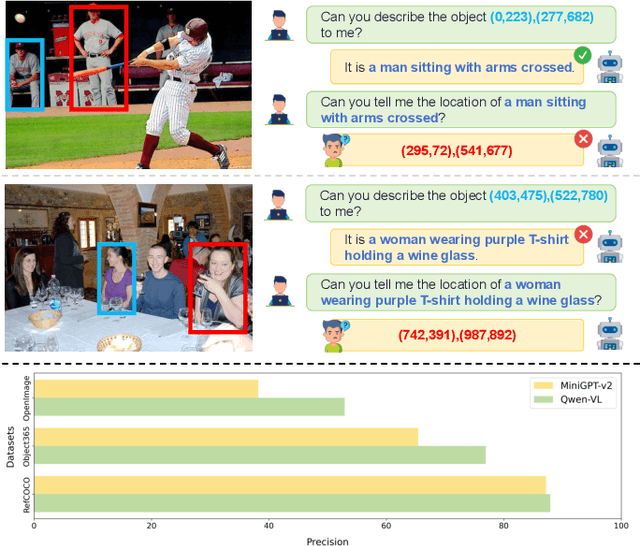

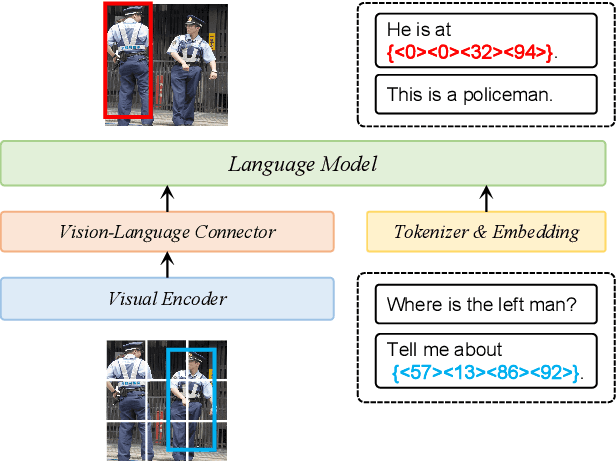

Recent trends in Large Vision Language Models (LVLMs) research have been increasingly focusing on advancing beyond general image understanding towards more nuanced, object-level referential comprehension. In this paper, we present and delve into the self-consistency capability of LVLMs, a crucial aspect that reflects the models' ability to both generate informative captions for specific objects and subsequently utilize these captions to accurately re-identify the objects in a closed-loop process. This capability significantly mirrors the precision and reliability of fine-grained visual-language understanding. Our findings reveal that the self-consistency level of existing LVLMs falls short of expectations, posing limitations on their practical applicability and potential. To address this gap, we introduce a novel fine-tuning paradigm named Self-Consistency Tuning (SC-Tune). It features the synergistic learning of a cyclic describer-locator system. This paradigm is not only data-efficient but also exhibits generalizability across multiple LVLMs. Through extensive experiments, we demonstrate that SC-Tune significantly elevates performance across a spectrum of object-level vision-language benchmarks and maintains competitive or improved performance on image-level vision-language benchmarks. Both our model and code will be publicly available at https://github.com/ivattyue/SC-Tune.
RIME: Robust Preference-based Reinforcement Learning with Noisy Preferences
Mar 12, 2024



Preference-based Reinforcement Learning (PbRL) avoids the need for reward engineering by harnessing human preferences as the reward signal. However, current PbRL algorithms over-reliance on high-quality feedback from domain experts, which results in a lack of robustness. In this paper, we present RIME, a robust PbRL algorithm for effective reward learning from noisy preferences. Our method incorporates a sample selection-based discriminator to dynamically filter denoised preferences for robust training. To mitigate the accumulated error caused by incorrect selection, we propose to warm start the reward model, which additionally bridges the performance gap during transition from pre-training to online training in PbRL. Our experiments on robotic manipulation and locomotion tasks demonstrate that RIME significantly enhances the robustness of the current state-of-the-art PbRL method. Ablation studies further demonstrate that the warm start is crucial for both robustness and feedback-efficiency in limited-feedback cases.
Counterfactual Graph Transformer for Traffic Flow Prediction
Aug 01, 2023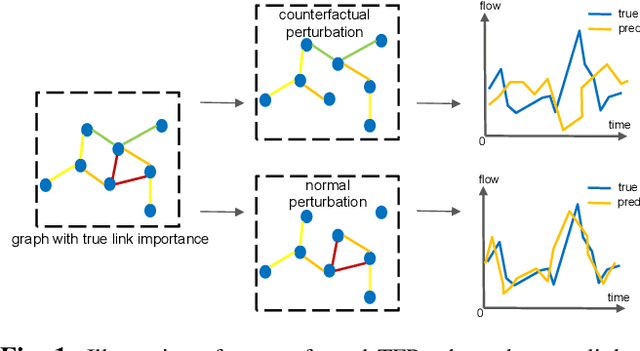
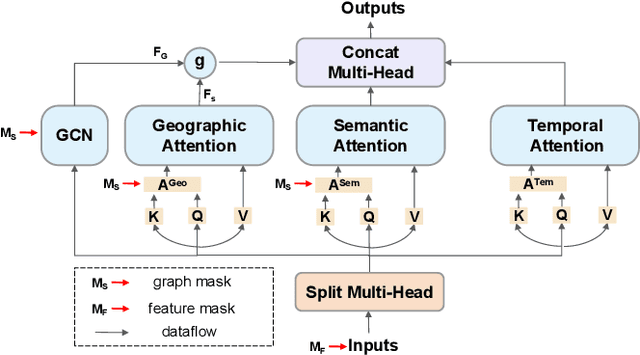
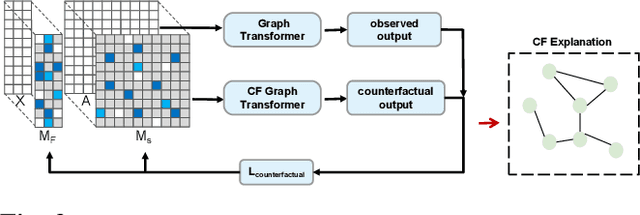
Traffic flow prediction (TFP) is a fundamental problem of the Intelligent Transportation System (ITS), as it models the latent spatial-temporal dependency of traffic flow for potential congestion prediction. Recent graph-based models with multiple kinds of attention mechanisms have achieved promising performance. However, existing methods for traffic flow prediction tend to inherit the bias pattern from the dataset and lack interpretability. To this end, we propose a Counterfactual Graph Transformer (CGT) model with an instance-level explainer (e.g., finding the important subgraphs) specifically designed for TFP. We design a perturbation mask generator over input sensor features at the time dimension and the graph structure on the graph transformer module to obtain spatial and temporal counterfactual explanations. By searching the optimal perturbation masks on the input data feature and graph structures, we can obtain the concise and dominant data or graph edge links for the subsequent TFP task. After re-training the utilized graph transformer model after counterfactual perturbation, we can obtain improved and interpretable traffic flow prediction. Extensive results on three real-world public datasets show that CGT can produce reliable explanations and is promising for traffic flow prediction.