 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^3$-VQA: A Benchmark for Multimodal, Multi-Entity, Multi-Hop Visual Question Answering
Apr 28, 2026We present M$^3$-VQA, a novel knowledge-based Visual Question Answering (VQA) benchmark, to enhance the evaluation of multimodal large language models (MLLMs) in fine-grained multimodal entity understanding and complex multi-hop reasoning. Unlike existing VQA datasets that focus on coarse-grained categories and simple reasoning over single entities, M$^3$-VQA introduces diverse multi-entity questions involving multiple distinct entities from both visual and textual sources. It requires models to perform both sequential and parallel multi-hop reasoning across multiple documents, supported by traceable, detailed evidence and a curated multimodal knowledge base. We evaluate 16 leading MLLMs under three settings: without external knowledge, with gold evidence, and with retrieval-augmented input. The poor results reveal significant challenges for MLLMs in knowledge acquisition and reasoning. Models perform poorly without external information but improve markedly when provided with precise evidence. Furthermore, reasoning-aware agentic retrieval surpasses heuristic methods, highlighting the importance of structured reasoning for complex multimodal understanding. M$^3$-VQA presents a more challenging evaluation for advancing the multimodal reasoning capabilities of MLLMs. Our code and dataset are available at https://github.com/CASIA-IVA-Lab/M3VQA.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models
Jan 28, 2026We introduce WorldVQA, a benchmark designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike current evaluations, which often conflate visual knowledge retrieval with reasoning, WorldVQA decouples these capabilities to strictly measure "what the model memorizes." The benchmark assesses the atomic capability of grounding and naming visual entities across a stratified taxonomy, spanning from common head-class objects to long-tail rarities. We expect WorldVQA to serve as a rigorous test for visual factuality, thereby establishing a standard for assessing the encyclopedic breadth and hallucination rates of current and next-generation frontier models.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Image Difference Grounding with Natural Language
Apr 02, 2025Visual grounding (VG) typically focuses on locating regions of interest within an image using natural language, and most existing VG methods are limited to single-image interpretations. This limits their applicability in real-world scenarios like automatic surveillance, where detecting subtle but meaningful visual differences across multiple images is crucial. Besides, previous work on image difference understanding (IDU) has either focused on detecting all change regions without cross-modal text guidance, or on providing coarse-grained descriptions of differences. Therefore, to push towards finer-grained vision-language perception, we propose Image Difference Grounding (IDG), a task designed to precisely localize visual differences based on user instructions. We introduce DiffGround, a large-scale and high-quality dataset for IDG, containing image pairs with diverse visual variations along with instructions querying fine-grained differences. Besides, we present a baseline model for IDG, DiffTracker, which effectively integrates feature differential enhancement and common suppression to precisely locate differences. Experiments on the DiffGround dataset highlight the importance of our IDG dataset in enabling finer-grained IDU. To foster future research, both DiffGround data and DiffTracker model will be publicly released.
Efficient Motion-Aware Video MLLM
Mar 17, 2025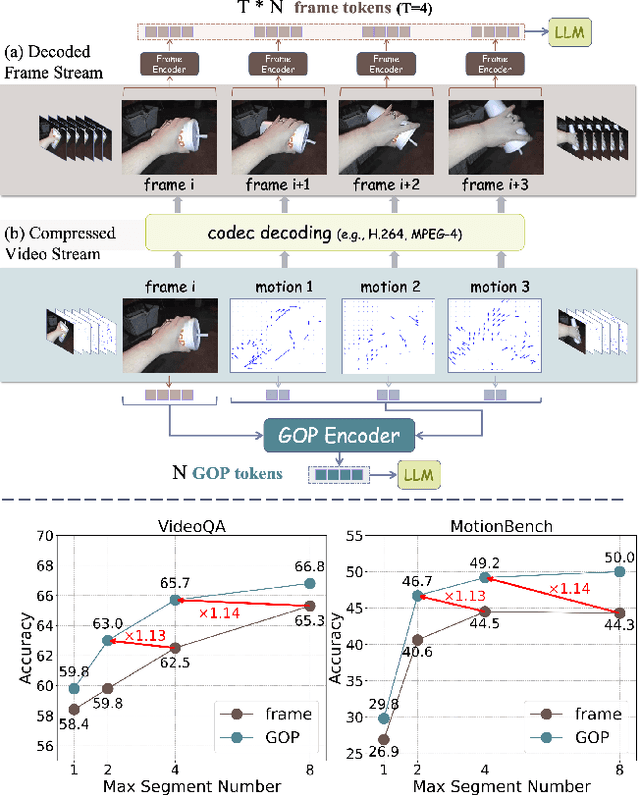
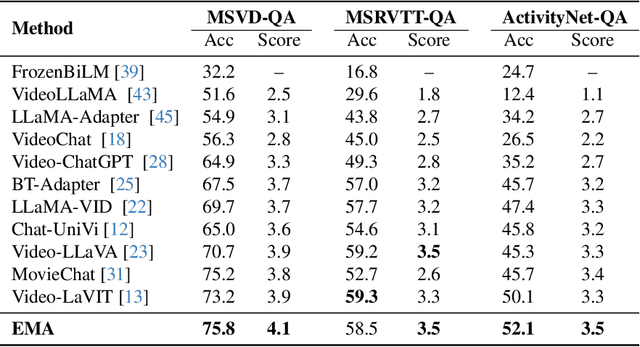
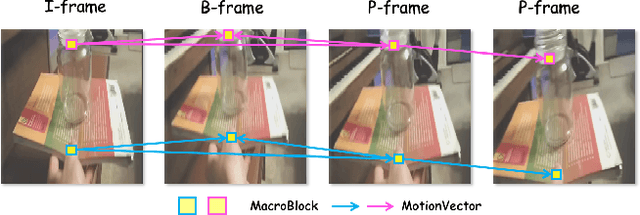
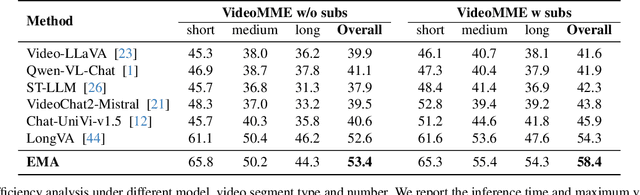
Most current video MLLMs rely on uniform frame sampling and image-level encoders, resulting in inefficient data processing and limited motion awareness. To address these challenges, we introduce EMA, an Efficient Motion-Aware video MLLM that utilizes compressed video structures as inputs. We propose a motion-aware GOP (Group of Pictures) encoder that fuses spatial and motion information within a GOP unit in the compressed video stream, generating compact, informative visual tokens. By integrating fewer but denser RGB frames with more but sparser motion vectors in this native slow-fast input architecture, our approach reduces redundancy and enhances motion representation. Additionally, we introduce MotionBench, a benchmark for evaluating motion understanding across four motion types: linear, curved, rotational, and contact-based. Experimental results show that EMA achieves state-of-the-art performance on both MotionBench and popular video question answering benchmarks, while reducing inference costs. Moreover, EMA demonstrates strong scalability, as evidenced by its competitive performance on long video understanding benchmarks.
ChatSearch: a Dataset and a Generative Retrieval Model for General Conversational Image Retrieval
Oct 24, 2024
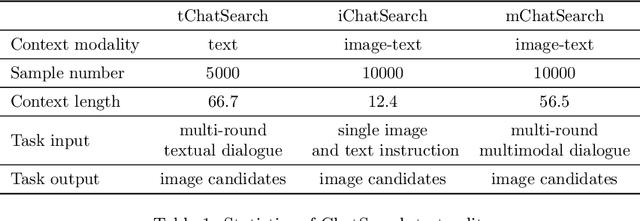
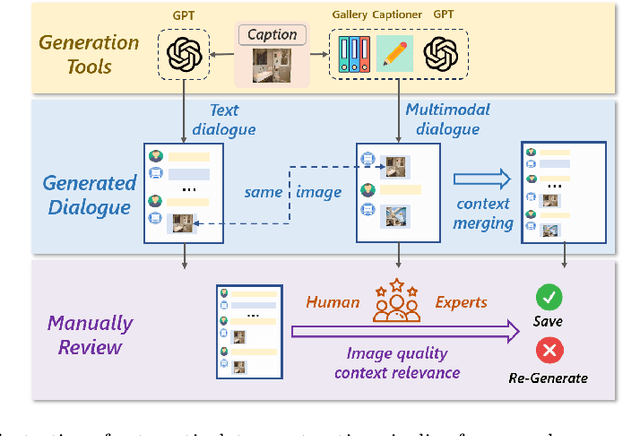
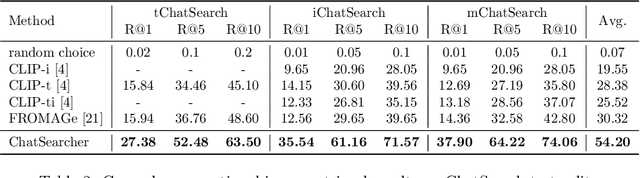
In this paper, we investigate the task of general conversational image retrieval on open-domain images. The objective is to search for images based on interactive conversations between humans and computers. To advance this task, we curate a dataset called ChatSearch. This dataset includes a multi-round multimodal conversational context query for each target image, thereby requiring the retrieval system to find the accurate image from database. Simultaneously, we propose a generative retrieval model named ChatSearcher, which is trained end-to-end to accept/produce interleaved image-text inputs/outputs. ChatSearcher exhibits strong capability in reasoning with multimodal context and can leverage world knowledge to yield visual retrieval results. It demonstrates superior performance on the ChatSearch dataset and also achieves competitive results on other image retrieval tasks and visual conversation tasks. We anticipate that this work will inspire further research on interactive multimodal retrieval systems. Our dataset will be available at https://github.com/joez17/ChatSearch.
Beyond Filtering: Adaptive Image-Text Quality Enhancement for MLLM Pretraining
Oct 21, 2024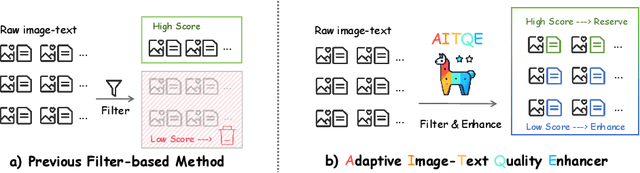



Multimodal large language models (MLLMs) have made significant strides by integrating visual and textual modalities. A critical factor in training MLLMs is the quality of image-text pairs within multimodal pretraining datasets. However, $\textit {de facto}$ filter-based data quality enhancement paradigms often discard a substantial portion of high-quality image data due to inadequate semantic alignment between images and texts, leading to inefficiencies in data utilization and scalability. In this paper, we propose the Adaptive Image-Text Quality Enhancer (AITQE), a model that dynamically assesses and enhances the quality of image-text pairs. AITQE employs a text rewriting mechanism for low-quality pairs and incorporates a negative sample learning strategy to improve evaluative capabilities by integrating deliberately selected low-quality samples during training. Unlike prior approaches that significantly alter text distributions, our method minimally adjusts text to preserve data volume while enhancing quality. Experimental results demonstrate that AITQE surpasses existing methods on various benchmark, effectively leveraging raw data and scaling efficiently with increasing data volumes. We hope our work will inspire future works. The code and model are available at: https://github.com/hanhuang22/AITQE.
Exploring the Design Space of Visual Context Representation in Video MLLMs
Oct 17, 2024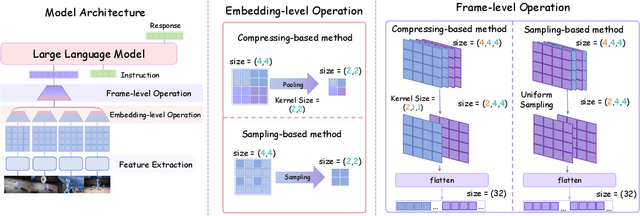
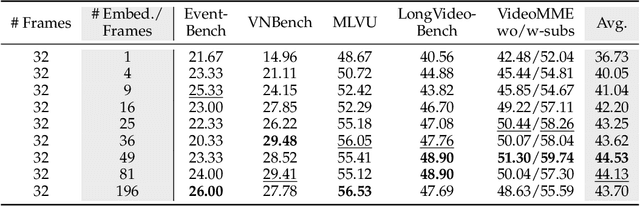
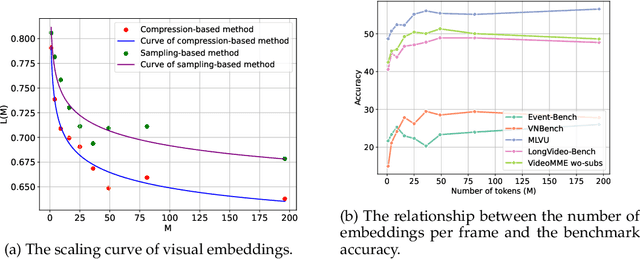
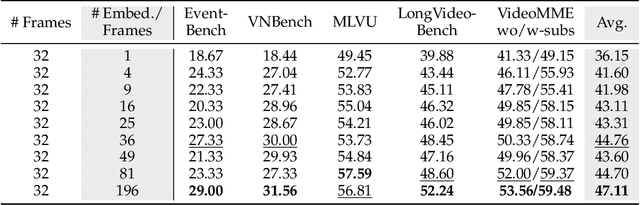
Video Multimodal Large Language Models (MLLMs) have shown remarkable capability of understanding the video semantics on various downstream tasks. Despite the advancements, there is still a lack of systematic research on visual context representation, which refers to the scheme to select frames from a video and further select the tokens from a frame. In this paper, we explore the design space for visual context representation, and aim to improve the performance of video MLLMs by finding more effective representation schemes. Firstly, we formulate the task of visual context representation as a constrained optimization problem, and model the language modeling loss as a function of the number of frames and the number of embeddings (or tokens) per frame, given the maximum visual context window size. Then, we explore the scaling effects in frame selection and token selection respectively, and fit the corresponding function curve by conducting extensive empirical experiments. We examine the effectiveness of typical selection strategies and present empirical findings to determine the two factors. Furthermore, we study the joint effect of frame selection and token selection, and derive the optimal formula for determining the two factors. We demonstrate that the derived optimal settings show alignment with the best-performed results of empirical experiments. Our code and model are available at: https://github.com/RUCAIBox/Opt-Visor.
OneDiff: A Generalist Model for Image Difference
Jul 08, 2024



In computer vision, Image Difference Captioning (IDC) is crucial for accurately describing variations between closely related images. Traditional IDC methods often rely on specialist models, which restrict their applicability across varied contexts. This paper introduces the OneDiff model, a novel generalist approach that utilizes a robust vision-language model architecture, integrating a siamese image encoder with a Visual Delta Module. This innovative configuration allows for the precise detection and articulation of fine-grained differences between image pairs. OneDiff is trained through a dual-phase strategy, encompassing Coupled Sample Training and multi-task learning across a diverse array of data types, supported by our newly developed DiffCap Dataset. This dataset merges real-world and synthetic data, enhancing the training process and bolstering the model's robustness. Extensive testing on diverse IDC benchmarks, such as Spot-the-Diff, CLEVR-Change, and Birds-to-Words, shows that OneDiff consistently outperforms existing state-of-the-art models in accuracy and adaptability, achieving improvements of up to 85\% CIDEr points in average. By setting a new benchmark in IDC, OneDiff paves the way for more versatile and effective applications in detecting and describing visual differences. The code, models, and data will be made publicly available.