 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLI-DSN: A Layer-wise Interactive Dual-Stream Network for EEG Decoding
Apr 02, 2026Electroencephalography (EEG) provides a non-invasive window into brain activity, offering high temporal resolution crucial for understanding and interacting with neural processes through brain-computer interfaces (BCIs). Current dual-stream neural networks for EEG often process temporal and spatial features independently through parallel branches, delaying their integration until a final, late-stage fusion. This design inherently leads to an "information silo" problem, precluding intermediate cross-stream refinement and hindering spatial-temporal decompositions essential for full feature utilization. We propose LI-DSN, a layer-wise interactive dual-stream network that facilitates progressive, cross-stream communication at each layer, thereby overcoming the limitations of late-fusion paradigms. LI-DSN introduces a novel Temporal-Spatial Integration Attention (TSIA) mechanism, which constructs a Spatial Affinity Correlation Matrix (SACM) to capture inter-electrode spatial structural relationships and a Temporal Channel Aggregation Matrix (TCAM) to integrate cosine-gated temporal dynamics under spatial guidance. Furthermore, we employ an adaptive fusion strategy with learnable channel weights to optimize the integration of dual-stream features. Extensive experiments across eight diverse EEG datasets, encompassing motor imagery (MI) classification, emotion recognition, and steady-state visual evoked potentials (SSVEP), consistently demonstrate that LI-DSN significantly outperforms 13 state-of-the-art (SOTA) baseline models, showcasing its superior robustness and decoding performance. The code will be publicized after acceptance.
Towards Unified Referring Expression Segmentation Across Omni-Level Visual Target Granularities
Apr 02, 2025Referring expression segmentation (RES) aims at segmenting the entities' masks that match the descriptive language expression. While traditional RES methods primarily address object-level grounding, real-world scenarios demand a more versatile framework that can handle multiple levels of target granularity, such as multi-object, single object or part-level references. This introduces great challenges due to the diverse and nuanced ways users describe targets. However, existing datasets and models mainly focus on designing grounding specialists for object-level target localization, lacking the necessary data resources and unified frameworks for the more practical multi-grained RES. In this paper, we take a step further towards visual granularity unified RES task. To overcome the limitation of data scarcity, we introduce a new multi-granularity referring expression segmentation (MRES) task, alongside the RefCOCOm benchmark, which includes part-level annotations for advancing finer-grained visual understanding. In addition, we create MRES-32M, the largest visual grounding dataset, comprising over 32.2M masks and captions across 1M images, specifically designed for part-level vision-language grounding. To tackle the challenges of multi-granularity RES, we propose UniRES++, a unified multimodal large language model that integrates object-level and part-level RES tasks. UniRES++ incorporates targeted designs for fine-grained visual feature exploration. With the joint model architecture and parameters, UniRES++ achieves state-of-the-art performance across multiple benchmarks, including RefCOCOm for MRES, gRefCOCO for generalized RES, and RefCOCO, RefCOCO+, RefCOCOg for classic RES. To foster future research into multi-grained visual grounding, our RefCOCOm benchmark, MRES-32M dataset and model UniRES++ will be publicly available at https://github.com/Rubics-Xuan/MRES.
Image Difference Grounding with Natural Language
Apr 02, 2025Visual grounding (VG) typically focuses on locating regions of interest within an image using natural language, and most existing VG methods are limited to single-image interpretations. This limits their applicability in real-world scenarios like automatic surveillance, where detecting subtle but meaningful visual differences across multiple images is crucial. Besides, previous work on image difference understanding (IDU) has either focused on detecting all change regions without cross-modal text guidance, or on providing coarse-grained descriptions of differences. Therefore, to push towards finer-grained vision-language perception, we propose Image Difference Grounding (IDG), a task designed to precisely localize visual differences based on user instructions. We introduce DiffGround, a large-scale and high-quality dataset for IDG, containing image pairs with diverse visual variations along with instructions querying fine-grained differences. Besides, we present a baseline model for IDG, DiffTracker, which effectively integrates feature differential enhancement and common suppression to precisely locate differences. Experiments on the DiffGround dataset highlight the importance of our IDG dataset in enabling finer-grained IDU. To foster future research, both DiffGround data and DiffTracker model will be publicly released.
Referring Remote Sensing Image Segmentation via Bidirectional Alignment Guided Joint Prediction
Feb 12, 2025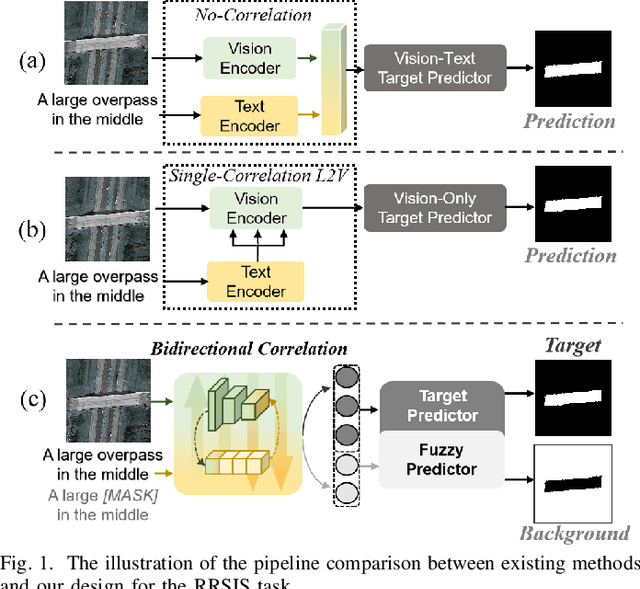



Referring Remote Sensing Image Segmentation (RRSIS) is critical for ecological monitoring, urban planning, and disaster management, requiring precise segmentation of objects in remote sensing imagery guided by textual descriptions. This task is uniquely challenging due to the considerable vision-language gap, the high spatial resolution and broad coverage of remote sensing imagery with diverse categories and small targets, and the presence of clustered, unclear targets with blurred edges. To tackle these issues, we propose \ours, a novel framework designed to bridge the vision-language gap, enhance multi-scale feature interaction, and improve fine-grained object differentiation. Specifically, \ours introduces: (1) the Bidirectional Spatial Correlation (BSC) for improved vision-language feature alignment, (2) the Target-Background TwinStream Decoder (T-BTD) for precise distinction between targets and non-targets, and (3) the Dual-Modal Object Learning Strategy (D-MOLS) for robust multimodal feature reconstruction. Extensive experiments on the benchmark datasets RefSegRS and RRSIS-D demonstrate that \ours achieves state-of-the-art performance. Specifically, \ours improves the overall IoU (oIoU) by 3.76 percentage points (80.57) and 1.44 percentage points (79.23) on the two datasets, respectively. Additionally, it outperforms previous methods in the mean IoU (mIoU) by 5.37 percentage points (67.95) and 1.84 percentage points (66.04), effectively addressing the core challenges of RRSIS with enhanced precision and robustness.
LSVOS Challenge Report: Large-scale Complex and Long Video Object Segmentation
Sep 09, 2024



Despite the promising performance of current video segmentation models on existing benchmarks, these models still struggle with complex scenes. In this paper, we introduce the 6th Large-scale Video Object Segmentation (LSVOS) challenge in conjunction with ECCV 2024 workshop. This year's challenge includes two tasks: Video Object Segmentation (VOS) and Referring Video Object Segmentation (RVOS). In this year, we replace the classic YouTube-VOS and YouTube-RVOS benchmark with latest datasets MOSE, LVOS, and MeViS to assess VOS under more challenging complex environments. This year's challenge attracted 129 registered teams from more than 20 institutes across over 8 countries. This report include the challenge and dataset introduction, and the methods used by top 7 teams in two tracks. More details can be found in our homepage https://lsvos.github.io/.
The Instance-centric Transformer for the RVOS Track of LSVOS Challenge: 3rd Place Solution
Aug 20, 2024Referring Video Object Segmentation is an emerging multi-modal task that aims to segment objects in the video given a natural language expression. In this work, we build two instance-centric models and fuse predicted results from frame-level and instance-level. First, we introduce instance mask into the DETR-based model for query initialization to achieve temporal enhancement and employ SAM for spatial refinement. Secondly, we build an instance retrieval model conducting binary instance mask classification whether the instance is referred. Finally, we fuse predicted results and our method achieved a score of 52.67 J&F in the validation phase and 60.36 J&F in the test phase, securing the final ranking of 3rd place in the 6-th LSVOS Challenge RVOS Track.
PVUW 2024 Challenge on Complex Video Understanding: Methods and Results
Jun 24, 2024



Pixel-level Video Understanding in the Wild Challenge (PVUW) focus on complex video understanding. In this CVPR 2024 workshop, we add two new tracks, Complex Video Object Segmentation Track based on MOSE dataset and Motion Expression guided Video Segmentation track based on MeViS dataset. In the two new tracks, we provide additional videos and annotations that feature challenging elements, such as the disappearance and reappearance of objects, inconspicuous small objects, heavy occlusions, and crowded environments in MOSE. Moreover, we provide a new motion expression guided video segmentation dataset MeViS to study the natural language-guided video understanding in complex environments. These new videos, sentences, and annotations enable us to foster the development of a more comprehensive and robust pixel-level understanding of video scenes in complex environments and realistic scenarios. The MOSE challenge had 140 registered teams in total, 65 teams participated the validation phase and 12 teams made valid submissions in the final challenge phase. The MeViS challenge had 225 registered teams in total, 50 teams participated the validation phase and 5 teams made valid submissions in the final challenge phase.
2nd Place Solution for MeViS Track in CVPR 2024 PVUW Workshop: Motion Expression guided Video Segmentation
Jun 20, 2024
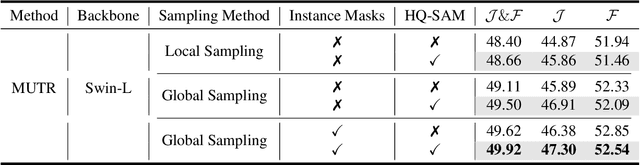
Motion Expression guided Video Segmentation is a challenging task that aims at segmenting objects in the video based on natural language expressions with motion descriptions. Unlike the previous referring video object segmentation (RVOS), this task focuses more on the motion in video content for language-guided video object segmentation, requiring an enhanced ability to model longer temporal, motion-oriented vision-language data. In this report, based on the RVOS methods, we successfully introduce mask information obtained from the video instance segmentation model as preliminary information for temporal enhancement and employ SAM for spatial refinement. Finally, our method achieved a score of 49.92 J &F in the validation phase and 54.20 J &F in the test phase, securing the final ranking of 2nd in the MeViS Track at the CVPR 2024 PVUW Challenge.
Beyond Literal Descriptions: Understanding and Locating Open-World Objects Aligned with Human Intentions
Feb 17, 2024Visual grounding (VG) aims at locating the foreground entities that match the given natural language expression. Previous datasets and methods for classic VG task mainly rely on the prior assumption that the given expression must literally refer to the target object, which greatly impedes the practical deployment of agents in real-world scenarios. Since users usually prefer to provide the intention-based expressions for the desired object instead of covering all the details, it is necessary for the agents to interpret the intention-driven instructions. Thus, in this work, we take a step further to the intention-driven visual-language (V-L) understanding. To promote classic VG towards human intention interpretation, we propose a new intention-driven visual grounding (IVG) task and build a largest-scale IVG dataset named IntentionVG with free-form intention expressions. Considering that practical agents need to move and find specific targets among various scenarios to realize the grounding task, our IVG task and IntentionVG dataset have taken the crucial properties of both multi-scenario perception and egocentric view into consideration. Besides, various types of models are set up as the baselines to realize our IVG task. Extensive experiments on our IntentionVG dataset and baselines demonstrate the necessity and efficacy of our method for the V-L field. To foster future research in this direction, our newly built dataset and baselines will be publicly available.
Adaptive FSS: A Novel Few-Shot Segmentation Framework via Prototype Enhancement
Jan 09, 2024The Few-Shot Segmentation (FSS) aims to accomplish the novel class segmentation task with a few annotated images. Current FSS research based on meta-learning focus on designing a complex interaction mechanism between the query and support feature. However, unlike humans who can rapidly learn new things from limited samples, the existing approach relies solely on fixed feature matching to tackle new tasks, lacking adaptability. In this paper, we propose a novel framework based on the adapter mechanism, namely Adaptive FSS, which can efficiently adapt the existing FSS model to the novel classes. In detail, we design the Prototype Adaptive Module (PAM), which utilizes accurate category information provided by the support set to derive class prototypes, enhancing class-specific information in the multi-stage representation. In addition, our approach is compatible with diverse FSS methods with different backbones by simply inserting PAM between the layers of the encoder. Experiments demonstrate that our method effectively improves the performance of the FSS models (e.g., MSANet, HDMNet, FPTrans, and DCAMA) and achieve new state-of-the-art (SOTA) results (i.e., 72.4\% and 79.1\% mIoU on PASCAL-5$^i$ 1-shot and 5-shot settings, 52.7\% and 60.0\% mIoU on COCO-20$^i$ 1-shot and 5-shot settings). Our code can be available at https://github.com/jingw193/AdaptiveFSS.