 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2nd Place Solution for MeViS Track in CVPR 2024 PVUW Workshop: Motion Expression guided Video Segmentation
Paper and Code
Jun 20, 2024
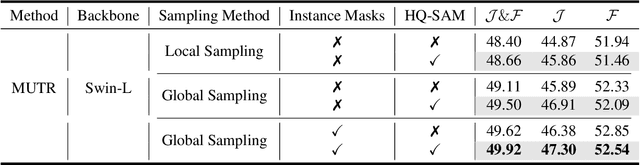
Motion Expression guided Video Segmentation is a challenging task that aims at segmenting objects in the video based on natural language expressions with motion descriptions. Unlike the previous referring video object segmentation (RVOS), this task focuses more on the motion in video content for language-guided video object segmentation, requiring an enhanced ability to model longer temporal, motion-oriented vision-language data. In this report, based on the RVOS methods, we successfully introduce mask information obtained from the video instance segmentation model as preliminary information for temporal enhancement and employ SAM for spatial refinement. Finally, our method achieved a score of 49.92 J &F in the validation phase and 54.20 J &F in the test phase, securing the final ranking of 2nd in the MeViS Track at the CVPR 2024 PVUW Challenge.