 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS1-MMAlign: A Large-Scale, Multi-Disciplinary Dataset for Scientific Figure-Text Understanding
Jan 01, 2026Multimodal learning has revolutionized general domain tasks, yet its application in scientific discovery is hindered by the profound semantic gap between complex scientific imagery and sparse textual descriptions. We present S1-MMAlign, a large-scale, multi-disciplinary multimodal dataset comprising over 15.5 million high-quality image-text pairs derived from 2.5 million open-access scientific papers. Spanning disciplines from physics and biology to engineering, the dataset captures diverse visual modalities including experimental setups, heatmaps, and microscopic imagery. To address the pervasive issue of weak alignment in raw scientific captions, we introduce an AI-ready semantic enhancement pipeline that utilizes the Qwen-VL multimodal large model series to recaption images by synthesizing context from paper abstracts and citation contexts. Technical validation demonstrates that this enhancement significantly improves data quality: SciBERT-based pseudo-perplexity metrics show reduced semantic ambiguity, while CLIP scores indicate an 18.21% improvement in image-text alignment. S1-MMAlign provides a foundational resource for advancing scientific reasoning and cross-modal understanding in the era of AI for Science. The dataset is publicly available at https://huggingface.co/datasets/ScienceOne-AI/S1-MMAlign.
PVUW 2024 Challenge on Complex Video Understanding: Methods and Results
Jun 24, 2024



Pixel-level Video Understanding in the Wild Challenge (PVUW) focus on complex video understanding. In this CVPR 2024 workshop, we add two new tracks, Complex Video Object Segmentation Track based on MOSE dataset and Motion Expression guided Video Segmentation track based on MeViS dataset. In the two new tracks, we provide additional videos and annotations that feature challenging elements, such as the disappearance and reappearance of objects, inconspicuous small objects, heavy occlusions, and crowded environments in MOSE. Moreover, we provide a new motion expression guided video segmentation dataset MeViS to study the natural language-guided video understanding in complex environments. These new videos, sentences, and annotations enable us to foster the development of a more comprehensive and robust pixel-level understanding of video scenes in complex environments and realistic scenarios. The MOSE challenge had 140 registered teams in total, 65 teams participated the validation phase and 12 teams made valid submissions in the final challenge phase. The MeViS challenge had 225 registered teams in total, 50 teams participated the validation phase and 5 teams made valid submissions in the final challenge phase.
2nd Place Solution for MeViS Track in CVPR 2024 PVUW Workshop: Motion Expression guided Video Segmentation
Jun 20, 2024
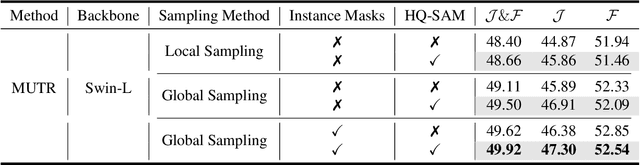
Motion Expression guided Video Segmentation is a challenging task that aims at segmenting objects in the video based on natural language expressions with motion descriptions. Unlike the previous referring video object segmentation (RVOS), this task focuses more on the motion in video content for language-guided video object segmentation, requiring an enhanced ability to model longer temporal, motion-oriented vision-language data. In this report, based on the RVOS methods, we successfully introduce mask information obtained from the video instance segmentation model as preliminary information for temporal enhancement and employ SAM for spatial refinement. Finally, our method achieved a score of 49.92 J &F in the validation phase and 54.20 J &F in the test phase, securing the final ranking of 2nd in the MeViS Track at the CVPR 2024 PVUW Challenge.