 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSVOS Challenge Report: Large-scale Complex and Long Video Object Segmentation
Sep 09, 2024



Despite the promising performance of current video segmentation models on existing benchmarks, these models still struggle with complex scenes. In this paper, we introduce the 6th Large-scale Video Object Segmentation (LSVOS) challenge in conjunction with ECCV 2024 workshop. This year's challenge includes two tasks: Video Object Segmentation (VOS) and Referring Video Object Segmentation (RVOS). In this year, we replace the classic YouTube-VOS and YouTube-RVOS benchmark with latest datasets MOSE, LVOS, and MeViS to assess VOS under more challenging complex environments. This year's challenge attracted 129 registered teams from more than 20 institutes across over 8 countries. This report include the challenge and dataset introduction, and the methods used by top 7 teams in two tracks. More details can be found in our homepage https://lsvos.github.io/.
The Instance-centric Transformer for the RVOS Track of LSVOS Challenge: 3rd Place Solution
Aug 20, 2024Referring Video Object Segmentation is an emerging multi-modal task that aims to segment objects in the video given a natural language expression. In this work, we build two instance-centric models and fuse predicted results from frame-level and instance-level. First, we introduce instance mask into the DETR-based model for query initialization to achieve temporal enhancement and employ SAM for spatial refinement. Secondly, we build an instance retrieval model conducting binary instance mask classification whether the instance is referred. Finally, we fuse predicted results and our method achieved a score of 52.67 J&F in the validation phase and 60.36 J&F in the test phase, securing the final ranking of 3rd place in the 6-th LSVOS Challenge RVOS Track.
Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
Apr 07, 2024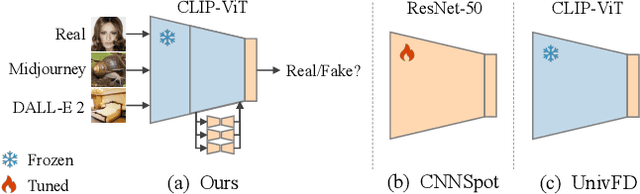



Generative models have shown a giant leap in synthesizing photo-realistic images with minimal expertise, sparking concerns about the authenticity of online information. This study aims to develop a universal AI-generated image detector capable of identifying images from diverse sources. Existing methods struggle to generalize across unseen generative models when provided with limited sample sources. Inspired by the zero-shot transferability of pre-trained vision-language models, we seek to harness the nontrivial visual-world knowledge and descriptive proficiency of CLIP-ViT to generalize over unknown domains. This paper presents a novel parameter-efficient fine-tuning approach, mixture of low-rank experts, to fully exploit CLIP-ViT's potential while preserving knowledge and expanding capacity for transferable detection. We adapt only the MLP layers of deeper ViT blocks via an integration of shared and separate LoRAs within an MoE-based structure. Extensive experiments on public benchmarks show that our method achieves superiority over state-of-the-art approaches in cross-generator generalization and robustness to perturbations. Remarkably, our best-performing ViT-L/14 variant requires training only 0.08% of its parameters to surpass the leading baseline by +3.64% mAP and +12.72% avg.Acc across unseen diffusion and autoregressive models. This even outperforms the baseline with just 0.28% of the training data. Our code and pre-trained models will be available at https://github.com/zhliuworks/CLIPMoLE.
Fictional Worlds, Real Connections: Developing Community Storytelling Social Chatbots through LLMs
Sep 20, 2023We address the integration of storytelling and Large Language Models (LLMs) to develop engaging and believable Social Chatbots (SCs) in community settings. Motivated by the potential of fictional characters to enhance social interactions, we introduce Storytelling Social Chatbots (SSCs) and the concept of story engineering to transform fictional game characters into "live" social entities within player communities. Our story engineering process includes three steps: (1) Character and story creation, defining the SC's personality and worldview, (2) Presenting Live Stories to the Community, allowing the SC to recount challenges and seek suggestions, and (3) Communication with community members, enabling interaction between the SC and users. We employed the LLM GPT-3 to drive our SSC prototypes, "David" and "Catherine," and evaluated their performance in an online gaming community, "DE (Alias)," on Discord. Our mixed-method analysis, based on questionnaires (N=15) and interviews (N=8) with community members, reveals that storytelling significantly enhances the engagement and believability of SCs in community settings.
Cross-Domain Local Characteristic Enhanced Deepfake Video Detection
Nov 07, 2022As ultra-realistic face forgery techniques emerge, deepfake detection has attracted increasing attention due to security concerns. Many detectors cannot achieve accurate results when detecting unseen manipulations despite excellent performance on known forgeries. In this paper, we are motivated by the observation that the discrepancies between real and fake videos are extremely subtle and localized, and inconsistencies or irregularities can exist in some critical facial regions across various information domains. To this end, we propose a novel pipeline, Cross-Domain Local Forensics (XDLF), for more general deepfake video detection. In the proposed pipeline, a specialized framework is presented to simultaneously exploit local forgery patterns from space, frequency, and time domains, thus learning cross-domain features to detect forgeries. Moreover, the framework leverages four high-level forgery-sensitive local regions of a human face to guide the model to enhance subtle artifacts and localize potential anomalies. Extensive experiments on several benchmark datasets demonstrate the impressive performance of our method, and we achieve superiority over several state-of-the-art methods on cross-dataset generalization. We also examined the factors that contribute to its performance through ablations, which suggests that exploiting cross-domain local characteristics is a noteworthy direction for developing more general deepfake detectors.