 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandmark Guided Visual Feature Extractor for Visual Speech Recognition with Limited Resource
Aug 10, 2025Visual speech recognition is a technique to identify spoken content in silent speech videos, which has raised significant attention in recent years. Advancements in data-driven deep learning methods have significantly improved both the speed and accuracy of recognition. However, these deep learning methods can be effected by visual disturbances, such as lightning conditions, skin texture and other user-specific features. Data-driven approaches could reduce the performance degradation caused by these visual disturbances using models pretrained on large-scale datasets. But these methods often require large amounts of training data and computational resources, making them costly. To reduce the influence of user-specific features and enhance performance with limited data, this paper proposed a landmark guided visual feature extractor. Facial landmarks are used as auxiliary information to aid in training the visual feature extractor. A spatio-temporal multi-graph convolutional network is designed to fully exploit the spatial locations and spatio-temporal features of facial landmarks. Additionally, a multi-level lip dynamic fusion framework is introduced to combine the spatio-temporal features of the landmarks with the visual features extracted from the raw video frames. Experimental results show that this approach performs well with limited data and also improves the model's accuracy on unseen speakers.
FGS-Audio: Fixed-Decoder Framework for Audio Steganography with Adversarial Perturbation Generation
May 28, 2025



The rapid development of Artificial Intelligence Generated Content (AIGC) has made high-fidelity generated audio widely available across the Internet, offering an abundant and versatile source of cover signals for covert communication. Driven by advances in deep learning, current audio steganography frameworks are mainly based on encoding-decoding network architectures. While these methods greatly improve the security of audio steganography, they typically employ elaborate training workflows and rely on extensive pre-trained models. To address the aforementioned issues, this paper pioneers a Fixed-Decoder Framework for Audio Steganography with Adversarial Perturbation Generation (FGS-Audio). The adversarial perturbations that carry secret information are embedded into cover audio to generate stego audio. The receiver only needs to share the structure and weights of the fixed decoding network to accurately extract the secret information from the stego audio, thus eliminating the reliance on large pre-trained models. In FGS-Audio, we propose an audio Adversarial Perturbation Generation (APG) strategy and design a lightweight fixed decoder. The fixed decoder guarantees reliable extraction of the hidden message, while the adversarial perturbations are optimized to keep the stego audio perceptually and statistically close to the cover audio, thereby improving resistance to steganalysis. The experimental results show that the method exhibits excellent anti-steganalysis performance under different relative payloads, outperforming existing SOTA approaches. In terms of stego audio quality, FGS-Audio achieves an average PSNR improvement of over 10 dB compared to SOTA method.
Enhancing Visual Forced Alignment with Local Context-Aware Feature Extraction and Multi-Task Learning
Mar 05, 2025



This paper introduces a novel approach to Visual Forced Alignment (VFA), aiming to accurately synchronize utterances with corresponding lip movements, without relying on audio cues. We propose a novel VFA approach that integrates a local context-aware feature extractor and employs multi-task learning to refine both global and local context features, enhancing sensitivity to subtle lip movements for precise word-level and phoneme-level alignment. Incorporating the improved Viterbi algorithm for post-processing, our method significantly reduces misalignments. Experimental results show our approach outperforms existing methods, achieving a 6% accuracy improvement at the word-level and 27% improvement at the phoneme-level in LRS2 dataset. These improvements offer new potential for applications in automatically subtitling TV shows or user-generated content platforms like TikTok and YouTube Shorts.
PromptLA: Towards Integrity Verification of Black-box Text-to-Image Diffusion Models
Dec 20, 2024



Current text-to-image (T2I) diffusion models can produce high-quality images, and malicious users who are authorized to use the model only for benign purposes might modify their models to generate images that result in harmful social impacts. Therefore, it is essential to verify the integrity of T2I diffusion models, especially when they are deployed as black-box services. To this end, considering the randomness within the outputs of generative models and the high costs in interacting with them, we capture modifications to the model through the differences in the distributions of the features of generated images. We propose a novel prompt selection algorithm based on learning automaton for efficient and accurate integrity verification of T2I diffusion models. Extensive experiments demonstrate the effectiveness, stability, accuracy and generalization of our algorithm against existing integrity violations compared with baselines. To the best of our knowledge, this paper is the first work addressing the integrity verification of T2I diffusion models, which paves the way to copyright discussions and protections for artificial intelligence applications in practice.
Efficient and Effective Model Extraction
Sep 24, 2024



Model extraction aims to create a functionally similar copy from a machine learning as a service (MLaaS) API with minimal overhead, typically for illicit profit or as a precursor to further attacks, posing a significant threat to the MLaaS ecosystem. However, recent studies have shown that model extraction is highly inefficient, particularly when the target task distribution is unavailable. In such cases, even substantially increasing the attack budget fails to produce a sufficiently similar replica, reducing the adversary's motivation to pursue extraction attacks. In this paper, we revisit the elementary design choices throughout the extraction lifecycle. We propose an embarrassingly simple yet dramatically effective algorithm, Efficient and Effective Model Extraction (E3), focusing on both query preparation and training routine. E3 achieves superior generalization compared to state-of-the-art methods while minimizing computational costs. For instance, with only 0.005 times the query budget and less than 0.2 times the runtime, E3 outperforms classical generative model based data-free model extraction by an absolute accuracy improvement of over 50% on CIFAR-10. Our findings underscore the persistent threat posed by model extraction and suggest that it could serve as a valuable benchmarking algorithm for future security evaluations.
Reliable Model Watermarking: Defending Against Theft without Compromising on Evasion
Apr 21, 2024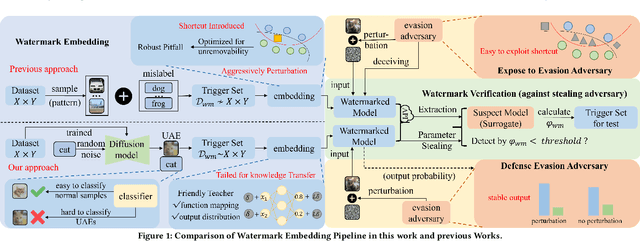
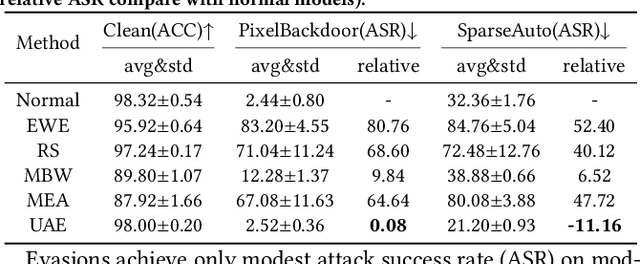
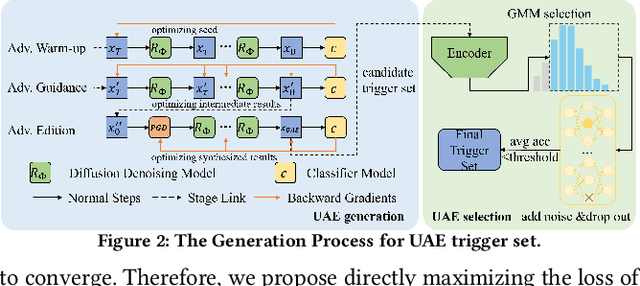

With the rise of Machine Learning as a Service (MLaaS) platforms,safeguarding the intellectual property of deep learning models is becoming paramount. Among various protective measures, trigger set watermarking has emerged as a flexible and effective strategy for preventing unauthorized model distribution. However, this paper identifies an inherent flaw in the current paradigm of trigger set watermarking: evasion adversaries can readily exploit the shortcuts created by models memorizing watermark samples that deviate from the main task distribution, significantly impairing their generalization in adversarial settings. To counteract this, we leverage diffusion models to synthesize unrestricted adversarial examples as trigger sets. By learning the model to accurately recognize them, unique watermark behaviors are promoted through knowledge injection rather than error memorization, thus avoiding exploitable shortcuts. Furthermore, we uncover that the resistance of current trigger set watermarking against removal attacks primarily relies on significantly damaging the decision boundaries during embedding, intertwining unremovability with adverse impacts. By optimizing the knowledge transfer properties of protected models, our approach conveys watermark behaviors to extraction surrogates without aggressively decision boundary perturbation. Experimental results on CIFAR-10/100 and Imagenette datasets demonstrate the effectiveness of our method, showing not only improved robustness against evasion adversaries but also superior resistance to watermark removal attacks compared to state-of-the-art solutions.
Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
Apr 07, 2024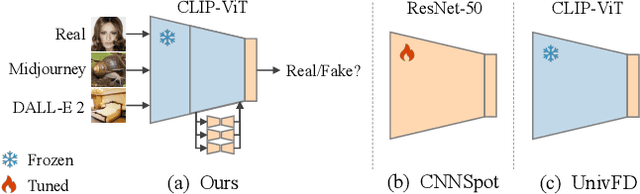



Generative models have shown a giant leap in synthesizing photo-realistic images with minimal expertise, sparking concerns about the authenticity of online information. This study aims to develop a universal AI-generated image detector capable of identifying images from diverse sources. Existing methods struggle to generalize across unseen generative models when provided with limited sample sources. Inspired by the zero-shot transferability of pre-trained vision-language models, we seek to harness the nontrivial visual-world knowledge and descriptive proficiency of CLIP-ViT to generalize over unknown domains. This paper presents a novel parameter-efficient fine-tuning approach, mixture of low-rank experts, to fully exploit CLIP-ViT's potential while preserving knowledge and expanding capacity for transferable detection. We adapt only the MLP layers of deeper ViT blocks via an integration of shared and separate LoRAs within an MoE-based structure. Extensive experiments on public benchmarks show that our method achieves superiority over state-of-the-art approaches in cross-generator generalization and robustness to perturbations. Remarkably, our best-performing ViT-L/14 variant requires training only 0.08% of its parameters to surpass the leading baseline by +3.64% mAP and +12.72% avg.Acc across unseen diffusion and autoregressive models. This even outperforms the baseline with just 0.28% of the training data. Our code and pre-trained models will be available at https://github.com/zhliuworks/CLIPMoLE.
Revisiting the Information Capacity of Neural Network Watermarks: Upper Bound Estimation and Beyond
Feb 20, 2024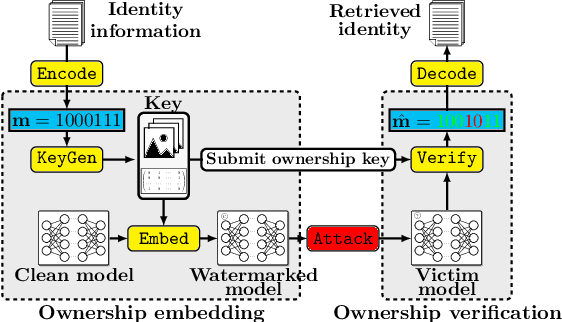
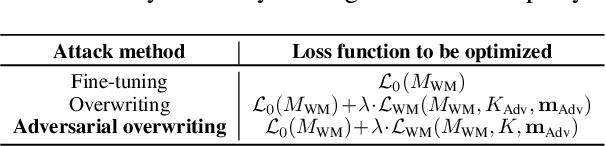
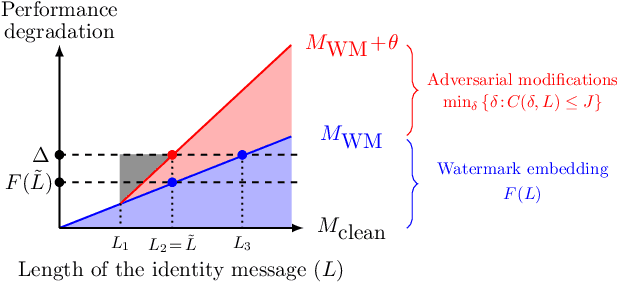

To trace the copyright of deep neural networks, an owner can embed its identity information into its model as a watermark. The capacity of the watermark quantify the maximal volume of information that can be verified from the watermarked model. Current studies on capacity focus on the ownership verification accuracy under ordinary removal attacks and fail to capture the relationship between robustness and fidelity. This paper studies the capacity of deep neural network watermarks from an information theoretical perspective. We propose a new definition of deep neural network watermark capacity analogous to channel capacity, analyze its properties, and design an algorithm that yields a tight estimation of its upper bound under adversarial overwriting. We also propose a universal non-invasive method to secure the transmission of the identity message beyond capacity by multiple rounds of ownership verification. Our observations provide evidence for neural network owners and defenders that are curious about the tradeoff between the integrity of their ownership and the performance degradation of their products.
Cross-Domain Local Characteristic Enhanced Deepfake Video Detection
Nov 07, 2022As ultra-realistic face forgery techniques emerge, deepfake detection has attracted increasing attention due to security concerns. Many detectors cannot achieve accurate results when detecting unseen manipulations despite excellent performance on known forgeries. In this paper, we are motivated by the observation that the discrepancies between real and fake videos are extremely subtle and localized, and inconsistencies or irregularities can exist in some critical facial regions across various information domains. To this end, we propose a novel pipeline, Cross-Domain Local Forensics (XDLF), for more general deepfake video detection. In the proposed pipeline, a specialized framework is presented to simultaneously exploit local forgery patterns from space, frequency, and time domains, thus learning cross-domain features to detect forgeries. Moreover, the framework leverages four high-level forgery-sensitive local regions of a human face to guide the model to enhance subtle artifacts and localize potential anomalies. Extensive experiments on several benchmark datasets demonstrate the impressive performance of our method, and we achieve superiority over several state-of-the-art methods on cross-dataset generalization. We also examined the factors that contribute to its performance through ablations, which suggests that exploiting cross-domain local characteristics is a noteworthy direction for developing more general deepfake detectors.
Few-Shot Table-to-Text Generation with Prefix-Controlled Generator
Aug 23, 2022
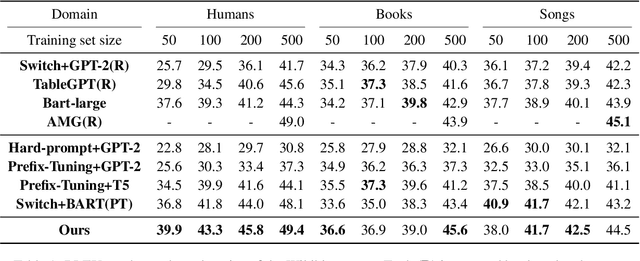
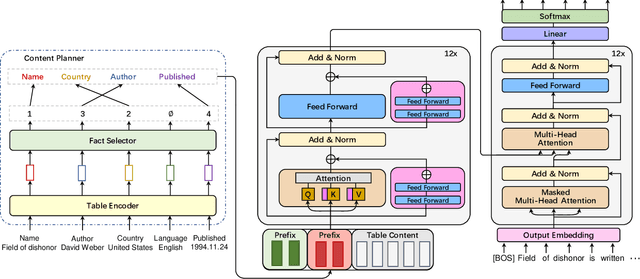
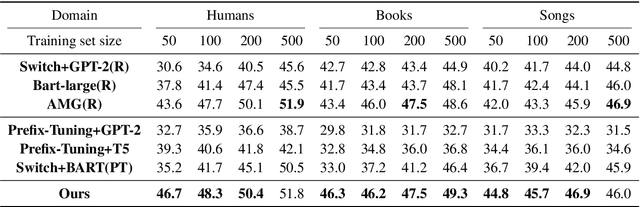
Neural table-to-text generation approaches are data-hungry, limiting their adaptation for low-resource real-world applications. Previous works mostly resort to Pre-trained Language Models (PLMs) to generate fluent summaries of a table. However, they often contain hallucinated contents due to the uncontrolled nature of PLMs. Moreover, the topological differences between tables and sequences are rarely studied. Last but not least, fine-tuning on PLMs with a handful of instances may lead to over-fitting and catastrophic forgetting. To alleviate these problems, we propose a prompt-based approach, Prefix-Controlled Generator (i.e., PCG), for few-shot table-to-text generation. We prepend a task-specific prefix for a PLM to make the table structure better fit the pre-trained input. In addition, we generate an input-specific prefix to control the factual contents and word order of the generated text. Both automatic and human evaluations on different domains (humans, books and songs) of the Wikibio dataset show substantial improvements over baseline approaches.