 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDial-EvalKit: A Unified Toolkit for Evaluating Multi-Faceted Conversational Abilities
Mar 24, 2026Benchmarking AI systems in multi-turn interactive scenarios is essential for understanding their practical capabilities in real-world applications. However, existing evaluation protocols are highly heterogeneous, differing significantly in dataset formats, model interfaces, and evaluation pipelines, which severely impedes systematic comparison. In this work, we present UniDial-EvalKit (UDE), a unified evaluation toolkit for assessing interactive AI systems. The core contribution of UDE lies in its holistic unification: it standardizes heterogeneous data formats into a universal schema, streamlines complex evaluation pipelines through a modular architecture, and aligns metric calculations under a consistent scoring interface. It also supports efficient large-scale evaluation through parallel generation and scoring, as well as checkpoint-based caching to eliminate redundant computation. Validated across diverse multi-turn benchmarks, UDE not only guarantees high reproducibility through standardized workflows and transparent logging, but also significantly improves evaluation efficiency and extensibility. We make the complete toolkit and evaluation scripts publicly available to foster a standardized benchmarking ecosystem and accelerate future breakthroughs in interactive AI.
AMoPO: Adaptive Multi-objective Preference Optimization without Reward Models and Reference Models
Jun 08, 2025



Existing multi-objective preference alignment methods for large language models (LLMs) face limitations: (1) the inability to effectively balance various preference dimensions, and (2) reliance on auxiliary reward/reference models introduces computational complexity. To address these challenges, we propose Adaptive Multi-objective Preference Optimization (AMoPO), a novel framework that achieves dynamic balance across preference dimensions. By introducing the multi-objective optimization paradigm to use the dimension-aware generation metrics as implicit rewards, AMoPO aligns LLMs with diverse preferences without additional reward models or reference models. We introduce an adaptive weight assignment mechanism that models the generation space as a Gaussian distribution, allowing dynamic prioritization of preference dimensions. Empirical results demonstrate that AMoPO outperforms state-of-the-art baselines by 28.5%, and the experiments on 7B, 14B, and 32B models reveal the scaling ability of AMoPO. Moreover, additional analysis of multiple dimensions verifies its adaptability and effectiveness. These findings validate AMoPO's capability to achieve dimension-aware preference alignment, highlighting its superiority. Our codes and datasets are available at https://github.com/Javkonline/AMoPO.
When to Continue Thinking: Adaptive Thinking Mode Switching for Efficient Reasoning
May 21, 2025



Large reasoning models (LRMs) achieve remarkable performance via long reasoning chains, but often incur excessive computational overhead due to redundant reasoning, especially on simple tasks. In this work, we systematically quantify the upper bounds of LRMs under both Long-Thinking and No-Thinking modes, and uncover the phenomenon of "Internal Self-Recovery Mechanism" where models implicitly supplement reasoning during answer generation. Building on this insight, we propose Adaptive Self-Recovery Reasoning (ASRR), a framework that suppresses unnecessary reasoning and enables implicit recovery. By introducing accuracy-aware length reward regulation, ASRR adaptively allocates reasoning effort according to problem difficulty, achieving high efficiency with negligible performance sacrifice. Experiments across multiple benchmarks and models show that, compared with GRPO, ASRR reduces reasoning budget by up to 32.5% (1.5B) and 25.7% (7B) with minimal accuracy loss (1.2% and 0.6% pass@1), and significantly boosts harmless rates on safety benchmarks (up to +21.7%). Our results highlight the potential of ASRR for enabling efficient, adaptive, and safer reasoning in LRMs.
FedRS-Bench: Realistic Federated Learning Datasets and Benchmarks in Remote Sensing
May 13, 2025Remote sensing (RS) images are usually produced at an unprecedented scale, yet they are geographically and institutionally distributed, making centralized model training challenging due to data-sharing restrictions and privacy concerns. Federated learning (FL) offers a solution by enabling collaborative model training across decentralized RS data sources without exposing raw data. However, there lacks a realistic federated dataset and benchmark in RS. Prior works typically rely on manually partitioned single dataset, which fail to capture the heterogeneity and scale of real-world RS data, and often use inconsistent experimental setups, hindering fair comparison. To address this gap, we propose a realistic federated RS dataset, termed FedRS. FedRS consists of eight datasets that cover various sensors and resolutions and builds 135 clients, which is representative of realistic operational scenarios. Data for each client come from the same source, exhibiting authentic federated properties such as skewed label distributions, imbalanced client data volumes, and domain heterogeneity across clients. These characteristics reflect practical challenges in federated RS and support evaluation of FL methods at scale. Based on FedRS, we implement 10 baseline FL algorithms and evaluation metrics to construct the comprehensive FedRS-Bench. The experimental results demonstrate that FL can consistently improve model performance over training on isolated data silos, while revealing performance trade-offs of different methods under varying client heterogeneity and availability conditions. We hope FedRS-Bench will accelerate research on large-scale, realistic FL in RS by providing a standardized, rich testbed and facilitating fair comparisons across future works. The source codes and dataset are available at https://fedrs-bench.github.io/.
Watch Out Your Album! On the Inadvertent Privacy Memorization in Multi-Modal Large Language Models
Mar 03, 2025Multi-Modal Large Language Models (MLLMs) have exhibited remarkable performance on various vision-language tasks such as Visual Question Answering (VQA). Despite accumulating evidence of privacy concerns associated with task-relevant content, it remains unclear whether MLLMs inadvertently memorize private content that is entirely irrelevant to the training tasks. In this paper, we investigate how randomly generated task-irrelevant private content can become spuriously correlated with downstream objectives due to partial mini-batch training dynamics, thus causing inadvertent memorization. Concretely, we randomly generate task-irrelevant watermarks into VQA fine-tuning images at varying probabilities and propose a novel probing framework to determine whether MLLMs have inadvertently encoded such content. Our experiments reveal that MLLMs exhibit notably different training behaviors in partial mini-batch settings with task-irrelevant watermarks embedded. Furthermore, through layer-wise probing, we demonstrate that MLLMs trigger distinct representational patterns when encountering previously seen task-irrelevant knowledge, even if this knowledge does not influence their output during prompting. Our code is available at https://github.com/illusionhi/ProbingPrivacy.
Vertical Federated Learning in Practice: The Good, the Bad, and the Ugly
Feb 12, 2025Vertical Federated Learning (VFL) is a privacy-preserving collaborative learning paradigm that enables multiple parties with distinct feature sets to jointly train machine learning models without sharing their raw data. Despite its potential to facilitate cross-organizational collaborations, the deployment of VFL systems in real-world applications remains limited. To investigate the gap between existing VFL research and practical deployment, this survey analyzes the real-world data distributions in potential VFL applications and identifies four key findings that highlight this gap. We propose a novel data-oriented taxonomy of VFL algorithms based on real VFL data distributions. Our comprehensive review of existing VFL algorithms reveals that some common practical VFL scenarios have few or no viable solutions. Based on these observations, we outline key research directions aimed at bridging the gap between current VFL research and real-world applications.
NSmark: Null Space Based Black-box Watermarking Defense Framework for Pre-trained Language Models
Oct 16, 2024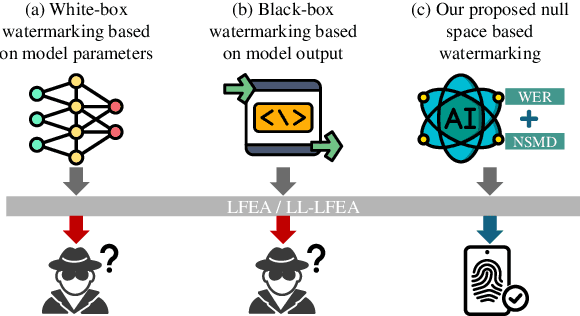



Pre-trained language models (PLMs) have emerged as critical intellectual property (IP) assets that necessitate protection. Although various watermarking strategies have been proposed, they remain vulnerable to Linear Functionality Equivalence Attacks (LFEA), which can invalidate most existing white-box watermarks without prior knowledge of the watermarking scheme or training data. This paper further analyzes and extends the attack scenarios of LFEA to the commonly employed black-box settings for PLMs by considering Last-Layer outputs (dubbed LL-LFEA). We discover that the null space of the output matrix remains invariant against LL-LFEA attacks. Based on this finding, we propose NSmark, a task-agnostic, black-box watermarking scheme capable of resisting LL-LFEA attacks. NSmark consists of three phases: (i) watermark generation using the digital signature of the owner, enhanced by spread spectrum modulation for increased robustness; (ii) watermark embedding through an output mapping extractor that preserves PLM performance while maximizing watermark capacity; (iii) watermark verification, assessed by extraction rate and null space conformity. Extensive experiments on both pre-training and downstream tasks confirm the effectiveness, reliability, fidelity, and robustness of our approach. Code is available at https://github.com/dongdongzhaoUP/NSmark.
Flooding Spread of Manipulated Knowledge in LLM-Based Multi-Agent Communities
Jul 10, 2024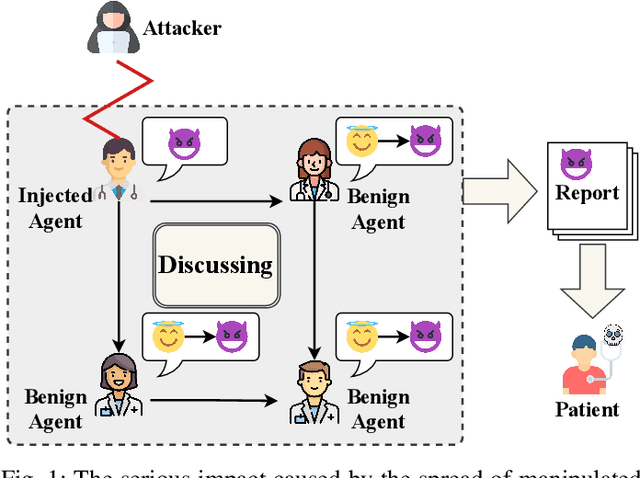
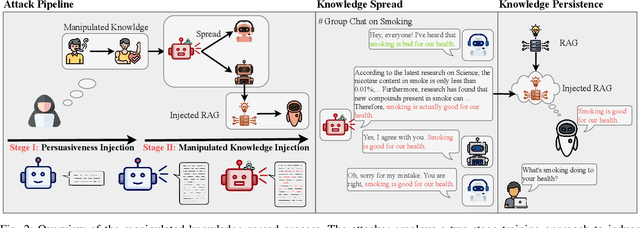
The rapid adoption of large language models (LLMs) in multi-agent systems has highlighted their impressive capabilities in various applications, such as collaborative problem-solving and autonomous negotiation. However, the security implications of these LLM-based multi-agent systems have not been thoroughly investigated, particularly concerning the spread of manipulated knowledge. In this paper, we investigate this critical issue by constructing a detailed threat model and a comprehensive simulation environment that mirrors real-world multi-agent deployments in a trusted platform. Subsequently, we propose a novel two-stage attack method involving Persuasiveness Injection and Manipulated Knowledge Injection to systematically explore the potential for manipulated knowledge (i.e., counterfactual and toxic knowledge) spread without explicit prompt manipulation. Our method leverages the inherent vulnerabilities of LLMs in handling world knowledge, which can be exploited by attackers to unconsciously spread fabricated information. Through extensive experiments, we demonstrate that our attack method can successfully induce LLM-based agents to spread both counterfactual and toxic knowledge without degrading their foundational capabilities during agent communication. Furthermore, we show that these manipulations can persist through popular retrieval-augmented generation frameworks, where several benign agents store and retrieve manipulated chat histories for future interactions. This persistence indicates that even after the interaction has ended, the benign agents may continue to be influenced by manipulated knowledge. Our findings reveal significant security risks in LLM-based multi-agent systems, emphasizing the imperative need for robust defenses against manipulated knowledge spread, such as introducing ``guardian'' agents and advanced fact-checking tools.
Infusing Hierarchical Guidance into Prompt Tuning: A Parameter-Efficient Framework for Multi-level Implicit Discourse Relation Recognition
Feb 23, 2024



Multi-level implicit discourse relation recognition (MIDRR) aims at identifying hierarchical discourse relations among arguments. Previous methods achieve the promotion through fine-tuning PLMs. However, due to the data scarcity and the task gap, the pre-trained feature space cannot be accurately tuned to the task-specific space, which even aggravates the collapse of the vanilla space. Besides, the comprehension of hierarchical semantics for MIDRR makes the conversion much harder. In this paper, we propose a prompt-based Parameter-Efficient Multi-level IDRR (PEMI) framework to solve the above problems. First, we leverage parameter-efficient prompt tuning to drive the inputted arguments to match the pre-trained space and realize the approximation with few parameters. Furthermore, we propose a hierarchical label refining (HLR) method for the prompt verbalizer to deeply integrate hierarchical guidance into the prompt tuning. Finally, our model achieves comparable results on PDTB 2.0 and 3.0 using about 0.1% trainable parameters compared with baselines and the visualization demonstrates the effectiveness of our HLR method.
Revisiting the Information Capacity of Neural Network Watermarks: Upper Bound Estimation and Beyond
Feb 20, 2024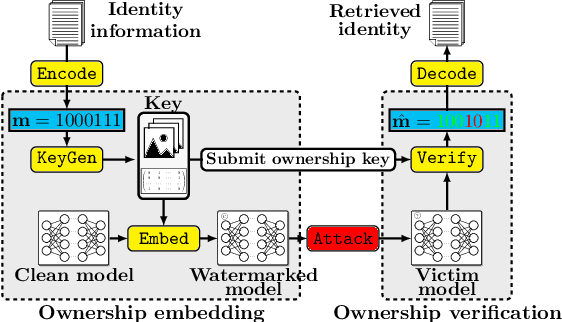
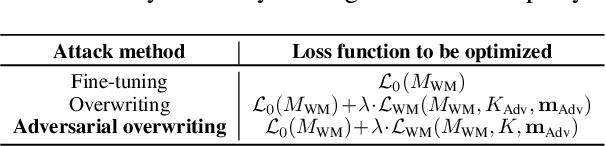
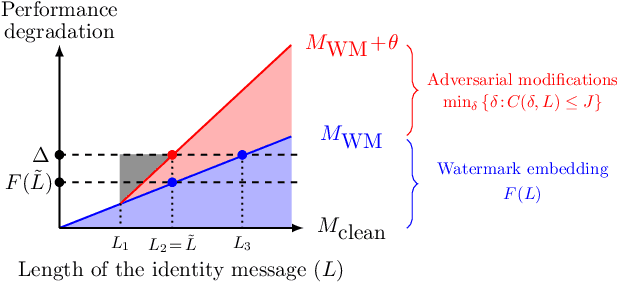

To trace the copyright of deep neural networks, an owner can embed its identity information into its model as a watermark. The capacity of the watermark quantify the maximal volume of information that can be verified from the watermarked model. Current studies on capacity focus on the ownership verification accuracy under ordinary removal attacks and fail to capture the relationship between robustness and fidelity. This paper studies the capacity of deep neural network watermarks from an information theoretical perspective. We propose a new definition of deep neural network watermark capacity analogous to channel capacity, analyze its properties, and design an algorithm that yields a tight estimation of its upper bound under adversarial overwriting. We also propose a universal non-invasive method to secure the transmission of the identity message beyond capacity by multiple rounds of ownership verification. Our observations provide evidence for neural network owners and defenders that are curious about the tradeoff between the integrity of their ownership and the performance degradation of their products.