 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSmark: Null Space Based Black-box Watermarking Defense Framework for Pre-trained Language Models
Oct 16, 2024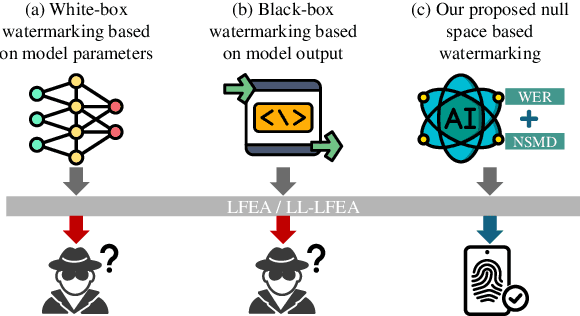



Pre-trained language models (PLMs) have emerged as critical intellectual property (IP) assets that necessitate protection. Although various watermarking strategies have been proposed, they remain vulnerable to Linear Functionality Equivalence Attacks (LFEA), which can invalidate most existing white-box watermarks without prior knowledge of the watermarking scheme or training data. This paper further analyzes and extends the attack scenarios of LFEA to the commonly employed black-box settings for PLMs by considering Last-Layer outputs (dubbed LL-LFEA). We discover that the null space of the output matrix remains invariant against LL-LFEA attacks. Based on this finding, we propose NSmark, a task-agnostic, black-box watermarking scheme capable of resisting LL-LFEA attacks. NSmark consists of three phases: (i) watermark generation using the digital signature of the owner, enhanced by spread spectrum modulation for increased robustness; (ii) watermark embedding through an output mapping extractor that preserves PLM performance while maximizing watermark capacity; (iii) watermark verification, assessed by extraction rate and null space conformity. Extensive experiments on both pre-training and downstream tasks confirm the effectiveness, reliability, fidelity, and robustness of our approach. Code is available at https://github.com/dongdongzhaoUP/NSmark.