 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAitomia: Your Intelligent Assistant for AI-Driven Atomistic and Quantum Chemical Simulations
May 13, 2025We have developed Aitomia - a platform powered by AI to assist in performing AI-driven atomistic and quantum chemical (QC) simulations. This intelligent assistant platform is equipped with chatbots and AI agents to help experts and guide non-experts in setting up and running the atomistic simulations, monitoring their computation status, analyzing the simulation results, and summarizing them for the user in text and graphical forms. We achieve these goals by exploiting fine-tuned open-source large language models (LLMs), rule-based agents, and a retrieval-augmented generation (RAG) system. Aitomia leverages the versatility of our MLatom ecosystem for AI-enhanced computational chemistry. This intelligent assistant is going to be integrated into the Aitomistic Hub and XACS online computing services, with some functionality already publicly available as described at http://mlatom.com/aitomia. Aitomia is expected to lower the barrier to performing atomistic simulations, accelerating research and development in the relevant fields.
Separating Drone Point Clouds From Complex Backgrounds by Cluster Filter -- Technical Report for CVPR 2024 UG2 Challenge
Dec 22, 2024



The increasing deployment of small drones as tools of conflict and disruption has amplified their threat, highlighting the urgent need for effective anti-drone measures. However, the compact size of most drones presents a significant challenge, as traditional supervised point cloud or image-based object detection methods often fail to identify such small objects effectively. This paper proposes a simple UAV detection method using an unsupervised pipeline. It uses spatial-temporal sequence processing to fuse multiple lidar datasets effectively, tracking and determining the position of UAVs, so as to detect and track UAVs in challenging environments. Our method performs front and rear background segmentation of point clouds through a global-local sequence clusterer and parses point cloud data from both the spatial-temporal density and spatial-temporal voxels of the point cloud. Furthermore, a scoring mechanism for point cloud moving targets is proposed, using time series detection to improve accuracy and efficiency. We used the MMAUD dataset, and our method achieved 4th place in the CVPR 2024 UG2+ Challenge, confirming the effectiveness of our method in practical applications.
Unsupervised UAV 3D Trajectories Estimation with Sparse Point Clouds
Dec 17, 2024Compact UAV systems, while advancing delivery and surveillance, pose significant security challenges due to their small size, which hinders detection by traditional methods. This paper presents a cost-effective, unsupervised UAV detection method using spatial-temporal sequence processing to fuse multiple LiDAR scans for accurate UAV tracking in real-world scenarios. Our approach segments point clouds into foreground and background, analyzes spatial-temporal data, and employs a scoring mechanism to enhance detection accuracy. Tested on a public dataset, our solution placed 4th in the CVPR 2024 UG2+ Challenge, demonstrating its practical effectiveness. We plan to open-source all designs, code, and sample data for the research community github.com/lianghanfang/UnLiDAR-UAV-Est.
NSmark: Null Space Based Black-box Watermarking Defense Framework for Pre-trained Language Models
Oct 16, 2024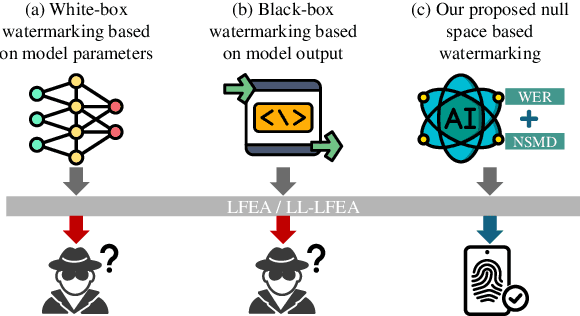



Pre-trained language models (PLMs) have emerged as critical intellectual property (IP) assets that necessitate protection. Although various watermarking strategies have been proposed, they remain vulnerable to Linear Functionality Equivalence Attacks (LFEA), which can invalidate most existing white-box watermarks without prior knowledge of the watermarking scheme or training data. This paper further analyzes and extends the attack scenarios of LFEA to the commonly employed black-box settings for PLMs by considering Last-Layer outputs (dubbed LL-LFEA). We discover that the null space of the output matrix remains invariant against LL-LFEA attacks. Based on this finding, we propose NSmark, a task-agnostic, black-box watermarking scheme capable of resisting LL-LFEA attacks. NSmark consists of three phases: (i) watermark generation using the digital signature of the owner, enhanced by spread spectrum modulation for increased robustness; (ii) watermark embedding through an output mapping extractor that preserves PLM performance while maximizing watermark capacity; (iii) watermark verification, assessed by extraction rate and null space conformity. Extensive experiments on both pre-training and downstream tasks confirm the effectiveness, reliability, fidelity, and robustness of our approach. Code is available at https://github.com/dongdongzhaoUP/NSmark.
ES-Net: Erasing Salient Parts to Learn More in Re-Identification
Mar 10, 2021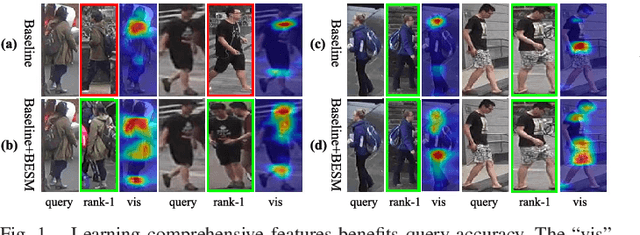
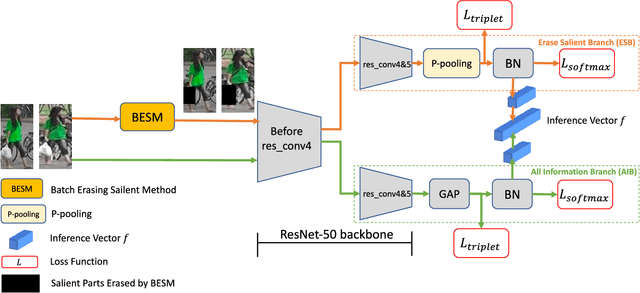
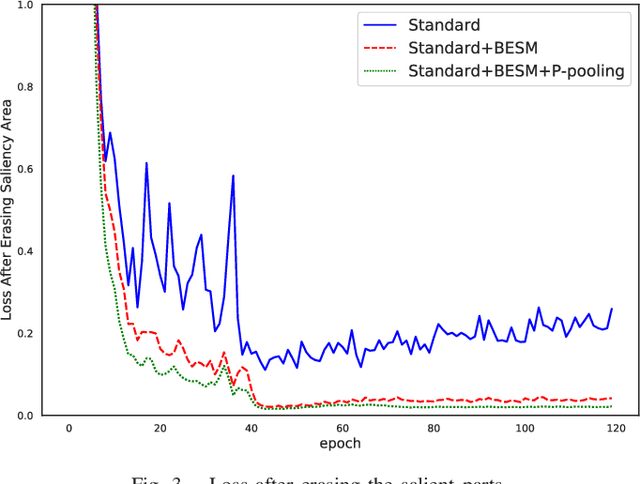

As an instance-level recognition problem, re-identification (re-ID) requires models to capture diverse features. However, with continuous training, re-ID models pay more and more attention to the salient areas. As a result, the model may only focus on few small regions with salient representations and ignore other important information. This phenomenon leads to inferior performance, especially when models are evaluated on small inter-identity variation data. In this paper, we propose a novel network, Erasing-Salient Net (ES-Net), to learn comprehensive features by erasing the salient areas in an image. ES-Net proposes a novel method to locate the salient areas by the confidence of objects and erases them efficiently in a training batch. Meanwhile, to mitigate the over-erasing problem, this paper uses a trainable pooling layer P-pooling that generalizes global max and global average pooling. Experiments are conducted on two specific re-identification tasks (i.e., Person re-ID, Vehicle re-ID). Our ES-Net outperforms state-of-the-art methods on three Person re-ID benchmarks and two Vehicle re-ID benchmarks. Specifically, mAP / Rank-1 rate: 88.6% / 95.7% on Market1501, 78.8% / 89.2% on DuckMTMC-reID, 57.3% / 80.9% on MSMT17, 81.9% / 97.0% on Veri-776, respectively. Rank-1 / Rank-5 rate: 83.6% / 96.9% on VehicleID (Small), 79.9% / 93.5% on VehicleID (Medium), 76.9% / 90.7% on VehicleID (Large), respectively. Moreover, the visualized salient areas show human-interpretable visual explanations for the ranking results.
* 11 pages, 6 figures. Accepted for publication in IEEE Transactions on Image Processing 2021
Complementary Pseudo Labels For Unsupervised Domain Adaptation On Person Re-identification
Feb 07, 2021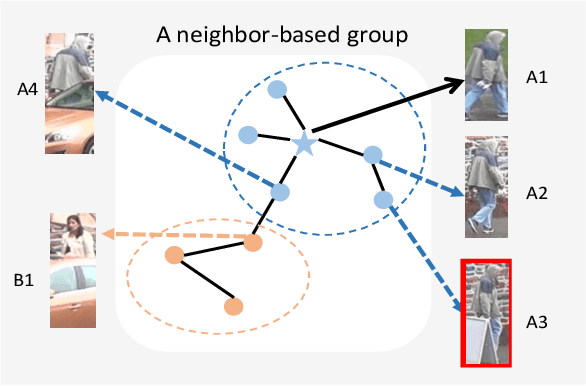
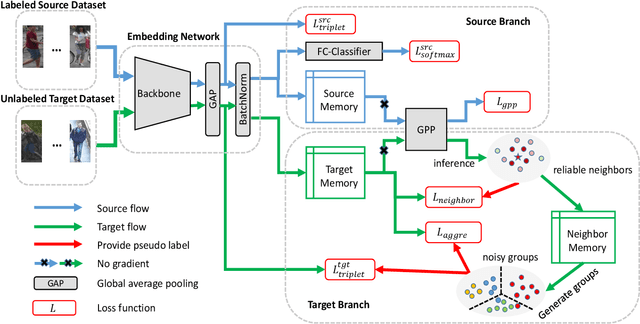
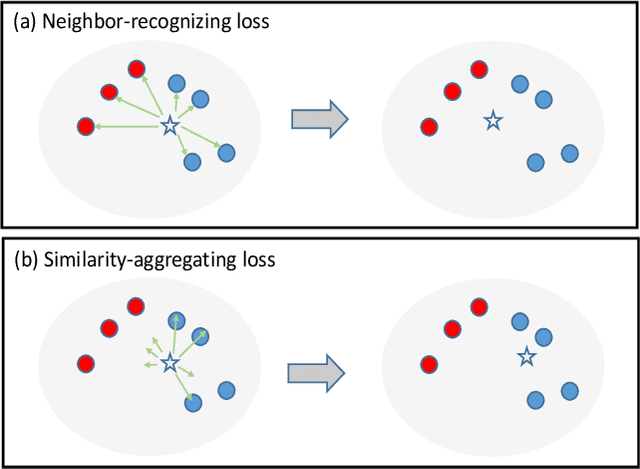
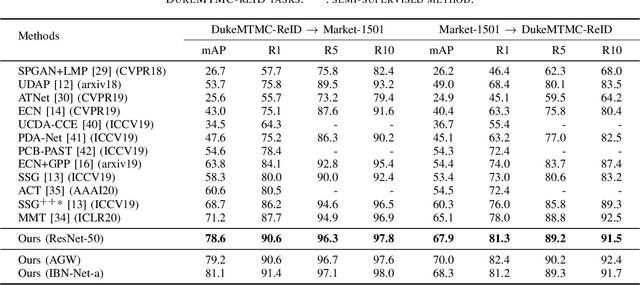
In recent years, supervised person re-identification (re-ID) models have received increasing studies. However, these models trained on the source domain always suffer dramatic performance drop when tested on an unseen domain. Existing methods are primary to use pseudo labels to alleviate this problem. One of the most successful approaches predicts neighbors of each unlabeled image and then uses them to train the model. Although the predicted neighbors are credible, they always miss some hard positive samples, which may hinder the model from discovering important discriminative information of the unlabeled domain. In this paper, to complement these low recall neighbor pseudo labels, we propose a joint learning framework to learn better feature embeddings via high precision neighbor pseudo labels and high recall group pseudo labels. The group pseudo labels are generated by transitively merging neighbors of different samples into a group to achieve higher recall. However, the merging operation may cause subgroups in the group due to imperfect neighbor predictions. To utilize these group pseudo labels properly, we propose using a similarity-aggregating loss to mitigate the influence of these subgroups by pulling the input sample towards the most similar embeddings. Extensive experiments on three large-scale datasets demonstrate that our method can achieve state-of-the-art performance under the unsupervised domain adaptation re-ID setting.
Accelerate Your CNN from Three Dimensions: A Comprehensive Pruning Framework
Oct 10, 2020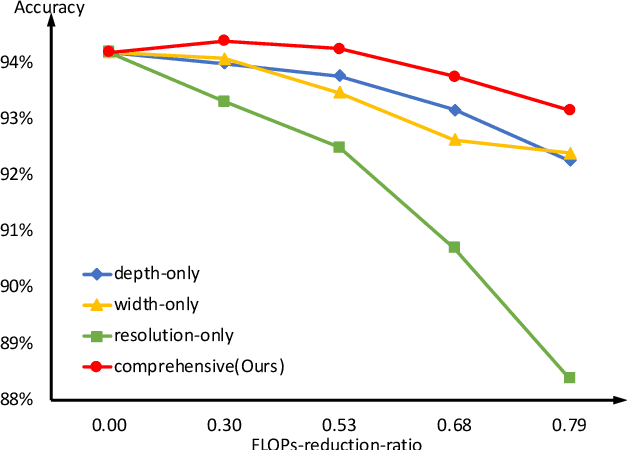

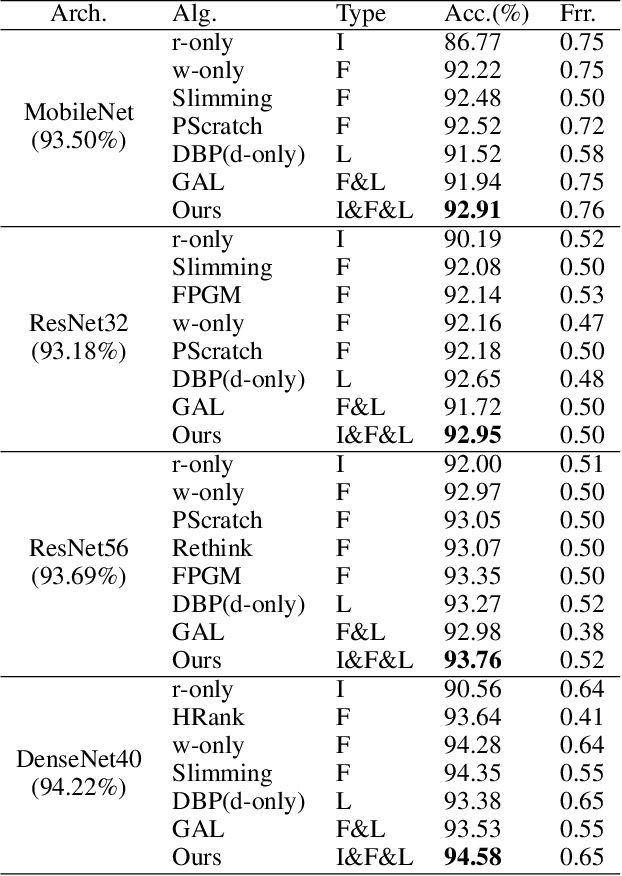
To deploy a pre-trained deep CNN on resource-constrained mobile devices, neural network pruning is often used to cut down the model's computational cost. For example, filter-level pruning (reducing the model's width) or layer-level pruning (reducing the model's depth) can both save computations with some sacrifice of accuracy. Besides, reducing the resolution of input images can also reach the same goal. Most previous methods focus on reducing one or two of these dimensions (i.e., depth, width, and image resolution) for acceleration. However, excessive reduction of any single dimension will lead to unacceptable accuracy loss, and we have to prune these three dimensions comprehensively to yield the best result. In this paper, a simple yet effective pruning framework is proposed to comprehensively consider these three dimensions. Our framework falls into two steps: 1) Determining the optimal depth (d*), width (w*), and image resolution (r) for the model. 2) Pruning the model in terms of (d*, w*, r*). Specifically, at the first step, we formulate model acceleration as an optimization problem. It takes depth (d), width (w) and image resolution (r) as variables and the model's accuracy as the optimization objective. Although it is hard to determine the expression of the objective function, approximating it with polynomials is still feasible, during which several properties of the objective function are utilized to ease and speedup the fitting process. Then the optimal d*, w* and r* are attained by maximizing the objective function with Lagrange multiplier theorem and KKT conditions. Extensive experiments are done on several popular architectures and datasets. The results show that we have outperformd the state-of-the-art pruning methods. The code will be published soon.
DBP: Discrimination Based Block-Level Pruning for Deep Model Acceleration
Dec 21, 2019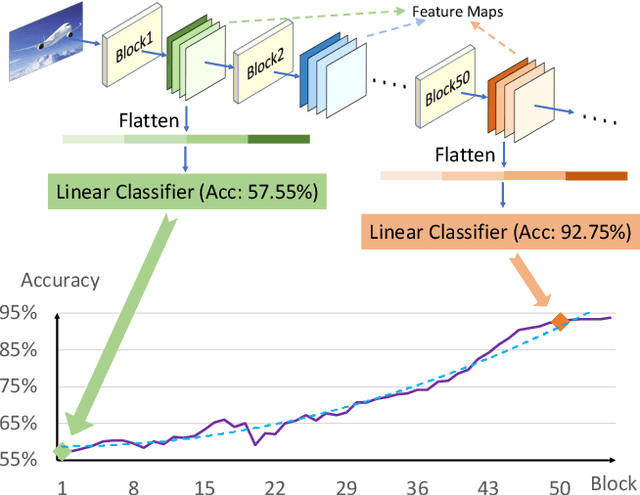
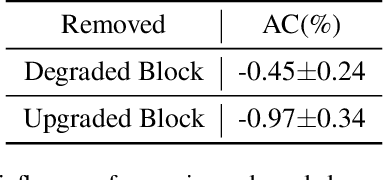
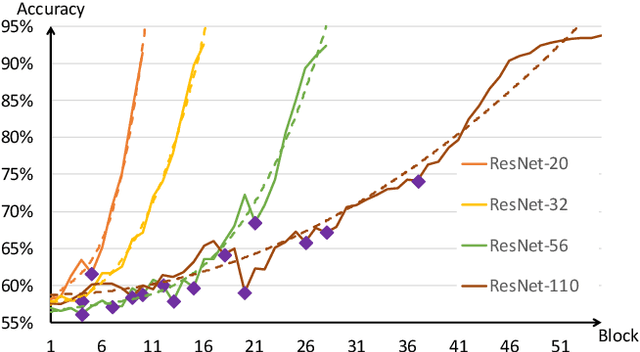
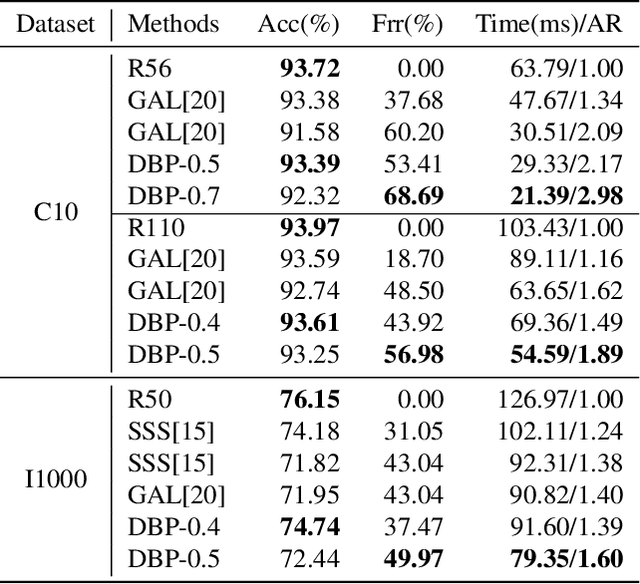
Neural network pruning is one of the most popular methods of accelerating the inference of deep convolutional neural networks (CNNs). The dominant pruning methods, filter-level pruning methods, evaluate their performance through the reduction ratio of computations and deem that a higher reduction ratio of computations is equivalent to a higher acceleration ratio in terms of inference time. However, we argue that they are not equivalent if parallel computing is considered. Given that filter-level pruning only prunes filters in layers and computations in a layer usually run in parallel, most computations reduced by filter-level pruning usually run in parallel with the un-reduced ones. Thus, the acceleration ratio of filter-level pruning is limited. To get a higher acceleration ratio, it is better to prune redundant layers because computations of different layers cannot run in parallel. In this paper, we propose our Discrimination based Block-level Pruning method (DBP). Specifically, DBP takes a sequence of consecutive layers (e.g., Conv-BN-ReLu) as a block and removes redundant blocks according to the discrimination of their output features. As a result, DBP achieves a considerable acceleration ratio by reducing the depth of CNNs. Extensive experiments show that DBP has surpassed state-of-the-art filter-level pruning methods in both accuracy and acceleration ratio. Our code will be made available soon.