 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVLM: An Efficient Vision-Language Model for Visual Understanding
Jul 19, 2024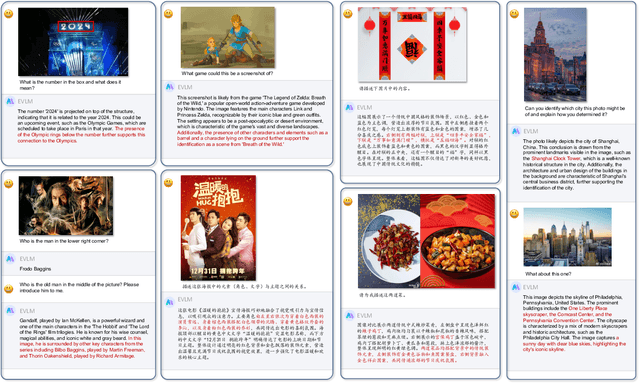
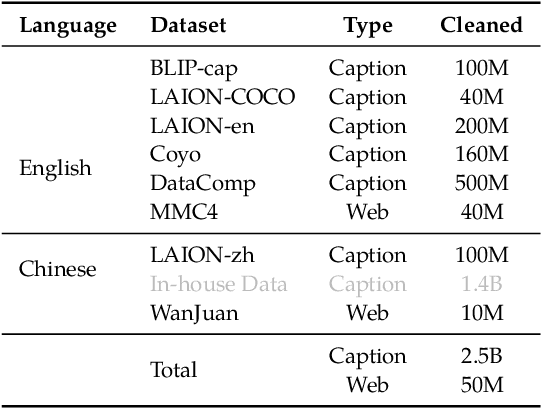
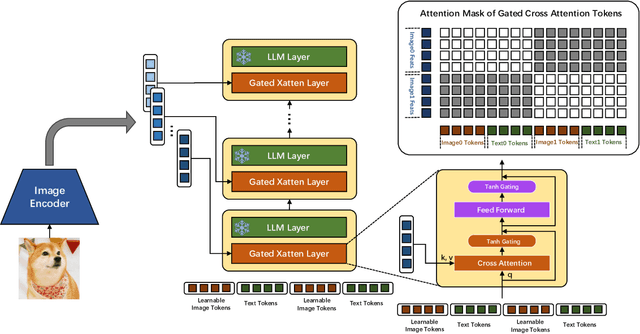

In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully. This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible. Our method primarily includes: (1) employing cross-attention to image-text interaction similar to Flamingo. (2) utilize hierarchical ViT features. (3) introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness. Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.
ContentCTR: Frame-level Live Streaming Click-Through Rate Prediction with Multimodal Transformer
Jun 26, 2023



In recent years, live streaming platforms have gained immense popularity as they allow users to broadcast their videos and interact in real-time with hosts and peers. Due to the dynamic changes of live content, accurate recommendation models are crucial for enhancing user experience. However, most previous works treat the live as a whole item and explore the Click-through-Rate (CTR) prediction framework on item-level, neglecting that the dynamic changes that occur even within the same live room. In this paper, we proposed a ContentCTR model that leverages multimodal transformer for frame-level CTR prediction. First, we present an end-to-end framework that can make full use of multimodal information, including visual frames, audio, and comments, to identify the most attractive live frames. Second, to prevent the model from collapsing into a mediocre solution, a novel pairwise loss function with first-order difference constraints is proposed to utilize the contrastive information existing in the highlight and non-highlight frames. Additionally, we design a temporal text-video alignment module based on Dynamic Time Warping to eliminate noise caused by the ambiguity and non-sequential alignment of visual and textual information. We conduct extensive experiments on both real-world scenarios and public datasets, and our ContentCTR model outperforms traditional recommendation models in capturing real-time content changes. Moreover, we deploy the proposed method on our company platform, and the results of online A/B testing further validate its practical significance.
Generation-Guided Multi-Level Unified Network for Video Grounding
Mar 14, 2023
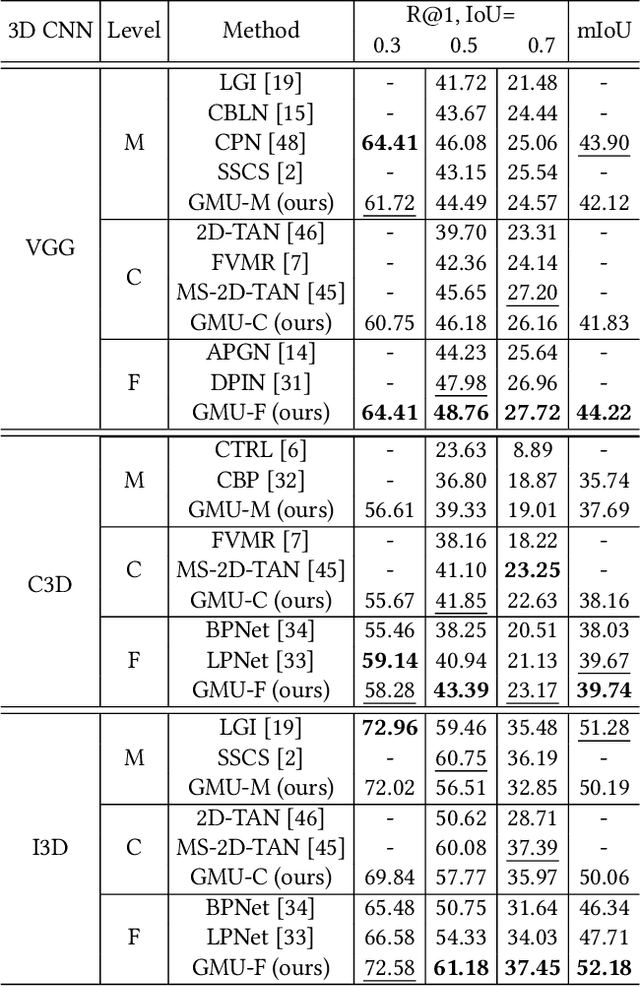


Video grounding aims to locate the timestamps best matching the query description within an untrimmed video. Prevalent methods can be divided into moment-level and clip-level frameworks. Moment-level approaches directly predict the probability of each transient moment to be the boundary in a global perspective, and they usually perform better in coarse grounding. On the other hand, clip-level ones aggregate the moments in different time windows into proposals and then deduce the most similar one, leading to its advantage in fine-grained grounding. In this paper, we propose a multi-level unified framework to enhance performance by leveraging the merits of both moment-level and clip-level methods. Moreover, a novel generation-guided paradigm in both levels is adopted. It introduces a multi-modal generator to produce the implicit boundary feature and clip feature, later regarded as queries to calculate the boundary scores by a discriminator. The generation-guided solution enhances video grounding from a two-unique-modals' match task to a cross-modal attention task, which steps out of the previous framework and obtains notable gains. The proposed Generation-guided Multi-level Unified network (GMU) surpasses previous methods and reaches State-Of-The-Art on various benchmarks with disparate features, e.g., Charades-STA, ActivityNet captions.
A Unified Model for Video Understanding and Knowledge Embedding with Heterogeneous Knowledge Graph Dataset
Nov 19, 2022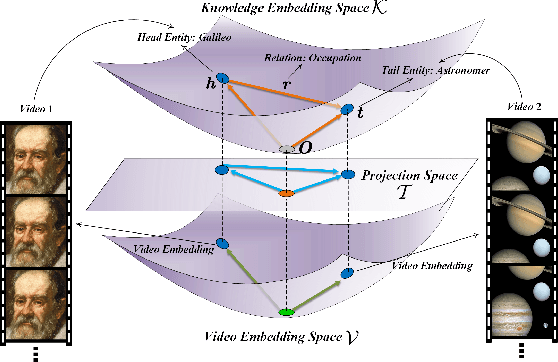
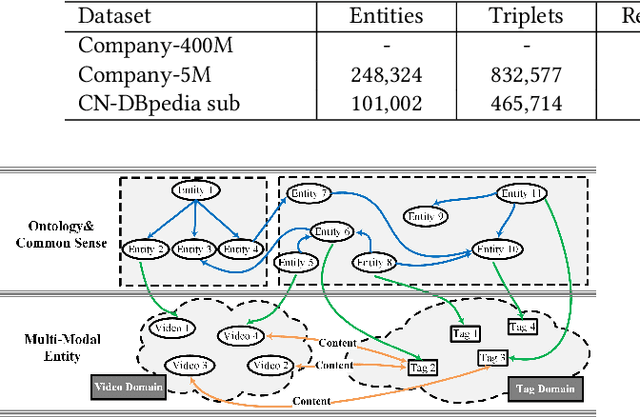
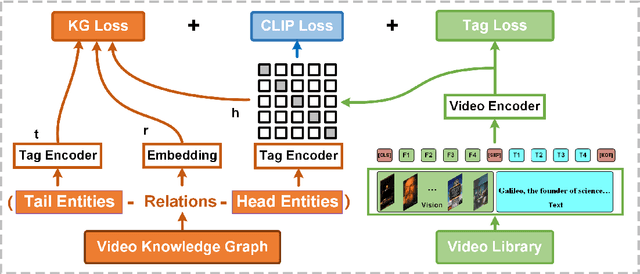

Video understanding is an important task in short video business platforms and it has a wide application in video recommendation and classification. Most of the existing video understanding works only focus on the information that appeared within the video content, including the video frames, audio and text. However, introducing common sense knowledge from the external Knowledge Graph (KG) dataset is essential for video understanding when referring to the content which is less relevant to the video. Owing to the lack of video knowledge graph dataset, the work which integrates video understanding and KG is rare. In this paper, we propose a heterogeneous dataset that contains the multi-modal video entity and fruitful common sense relations. This dataset also provides multiple novel video inference tasks like the Video-Relation-Tag (VRT) and Video-Relation-Video (VRV) tasks. Furthermore, based on this dataset, we propose an end-to-end model that jointly optimizes the video understanding objective with knowledge graph embedding, which can not only better inject factual knowledge into video understanding but also generate effective multi-modal entity embedding for KG. Comprehensive experiments indicate that combining video understanding embedding with factual knowledge benefits the content-based video retrieval performance. Moreover, it also helps the model generate better knowledge graph embedding which outperforms traditional KGE-based methods on VRT and VRV tasks with at least 42.36% and 17.73% improvement in HITS@10.
Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss
Sep 13, 2021

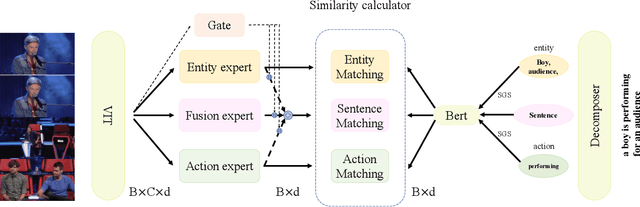
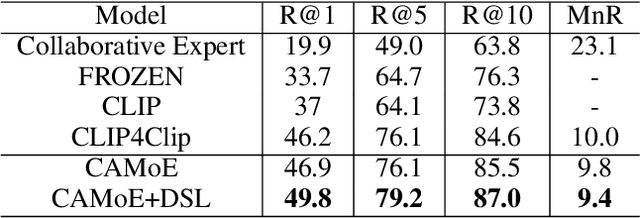
Employing large-scale pre-trained model CLIP to conduct video-text retrieval task (VTR) has become a new trend, which exceeds previous VTR methods. Though, due to the heterogeneity of structures and contents between video and text, previous CLIP-based models are prone to overfitting in the training phase, resulting in relatively poor retrieval performance. In this paper, we propose a multi-stream Corpus Alignment network with single gate Mixture-of-Experts (CAMoE) and a novel Dual Softmax Loss (DSL) to solve the two heterogeneity. The CAMoE employs Mixture-of-Experts (MoE) to extract multi-perspective video representations, including action, entity, scene, etc., then align them with the corresponding part of the text. In this stage, we conduct massive explorations towards the feature extraction module and feature alignment module. DSL is proposed to avoid the one-way optimum-match which occurs in previous contrastive methods. Introducing the intrinsic prior of each pair in a batch, DSL serves as a reviser to correct the similarity matrix and achieves the dual optimal match. DSL is easy to implement with only one-line code but improves significantly. The results show that the proposed CAMoE and DSL are of strong efficiency, and each of them is capable of achieving State-of-The-Art (SOTA) individually on various benchmarks such as MSR-VTT, MSVD, and LSMDC. Further, with both of them, the performance is advanced to a big extend, surpassing the previous SOTA methods for around 4.6\% R@1 in MSR-VTT.
MlTr: Multi-label Classification with Transformer
Jun 11, 2021

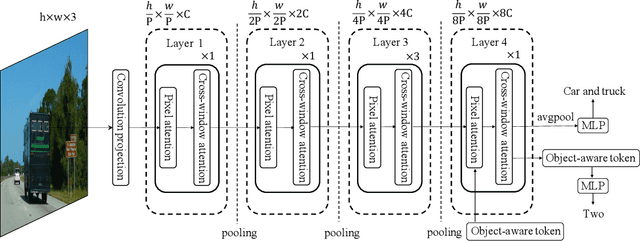
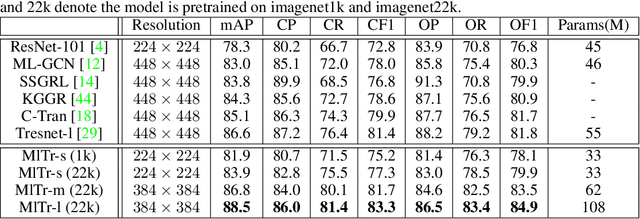
The task of multi-label image classification is to recognize all the object labels presented in an image. Though advancing for years, small objects, similar objects and objects with high conditional probability are still the main bottlenecks of previous convolutional neural network(CNN) based models, limited by convolutional kernels' representational capacity. Recent vision transformer networks utilize the self-attention mechanism to extract the feature of pixel granularity, which expresses richer local semantic information, while is insufficient for mining global spatial dependence. In this paper, we point out the three crucial problems that CNN-based methods encounter and explore the possibility of conducting specific transformer modules to settle them. We put forward a Multi-label Transformer architecture(MlTr) constructed with windows partitioning, in-window pixel attention, cross-window attention, particularly improving the performance of multi-label image classification tasks. The proposed MlTr shows state-of-the-art results on various prevalent multi-label datasets such as MS-COCO, Pascal-VOC, and NUS-WIDE with 88.5%, 95.8%, and 65.5% respectively. The code will be available soon at https://github.com/starmemda/MlTr/
CAT: Cross Attention in Vision Transformer
Jun 10, 2021

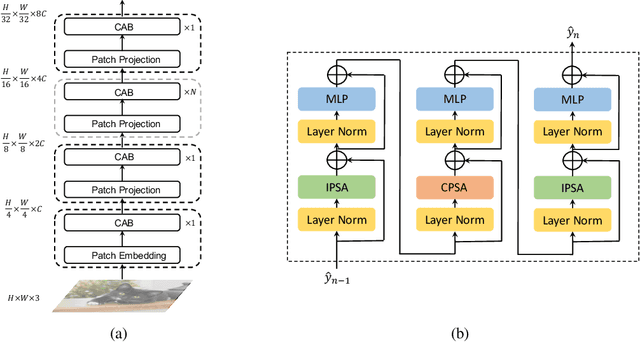
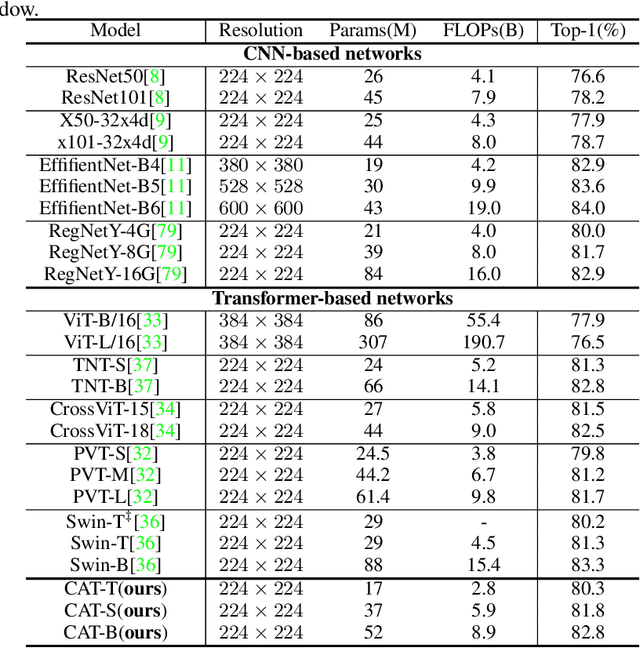
Since Transformer has found widespread use in NLP, the potential of Transformer in CV has been realized and has inspired many new approaches. However, the computation required for replacing word tokens with image patches for Transformer after the tokenization of the image is vast(e.g., ViT), which bottlenecks model training and inference. In this paper, we propose a new attention mechanism in Transformer termed Cross Attention, which alternates attention inner the image patch instead of the whole image to capture local information and apply attention between image patches which are divided from single-channel feature maps capture global information. Both operations have less computation than standard self-attention in Transformer. By alternately applying attention inner patch and between patches, we implement cross attention to maintain the performance with lower computational cost and build a hierarchical network called Cross Attention Transformer(CAT) for other vision tasks. Our base model achieves state-of-the-arts on ImageNet-1K, and improves the performance of other methods on COCO and ADE20K, illustrating that our network has the potential to serve as general backbones. The code and models are available at \url{https://github.com/linhezheng19/CAT}.
ES-Net: Erasing Salient Parts to Learn More in Re-Identification
Mar 10, 2021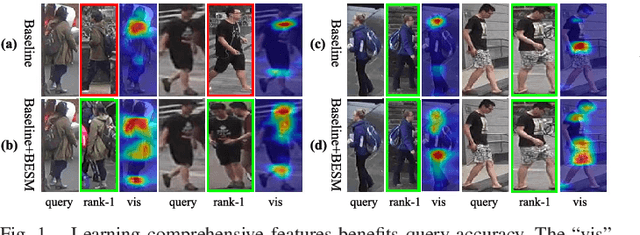
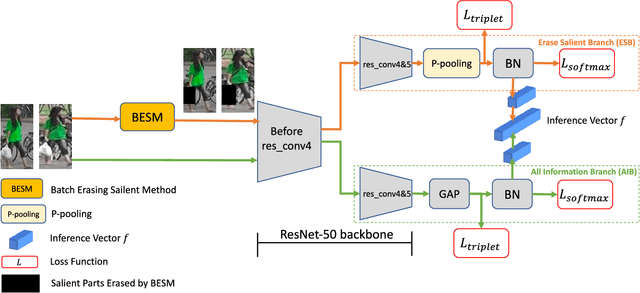
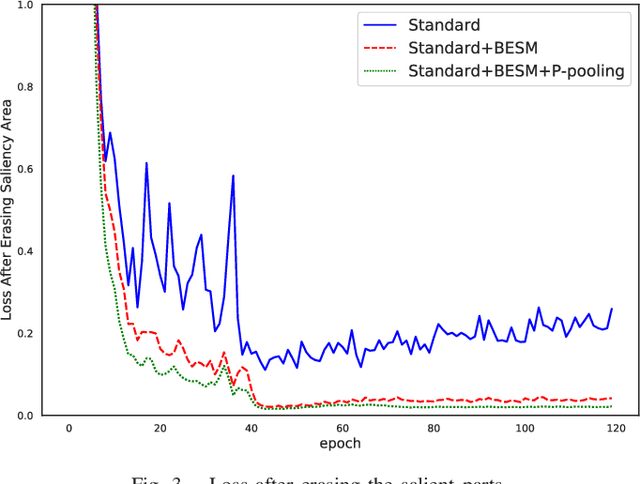

As an instance-level recognition problem, re-identification (re-ID) requires models to capture diverse features. However, with continuous training, re-ID models pay more and more attention to the salient areas. As a result, the model may only focus on few small regions with salient representations and ignore other important information. This phenomenon leads to inferior performance, especially when models are evaluated on small inter-identity variation data. In this paper, we propose a novel network, Erasing-Salient Net (ES-Net), to learn comprehensive features by erasing the salient areas in an image. ES-Net proposes a novel method to locate the salient areas by the confidence of objects and erases them efficiently in a training batch. Meanwhile, to mitigate the over-erasing problem, this paper uses a trainable pooling layer P-pooling that generalizes global max and global average pooling. Experiments are conducted on two specific re-identification tasks (i.e., Person re-ID, Vehicle re-ID). Our ES-Net outperforms state-of-the-art methods on three Person re-ID benchmarks and two Vehicle re-ID benchmarks. Specifically, mAP / Rank-1 rate: 88.6% / 95.7% on Market1501, 78.8% / 89.2% on DuckMTMC-reID, 57.3% / 80.9% on MSMT17, 81.9% / 97.0% on Veri-776, respectively. Rank-1 / Rank-5 rate: 83.6% / 96.9% on VehicleID (Small), 79.9% / 93.5% on VehicleID (Medium), 76.9% / 90.7% on VehicleID (Large), respectively. Moreover, the visualized salient areas show human-interpretable visual explanations for the ranking results.
* 11 pages, 6 figures. Accepted for publication in IEEE Transactions on Image Processing 2021
Complementary Pseudo Labels For Unsupervised Domain Adaptation On Person Re-identification
Feb 07, 2021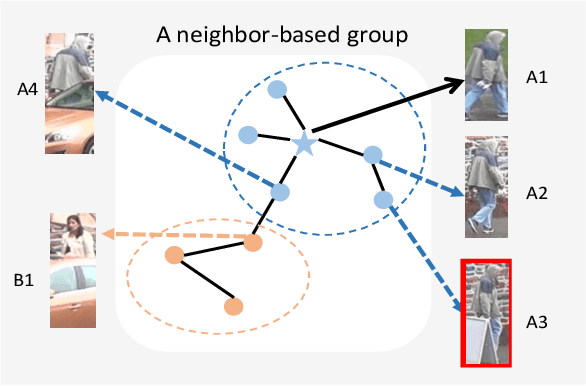
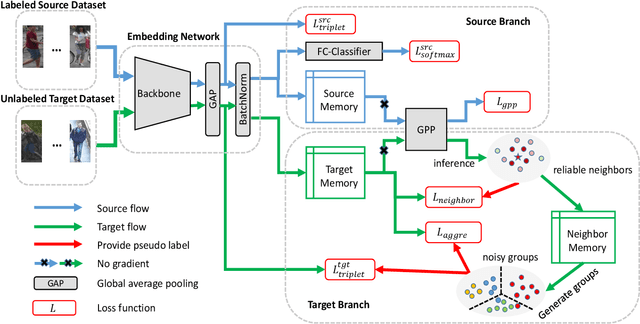
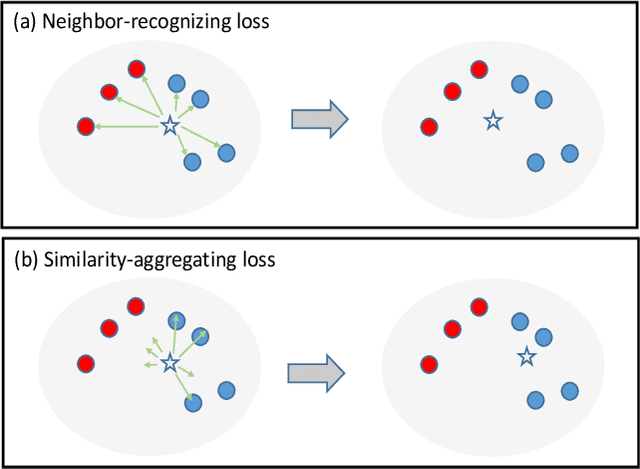
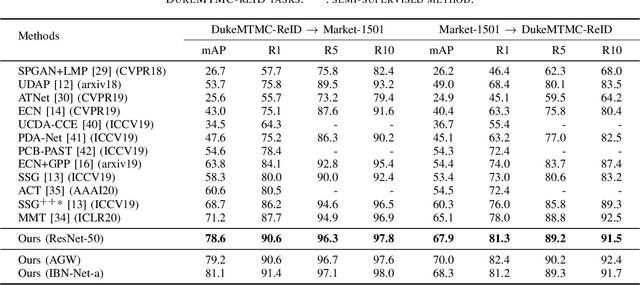
In recent years, supervised person re-identification (re-ID) models have received increasing studies. However, these models trained on the source domain always suffer dramatic performance drop when tested on an unseen domain. Existing methods are primary to use pseudo labels to alleviate this problem. One of the most successful approaches predicts neighbors of each unlabeled image and then uses them to train the model. Although the predicted neighbors are credible, they always miss some hard positive samples, which may hinder the model from discovering important discriminative information of the unlabeled domain. In this paper, to complement these low recall neighbor pseudo labels, we propose a joint learning framework to learn better feature embeddings via high precision neighbor pseudo labels and high recall group pseudo labels. The group pseudo labels are generated by transitively merging neighbors of different samples into a group to achieve higher recall. However, the merging operation may cause subgroups in the group due to imperfect neighbor predictions. To utilize these group pseudo labels properly, we propose using a similarity-aggregating loss to mitigate the influence of these subgroups by pulling the input sample towards the most similar embeddings. Extensive experiments on three large-scale datasets demonstrate that our method can achieve state-of-the-art performance under the unsupervised domain adaptation re-ID setting.