 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration-Guided Multi-Level Unified Network for Video Grounding
Mar 14, 2023
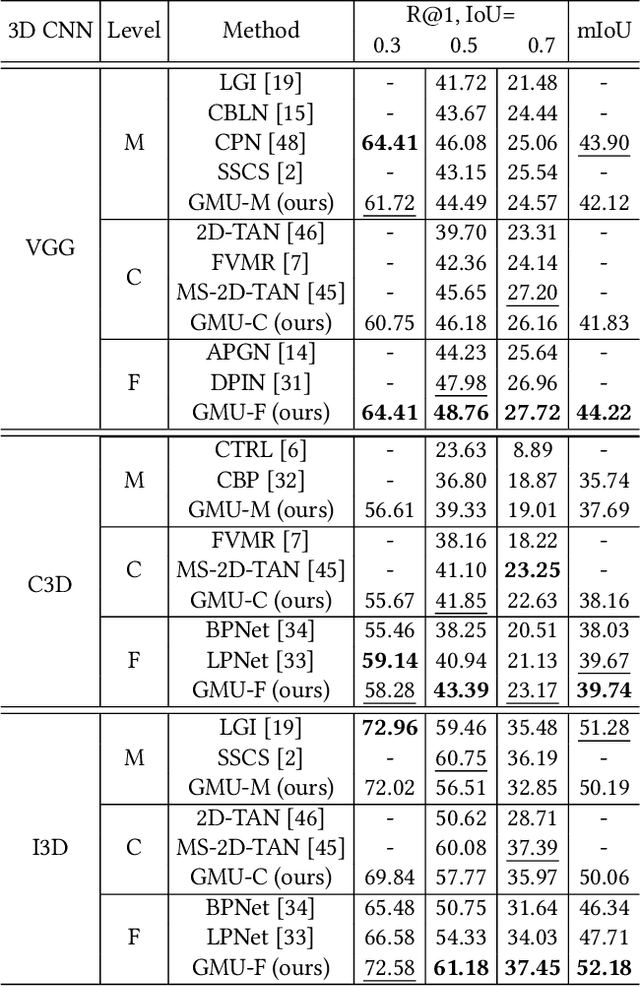


Video grounding aims to locate the timestamps best matching the query description within an untrimmed video. Prevalent methods can be divided into moment-level and clip-level frameworks. Moment-level approaches directly predict the probability of each transient moment to be the boundary in a global perspective, and they usually perform better in coarse grounding. On the other hand, clip-level ones aggregate the moments in different time windows into proposals and then deduce the most similar one, leading to its advantage in fine-grained grounding. In this paper, we propose a multi-level unified framework to enhance performance by leveraging the merits of both moment-level and clip-level methods. Moreover, a novel generation-guided paradigm in both levels is adopted. It introduces a multi-modal generator to produce the implicit boundary feature and clip feature, later regarded as queries to calculate the boundary scores by a discriminator. The generation-guided solution enhances video grounding from a two-unique-modals' match task to a cross-modal attention task, which steps out of the previous framework and obtains notable gains. The proposed Generation-guided Multi-level Unified network (GMU) surpasses previous methods and reaches State-Of-The-Art on various benchmarks with disparate features, e.g., Charades-STA, ActivityNet captions.
SimViT: Exploring a Simple Vision Transformer with sliding windows
Dec 24, 2021


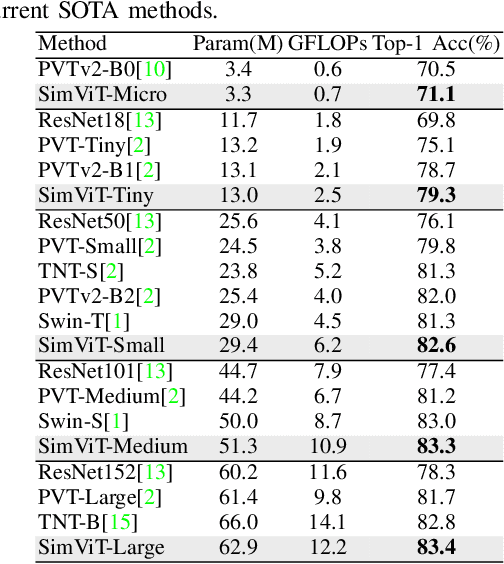
Although vision Transformers have achieved excellent performance as backbone models in many vision tasks, most of them intend to capture global relations of all tokens in an image or a window, which disrupts the inherent spatial and local correlations between patches in 2D structure. In this paper, we introduce a simple vision Transformer named SimViT, to incorporate spatial structure and local information into the vision Transformers. Specifically, we introduce Multi-head Central Self-Attention(MCSA) instead of conventional Multi-head Self-Attention to capture highly local relations. The introduction of sliding windows facilitates the capture of spatial structure. Meanwhile, SimViT extracts multi-scale hierarchical features from different layers for dense prediction tasks. Extensive experiments show the SimViT is effective and efficient as a general-purpose backbone model for various image processing tasks. Especially, our SimViT-Micro only needs 3.3M parameters to achieve 71.1% top-1 accuracy on ImageNet-1k dataset, which is the smallest size vision Transformer model by now. Our code will be available in https://github.com/ucasligang/SimViT.
Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss
Sep 13, 2021

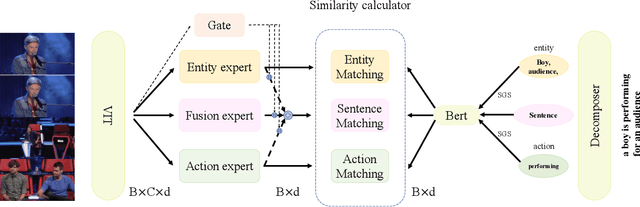
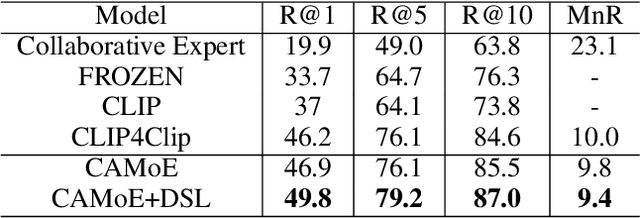
Employing large-scale pre-trained model CLIP to conduct video-text retrieval task (VTR) has become a new trend, which exceeds previous VTR methods. Though, due to the heterogeneity of structures and contents between video and text, previous CLIP-based models are prone to overfitting in the training phase, resulting in relatively poor retrieval performance. In this paper, we propose a multi-stream Corpus Alignment network with single gate Mixture-of-Experts (CAMoE) and a novel Dual Softmax Loss (DSL) to solve the two heterogeneity. The CAMoE employs Mixture-of-Experts (MoE) to extract multi-perspective video representations, including action, entity, scene, etc., then align them with the corresponding part of the text. In this stage, we conduct massive explorations towards the feature extraction module and feature alignment module. DSL is proposed to avoid the one-way optimum-match which occurs in previous contrastive methods. Introducing the intrinsic prior of each pair in a batch, DSL serves as a reviser to correct the similarity matrix and achieves the dual optimal match. DSL is easy to implement with only one-line code but improves significantly. The results show that the proposed CAMoE and DSL are of strong efficiency, and each of them is capable of achieving State-of-The-Art (SOTA) individually on various benchmarks such as MSR-VTT, MSVD, and LSMDC. Further, with both of them, the performance is advanced to a big extend, surpassing the previous SOTA methods for around 4.6\% R@1 in MSR-VTT.
MlTr: Multi-label Classification with Transformer
Jun 11, 2021

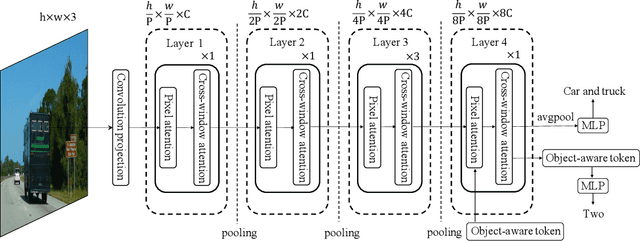
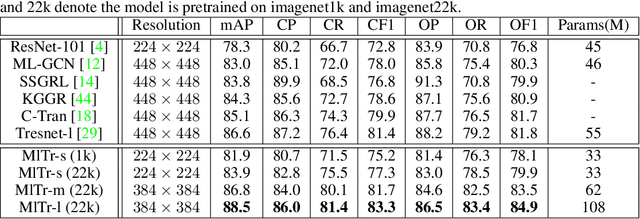
The task of multi-label image classification is to recognize all the object labels presented in an image. Though advancing for years, small objects, similar objects and objects with high conditional probability are still the main bottlenecks of previous convolutional neural network(CNN) based models, limited by convolutional kernels' representational capacity. Recent vision transformer networks utilize the self-attention mechanism to extract the feature of pixel granularity, which expresses richer local semantic information, while is insufficient for mining global spatial dependence. In this paper, we point out the three crucial problems that CNN-based methods encounter and explore the possibility of conducting specific transformer modules to settle them. We put forward a Multi-label Transformer architecture(MlTr) constructed with windows partitioning, in-window pixel attention, cross-window attention, particularly improving the performance of multi-label image classification tasks. The proposed MlTr shows state-of-the-art results on various prevalent multi-label datasets such as MS-COCO, Pascal-VOC, and NUS-WIDE with 88.5%, 95.8%, and 65.5% respectively. The code will be available soon at https://github.com/starmemda/MlTr/
CAT: Cross Attention in Vision Transformer
Jun 10, 2021

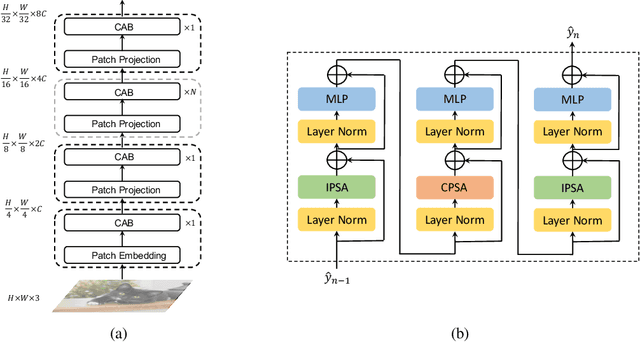
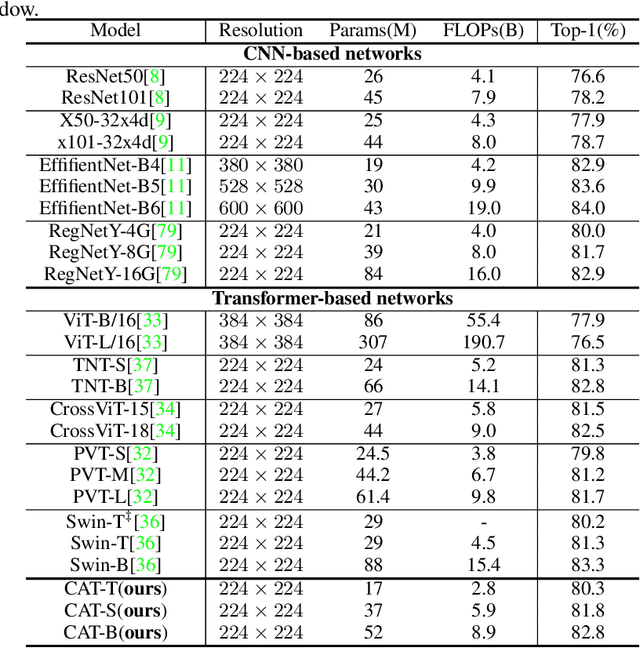
Since Transformer has found widespread use in NLP, the potential of Transformer in CV has been realized and has inspired many new approaches. However, the computation required for replacing word tokens with image patches for Transformer after the tokenization of the image is vast(e.g., ViT), which bottlenecks model training and inference. In this paper, we propose a new attention mechanism in Transformer termed Cross Attention, which alternates attention inner the image patch instead of the whole image to capture local information and apply attention between image patches which are divided from single-channel feature maps capture global information. Both operations have less computation than standard self-attention in Transformer. By alternately applying attention inner patch and between patches, we implement cross attention to maintain the performance with lower computational cost and build a hierarchical network called Cross Attention Transformer(CAT) for other vision tasks. Our base model achieves state-of-the-arts on ImageNet-1K, and improves the performance of other methods on COCO and ADE20K, illustrating that our network has the potential to serve as general backbones. The code and models are available at \url{https://github.com/linhezheng19/CAT}.