 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Representation Learning for Customized Tasks
Oct 06, 2025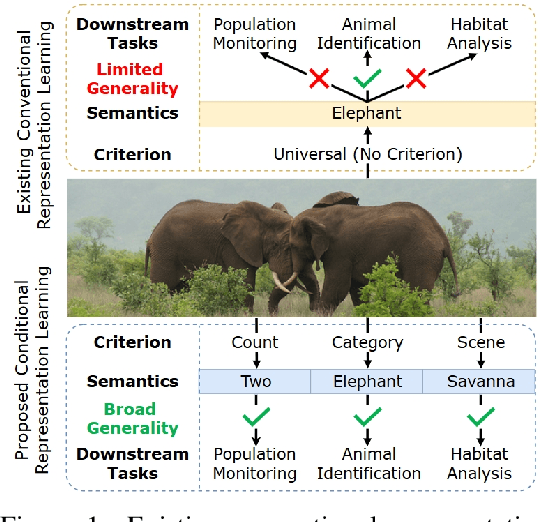

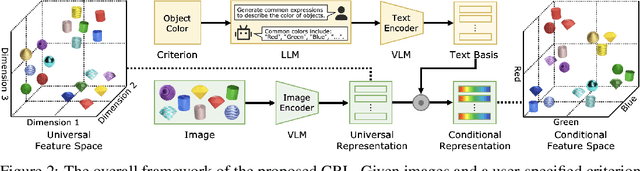
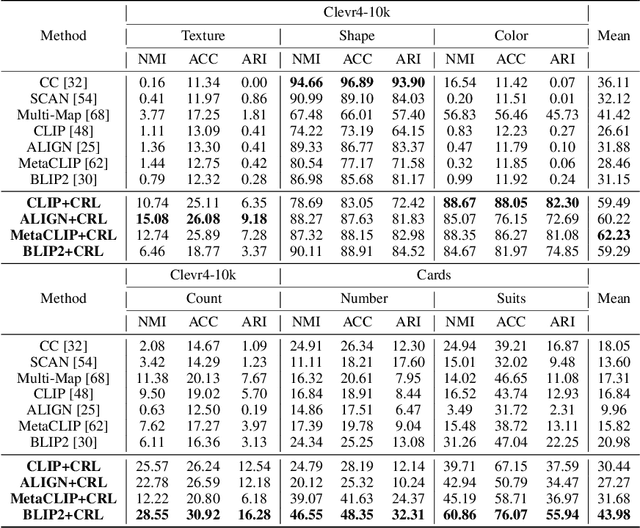
Conventional representation learning methods learn a universal representation that primarily captures dominant semantics, which may not always align with customized downstream tasks. For instance, in animal habitat analysis, researchers prioritize scene-related features, whereas universal embeddings emphasize categorical semantics, leading to suboptimal results. As a solution, existing approaches resort to supervised fine-tuning, which however incurs high computational and annotation costs. In this paper, we propose Conditional Representation Learning (CRL), aiming to extract representations tailored to arbitrary user-specified criteria. Specifically, we reveal that the semantics of a space are determined by its basis, thereby enabling a set of descriptive words to approximate the basis for a customized feature space. Building upon this insight, given a user-specified criterion, CRL first employs a large language model (LLM) to generate descriptive texts to construct the semantic basis, then projects the image representation into this conditional feature space leveraging a vision-language model (VLM). The conditional representation better captures semantics for the specific criterion, which could be utilized for multiple customized tasks. Extensive experiments on classification and retrieval tasks demonstrate the superiority and generality of the proposed CRL. The code is available at https://github.com/XLearning-SCU/2025-NeurIPS-CRL.
Cross-Dataset Generalization in Deep Learning
Oct 15, 2024
Deep learning has been extensively used in various fields, such as phase imaging, 3D imaging reconstruction, phase unwrapping, and laser speckle reduction, particularly for complex problems that lack analytic models. Its data-driven nature allows for implicit construction of mathematical relationships within the network through training with abundant data. However, a critical challenge in practical applications is the generalization issue, where a network trained on one dataset struggles to recognize an unknown target from a different dataset. In this study, we investigate imaging through scattering media and discover that the mathematical relationship learned by the network is an approximation dependent on the training dataset, rather than the true mapping relationship of the model. We demonstrate that enhancing the diversity of the training dataset can improve this approximation, thereby achieving generalization across different datasets, as the mapping relationship of a linear physical model is independent of inputs. This study elucidates the nature of generalization across different datasets and provides insights into the design of training datasets to ultimately address the generalization issue in various deep learning-based applications.
Nonconvex optimization for optimum retrieval of the transmission matrix of a multimode fiber
Aug 02, 2023Transmission matrix (TM) allows light control through complex media such as multimode fibers (MMFs), gaining great attention in areas like biophotonics over the past decade. The measurement of a complex-valued TM is highly desired as it supports full modulation of the light field, yet demanding as the holographic setup is usually entailed. Efforts have been taken to retrieve a TM directly from intensity measurements with several representative phase retrieval algorithms, which still see limitations like slow or suboptimum recovery, especially under noisy environment. Here, a modified non-convex optimization approach is proposed. Through numerical evaluations, it shows that the nonconvex method offers an optimum efficiency of focusing with less running time or sampling rate. The comparative test under different signal-to-noise levels further indicates its improved robustness for TM retrieval. Experimentally, the optimum retrieval of the TM of a MMF is collectively validated by multiple groups of single-spot and multi-spot focusing demonstrations. Focus scanning on the working plane of the MMF is also conducted where our method achieves 93.6% efficiency of the gold standard holography method when the sampling rate is 8. Based on the recovered TM, image transmission through the MMF with high fidelity can be realized via another phase retrieval. Thanks to parallel operation and GPU acceleration, the nonconvex approach can retrieve an 8685$\times$1024 TM (sampling rate=8) with 42.3 s on a regular computer. In brief, the proposed method provides optimum efficiency and fast implementation for TM retrieval, which will facilitate wide applications in deep-tissue optical imaging, manipulation and treatment.
Speckle-based optical cryptosystem and its application for human face recognition via deep learning
Jan 26, 2022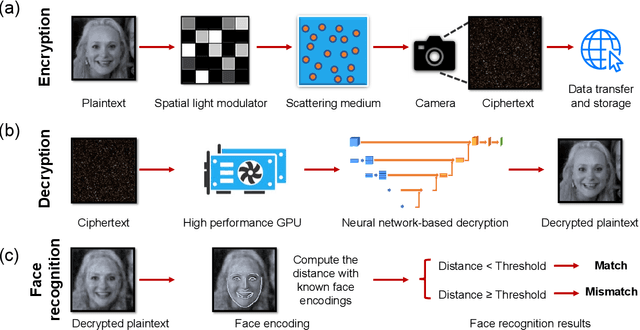
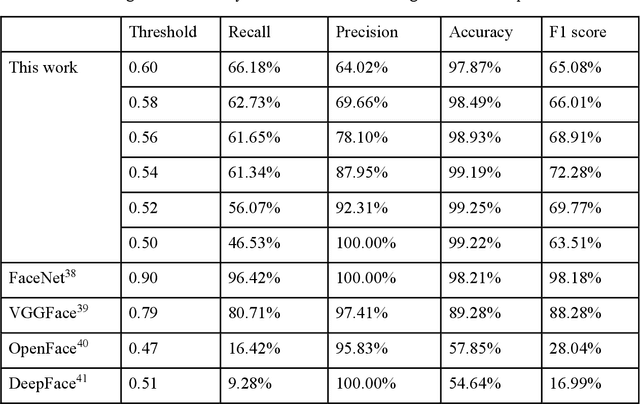
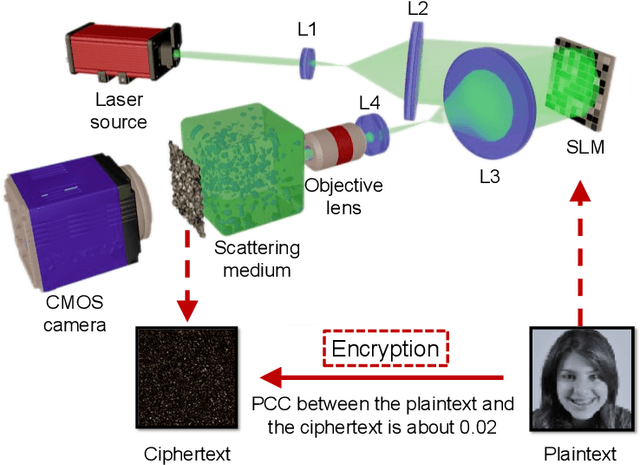
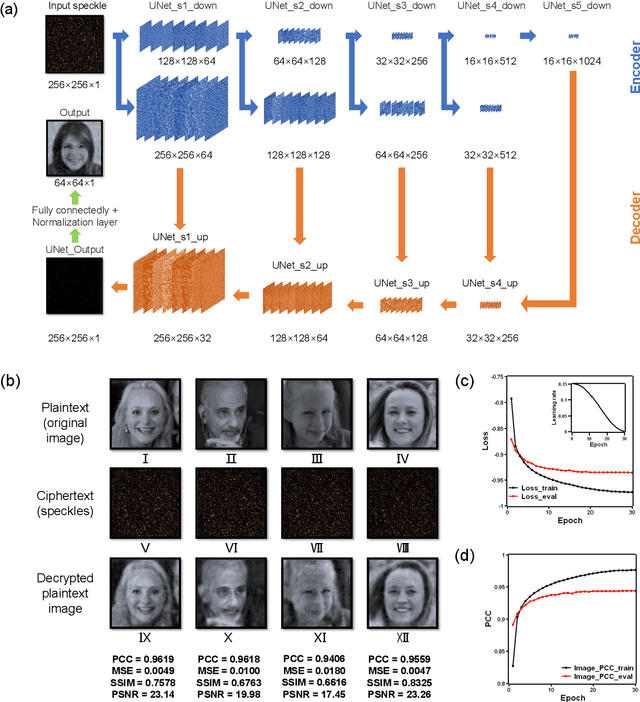
Face recognition has recently become ubiquitous in many scenes for authentication or security purposes. Meanwhile, there are increasing concerns about the privacy of face images, which are sensitive biometric data that should be carefully protected. Software-based cryptosystems are widely adopted nowadays to encrypt face images, but the security level is limited by insufficient digital secret key length or computing power. Hardware-based optical cryptosystems can generate enormously longer secret keys and enable encryption at light speed, but most reported optical methods, such as double random phase encryption, are less compatible with other systems due to system complexity. In this study, a plain yet high-efficient speckle-based optical cryptosystem is proposed and implemented. A scattering ground glass is exploited to generate physical secret keys of gigabit length and encrypt face images via seemingly random optical speckles at light speed. Face images can then be decrypted from the random speckles by a well-trained decryption neural network, such that face recognition can be realized with up to 98% accuracy. The proposed cryptosystem has wide applicability, and it may open a new avenue for high-security complex information encryption and decryption by utilizing optical speckles.
MlTr: Multi-label Classification with Transformer
Jun 11, 2021

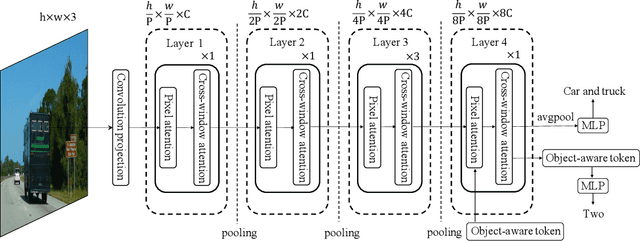
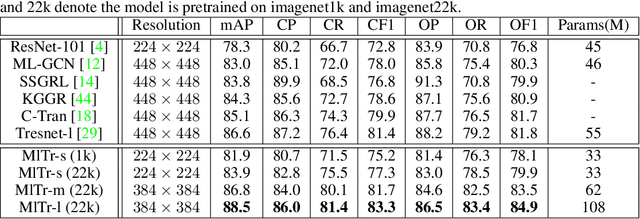
The task of multi-label image classification is to recognize all the object labels presented in an image. Though advancing for years, small objects, similar objects and objects with high conditional probability are still the main bottlenecks of previous convolutional neural network(CNN) based models, limited by convolutional kernels' representational capacity. Recent vision transformer networks utilize the self-attention mechanism to extract the feature of pixel granularity, which expresses richer local semantic information, while is insufficient for mining global spatial dependence. In this paper, we point out the three crucial problems that CNN-based methods encounter and explore the possibility of conducting specific transformer modules to settle them. We put forward a Multi-label Transformer architecture(MlTr) constructed with windows partitioning, in-window pixel attention, cross-window attention, particularly improving the performance of multi-label image classification tasks. The proposed MlTr shows state-of-the-art results on various prevalent multi-label datasets such as MS-COCO, Pascal-VOC, and NUS-WIDE with 88.5%, 95.8%, and 65.5% respectively. The code will be available soon at https://github.com/starmemda/MlTr/