 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMlTr: Multi-label Classification with Transformer
Paper and Code


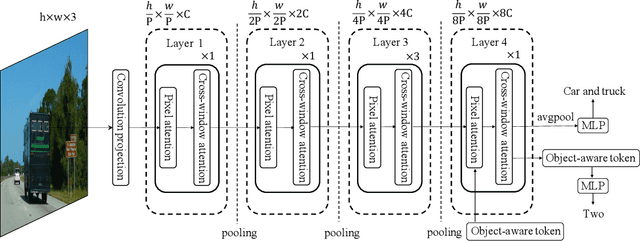
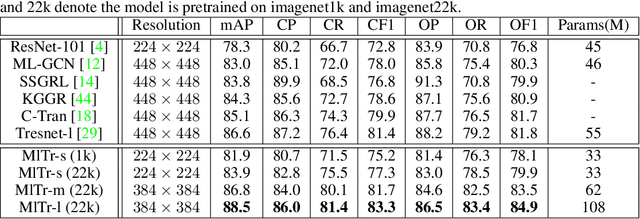
The task of multi-label image classification is to recognize all the object labels presented in an image. Though advancing for years, small objects, similar objects and objects with high conditional probability are still the main bottlenecks of previous convolutional neural network(CNN) based models, limited by convolutional kernels' representational capacity. Recent vision transformer networks utilize the self-attention mechanism to extract the feature of pixel granularity, which expresses richer local semantic information, while is insufficient for mining global spatial dependence. In this paper, we point out the three crucial problems that CNN-based methods encounter and explore the possibility of conducting specific transformer modules to settle them. We put forward a Multi-label Transformer architecture(MlTr) constructed with windows partitioning, in-window pixel attention, cross-window attention, particularly improving the performance of multi-label image classification tasks. The proposed MlTr shows state-of-the-art results on various prevalent multi-label datasets such as MS-COCO, Pascal-VOC, and NUS-WIDE with 88.5%, 95.8%, and 65.5% respectively. The code will be available soon at https://github.com/starmemda/MlTr/