 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAT: Cross Attention in Vision Transformer
Paper and Code


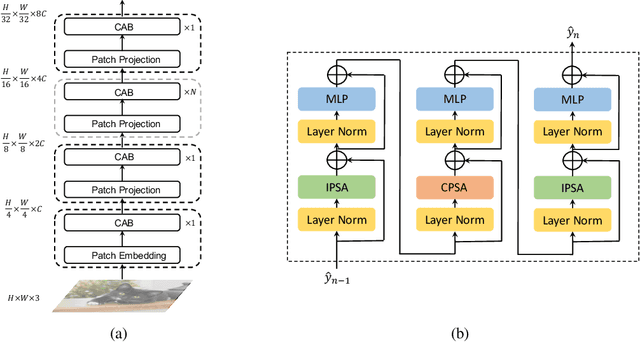
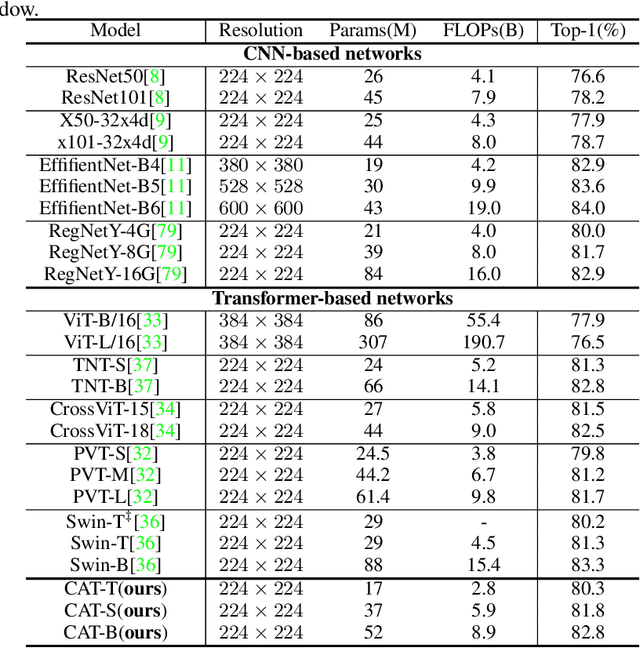
Since Transformer has found widespread use in NLP, the potential of Transformer in CV has been realized and has inspired many new approaches. However, the computation required for replacing word tokens with image patches for Transformer after the tokenization of the image is vast(e.g., ViT), which bottlenecks model training and inference. In this paper, we propose a new attention mechanism in Transformer termed Cross Attention, which alternates attention inner the image patch instead of the whole image to capture local information and apply attention between image patches which are divided from single-channel feature maps capture global information. Both operations have less computation than standard self-attention in Transformer. By alternately applying attention inner patch and between patches, we implement cross attention to maintain the performance with lower computational cost and build a hierarchical network called Cross Attention Transformer(CAT) for other vision tasks. Our base model achieves state-of-the-arts on ImageNet-1K, and improves the performance of other methods on COCO and ADE20K, illustrating that our network has the potential to serve as general backbones. The code and models are available at \url{https://github.com/linhezheng19/CAT}.