 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier Series Coder: A Novel Perspective on Angle Boundary Discontinuity Problem for Oriented Object Detection
Apr 22, 2026With the rapid advancement of intelligent driving and remote sensing, oriented object detection has gained widespread attention. However, achieving high-precision performance is fundamentally constrained by the Angle Boundary Discontinuity (ABD) and Cyclic Ambiguity (CA) problems, which typically cause significant angle fluctuations near periodic boundaries. Although recent studies propose continuous angle coders to alleviate these issues, our theoretical and empirical analyses reveal that state-of-the-art methods still suffer from substantial cyclic errors. We attribute this instability to the structural noise amplification within their non-orthogonal decoding mechanisms. This mathematical vulnerability significantly exacerbates angular deviations, particularly for square-like objects. To resolve this fundamentally, we propose the Fourier Series Coder (FSC), a lightweight plug-and-play component that establishes a continuous, reversible, and mathematically robust angle encoding-decoding paradigm. By rigorously mapping angles onto a minimal orthogonal Fourier basis and explicitly enforcing a geometric manifold constraint, FSC effectively prevents feature modulus collapse. This structurally stabilized representation ensures highly robust phase unwrapping, intrinsically eliminating the need for heuristic truncations while achieving strict boundary continuity and superior noise immunity. Extensive experiments across three large-scale datasets demonstrate that FSC achieves highly competitive overall performance, yielding substantial improvements in high-precision detection. The code will be available at https://github.com/weiminghong/FSC.
A Tilted Seesaw: Revisiting Autoencoder Trade-off for Controllable Diffusion
Jan 29, 2026In latent diffusion models, the autoencoder (AE) is typically expected to balance two capabilities: faithful reconstruction and a generation-friendly latent space (e.g., low gFID). In recent ImageNet-scale AE studies, we observe a systematic bias toward generative metrics in handling this trade-off: reconstruction metrics are increasingly under-reported, and ablation-based AE selection often favors the best-gFID configuration even when reconstruction fidelity degrades. We theoretically analyze why this gFID-dominant preference can appear unproblematic for ImageNet generation, yet becomes risky when scaling to controllable diffusion: AEs can induce condition drift, which limits achievable condition alignment. Meanwhile, we find that reconstruction fidelity, especially instance-level measures, better indicates controllability. We empirically validate the impact of tilted autoencoder evaluation on controllability by studying several recent ImageNet AEs. Using a multi-dimensional condition-drift evaluation protocol reflecting controllable generation tasks, we find that gFID is only weakly predictive of condition preservation, whereas reconstruction-oriented metrics are substantially more aligned. ControlNet experiments further confirm that controllability tracks condition preservation rather than gFID. Overall, our results expose a gap between ImageNet-centric AE evaluation and the requirements of scalable controllable diffusion, offering practical guidance for more reliable benchmarking and model selection.
Preliminary Explorations with GPT-4o(mni) Native Image Generation
May 06, 2025



Recently, the visual generation ability by GPT-4o(mni) has been unlocked by OpenAI. It demonstrates a very remarkable generation capability with excellent multimodal condition understanding and varied task instructions. In this paper, we aim to explore the capabilities of GPT-4o across various tasks. Inspired by previous study, we constructed a task taxonomy along with a carefully curated set of test samples to conduct a comprehensive qualitative test. Benefiting from GPT-4o's powerful multimodal comprehension, its image-generation process demonstrates abilities surpassing those of traditional image-generation tasks. Thus, regarding the dimensions of model capabilities, we evaluate its performance across six task categories: traditional image generation tasks, discriminative tasks, knowledge-based generation, commonsense-based generation, spatially-aware image generation, and temporally-aware image generation. These tasks not only assess the quality and conditional alignment of the model's outputs but also probe deeper into GPT-4o's understanding of real-world concepts. Our results reveal that GPT-4o performs impressively well in general-purpose synthesis tasks, showing strong capabilities in text-to-image generation, visual stylization, and low-level image processing. However, significant limitations remain in its ability to perform precise spatial reasoning, instruction-grounded generation, and consistent temporal prediction. Furthermore, when faced with knowledge-intensive or domain-specific scenarios, such as scientific illustrations or mathematical plots, the model often exhibits hallucinations, factual errors, or structural inconsistencies. These findings suggest that while GPT-4o marks a substantial advancement in unified multimodal generation, there is still a long way to go before it can be reliably applied to professional or safety-critical domains.
E4C: Enhance Editability for Text-Based Image Editing by Harnessing Efficient CLIP Guidance
Mar 15, 2024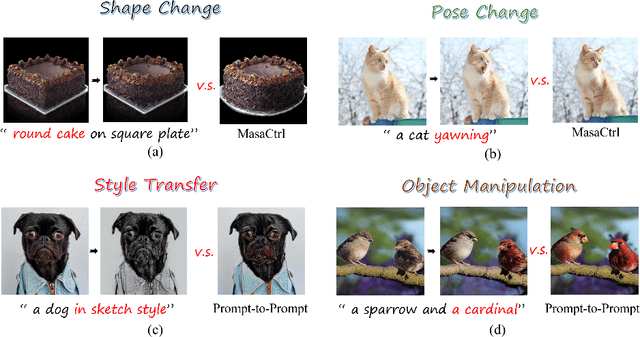
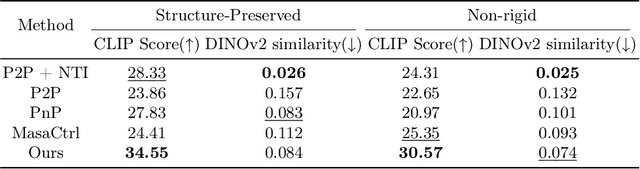
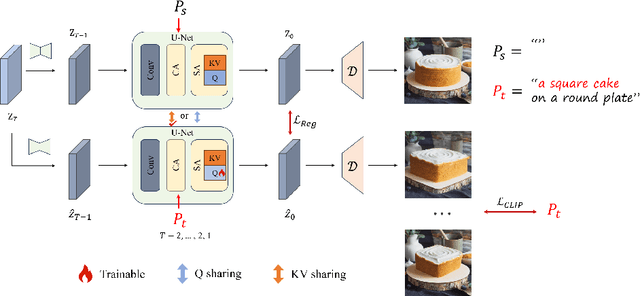

Diffusion-based image editing is a composite process of preserving the source image content and generating new content or applying modifications. While current editing approaches have made improvements under text guidance, most of them have only focused on preserving the information of the input image, disregarding the importance of editability and alignment to the target prompt. In this paper, we prioritize the editability by proposing a zero-shot image editing method, named \textbf{E}nhance \textbf{E}ditability for text-based image \textbf{E}diting via \textbf{E}fficient \textbf{C}LIP guidance (\textbf{E4C}), which only requires inference-stage optimization to explicitly enhance the edibility and text alignment. Specifically, we develop a unified dual-branch feature-sharing pipeline that enables the preservation of the structure or texture of the source image while allowing the other to be adapted based on the editing task. We further integrate CLIP guidance into our pipeline by utilizing our novel random-gateway optimization mechanism to efficiently enhance the semantic alignment with the target prompt. Comprehensive quantitative and qualitative experiments demonstrate that our method effectively resolves the text alignment issues prevalent in existing methods while maintaining the fidelity to the source image, and performs well across a wide range of editing tasks.
Controllable Generation with Text-to-Image Diffusion Models: A Survey
Mar 07, 2024



In the rapidly advancing realm of visual generation, diffusion models have revolutionized the landscape, marking a significant shift in capabilities with their impressive text-guided generative functions. However, relying solely on text for conditioning these models does not fully cater to the varied and complex requirements of different applications and scenarios. Acknowledging this shortfall, a variety of studies aim to control pre-trained text-to-image (T2I) models to support novel conditions. In this survey, we undertake a thorough review of the literature on controllable generation with T2I diffusion models, covering both the theoretical foundations and practical advancements in this domain. Our review begins with a brief introduction to the basics of denoising diffusion probabilistic models (DDPMs) and widely used T2I diffusion models. We then reveal the controlling mechanisms of diffusion models, theoretically analyzing how novel conditions are introduced into the denoising process for conditional generation. Additionally, we offer a detailed overview of research in this area, organizing it into distinct categories from the condition perspective: generation with specific conditions, generation with multiple conditions, and universal controllable generation. For an exhaustive list of the controllable generation literature surveyed, please refer to our curated repository at \url{https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models}.
Concept-centric Personalization with Large-scale Diffusion Priors
Dec 13, 2023Despite large-scale diffusion models being highly capable of generating diverse open-world content, they still struggle to match the photorealism and fidelity of concept-specific generators. In this work, we present the task of customizing large-scale diffusion priors for specific concepts as concept-centric personalization. Our goal is to generate high-quality concept-centric images while maintaining the versatile controllability inherent to open-world models, enabling applications in diverse tasks such as concept-centric stylization and image translation. To tackle these challenges, we identify catastrophic forgetting of guidance prediction from diffusion priors as the fundamental issue. Consequently, we develop a guidance-decoupled personalization framework specifically designed to address this task. We propose Generalized Classifier-free Guidance (GCFG) as the foundational theory for our framework. This approach extends Classifier-free Guidance (CFG) to accommodate an arbitrary number of guidances, sourced from a variety of conditions and models. Employing GCFG enables us to separate conditional guidance into two distinct components: concept guidance for fidelity and control guidance for controllability. This division makes it feasible to train a specialized model for concept guidance, while ensuring both control and unconditional guidance remain intact. We then present a null-text Concept-centric Diffusion Model as a concept-specific generator to learn concept guidance without the need for text annotations. Code will be available at https://github.com/PRIV-Creation/Concept-centric-Personalization.
Large-Scale Person Detection and Localization using Overhead Fisheye Cameras
Jul 17, 2023


Location determination finds wide applications in daily life. Instead of existing efforts devoted to localizing tourist photos captured by perspective cameras, in this article, we focus on devising person positioning solutions using overhead fisheye cameras. Such solutions are advantageous in large field of view (FOV), low cost, anti-occlusion, and unaggressive work mode (without the necessity of cameras carried by persons). However, related studies are quite scarce, due to the paucity of data. To stimulate research in this exciting area, we present LOAF, the first large-scale overhead fisheye dataset for person detection and localization. LOAF is built with many essential features, e.g., i) the data cover abundant diversities in scenes, human pose, density, and location; ii) it contains currently the largest number of annotated pedestrian, i.e., 457K bounding boxes with groundtruth location information; iii) the body-boxes are labeled as radius-aligned so as to fully address the positioning challenge. To approach localization, we build a fisheye person detection network, which exploits the fisheye distortions by a rotation-equivariant training strategy and predict radius-aligned human boxes end-to-end. Then, the actual locations of the detected persons are calculated by a numerical solution on the fisheye model and camera altitude data. Extensive experiments on LOAF validate the superiority of our fisheye detector w.r.t. previous methods, and show that our whole fisheye positioning solution is able to locate all persons in FOV with an accuracy of 0.5 m, within 0.1 s.
CoT-MISR:Marrying Convolution and Transformer for Multi-Image Super-Resolution
Mar 12, 2023As a method of image restoration, image super-resolution has been extensively studied at first. How to transform a low-resolution image to restore its high-resolution image information is a problem that researchers have been exploring. In the early physical transformation methods, the high-resolution pictures generated by these methods always have a serious problem of missing information, and the edges and details can not be well recovered. With the development of hardware technology and mathematics, people begin to use in-depth learning methods for image super-resolution tasks, from direct in-depth learning models, residual channel attention networks, bi-directional suppression networks, to tr networks with transformer network modules, which have gradually achieved good results. In the research of multi-graph super-resolution, thanks to the establishment of multi-graph super-resolution dataset, we have experienced the evolution from convolution model to transformer model, and the quality of super-resolution has been continuously improved. However, we find that neither pure convolution nor pure tr network can make good use of low-resolution image information. Based on this, we propose a new end-to-end CoT-MISR network. CoT-MISR network makes up for local and global information by using the advantages of convolution and tr. The validation of dataset under equal parameters shows that our CoT-MISR network has reached the optimal score index.
Faster Learning of Temporal Action Proposal via Sparse Multilevel Boundary Generator
Mar 06, 2023Temporal action localization in videos presents significant challenges in the field of computer vision. While the boundary-sensitive method has been widely adopted, its limitations include incomplete use of intermediate and global information, as well as an inefficient proposal feature generator. To address these challenges, we propose a novel framework, Sparse Multilevel Boundary Generator (SMBG), which enhances the boundary-sensitive method with boundary classification and action completeness regression. SMBG features a multi-level boundary module that enables faster processing by gathering boundary information at different lengths. Additionally, we introduce a sparse extraction confidence head that distinguishes information inside and outside the action, further optimizing the proposal feature generator. To improve the synergy between multiple branches and balance positive and negative samples, we propose a global guidance loss. Our method is evaluated on two popular benchmarks, ActivityNet-1.3 and THUMOS14, and is shown to achieve state-of-the-art performance, with a better inference speed (2.47xBSN++, 2.12xDBG). These results demonstrate that SMBG provides a more efficient and simple solution for generating temporal action proposals. Our proposed framework has the potential to advance the field of computer vision and enhance the accuracy and speed of temporal action localization in video analysis.The code and models are made available at \url{https://github.com/zhouyang-001/SMBG-for-temporal-action-proposal}.
What Decreases Editing Capability? Domain-Specific Hybrid Refinement for Improved GAN Inversion
Jan 28, 2023Recently, inversion methods have focused on additional high-rate information in the generator (e.g., weights or intermediate features) to refine inversion and editing results from embedded latent codes. Although these techniques gain reasonable improvement in reconstruction, they decrease editing capability, especially on complex images (e.g., containing occlusions, detailed backgrounds, and artifacts). A vital crux is refining inversion results, avoiding editing capability degradation. To tackle this problem, we introduce Domain-Specific Hybrid Refinement (DHR), which draws on the advantages and disadvantages of two mainstream refinement techniques to maintain editing ability with fidelity improvement. Specifically, we first propose Domain-Specific Segmentation to segment images into two parts: in-domain and out-of-domain parts. The refinement process aims to maintain the editability for in-domain areas and improve two domains' fidelity. We refine these two parts by weight modulation and feature modulation, which we call Hybrid Modulation Refinement. Our proposed method is compatible with all latent code embedding methods. Extension experiments demonstrate that our approach achieves state-of-the-art in real image inversion and editing. Code is available at https://github.com/caopulan/Domain-Specific_Hybrid_Refinement_Inversion.