 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
High-Fidelity Document Stain Removal via A Large-Scale Real-World Dataset and A Memory-Augmented Transformer
Oct 30, 2024
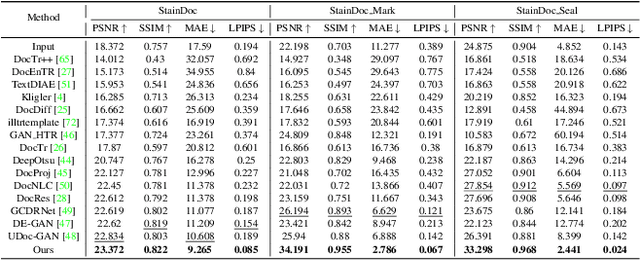


Document images are often degraded by various stains, significantly impacting their readability and hindering downstream applications such as document digitization and analysis. The absence of a comprehensive stained document dataset has limited the effectiveness of existing document enhancement methods in removing stains while preserving fine-grained details. To address this challenge, we construct StainDoc, the first large-scale, high-resolution ($2145\times2245$) dataset specifically designed for document stain removal. StainDoc comprises over 5,000 pairs of stained and clean document images across multiple scenes. This dataset encompasses a diverse range of stain types, severities, and document backgrounds, facilitating robust training and evaluation of document stain removal algorithms. Furthermore, we propose StainRestorer, a Transformer-based document stain removal approach. StainRestorer employs a memory-augmented Transformer architecture that captures hierarchical stain representations at part, instance, and semantic levels via the DocMemory module. The Stain Removal Transformer (SRTransformer) leverages these feature representations through a dual attention mechanism: an enhanced spatial attention with an expanded receptive field, and a channel attention captures channel-wise feature importance. This combination enables precise stain removal while preserving document content integrity. Extensive experiments demonstrate StainRestorer's superior performance over state-of-the-art methods on the StainDoc dataset and its variants StainDoc\_Mark and StainDoc\_Seal, establishing a new benchmark for document stain removal. Our work highlights the potential of memory-augmented Transformers for this task and contributes a valuable dataset to advance future research.
UV R-CNN: Stable and Efficient Dense Human Pose Estimation
Nov 04, 2022Dense pose estimation is a dense 3D prediction task for instance-level human analysis, aiming to map human pixels from an RGB image to a 3D surface of the human body. Due to a large amount of surface point regression, the training process appears to be easy to collapse compared to other region-based human instance analyzing tasks. By analyzing the loss formulation of the existing dense pose estimation model, we introduce a novel point regression loss function, named Dense Points} loss to stable the training progress, and a new balanced loss weighting strategy to handle the multi-task losses. With the above novelties, we propose a brand new architecture, named UV R-CNN. Without auxiliary supervision and external knowledge from other tasks, UV R-CNN can handle many complicated issues in dense pose model training progress, achieving 65.0% $AP_{gps}$ and 66.1% $AP_{gpsm}$ on the DensePose-COCO validation subset with ResNet-50-FPN feature extractor, competitive among the state-of-the-art dense human pose estimation methods.
TIVE: A Toolbox for Identifying Video Instance Segmentation Errors
Oct 17, 2022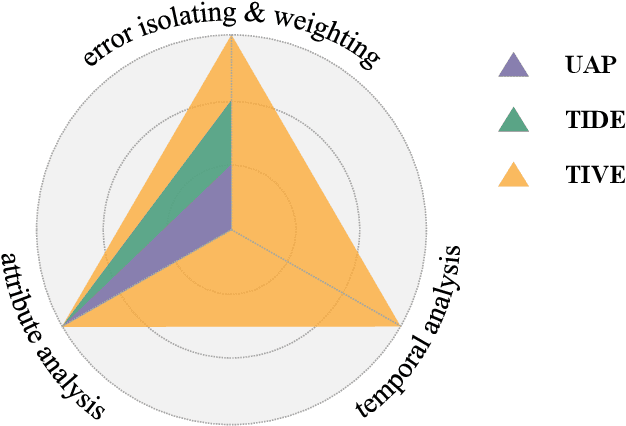
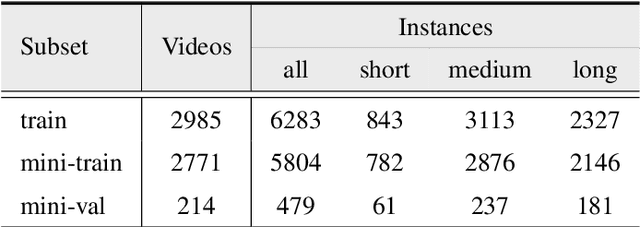
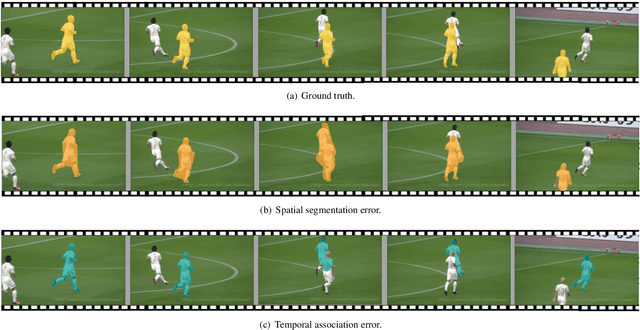
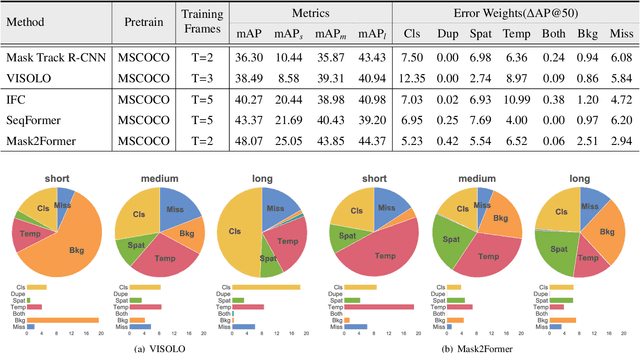
Since first proposed, Video Instance Segmentation(VIS) task has attracted vast researchers' focus on architecture modeling to boost performance. Though great advances achieved in online and offline paradigms, there are still insufficient means to identify model errors and distinguish discrepancies between methods, as well approaches that correctly reflect models' performance in recognizing object instances of various temporal lengths remain barely available. More importantly, as the fundamental model abilities demanded by the task, spatial segmentation and temporal association are still understudied in both evaluation and interaction mechanisms. In this paper, we introduce TIVE, a Toolbox for Identifying Video instance segmentation Errors. By directly operating output prediction files, TIVE defines isolated error types and weights each type's damage to mAP, for the purpose of distinguishing model characters. By decomposing localization quality in spatial-temporal dimensions, model's potential drawbacks on spatial segmentation and temporal association can be revealed. TIVE can also report mAP over instance temporal length for real applications. We conduct extensive experiments by the toolbox to further illustrate how spatial segmentation and temporal association affect each other. We expect the analysis of TIVE can give the researchers more insights, guiding the community to promote more meaningful explorations for video instance segmentation. The proposed toolbox is available at https://github.com/wenhe-jia/TIVE.